LLM Guardrails Deployment in 2026: Patterns, Code, and a Five-Step Plan
Deploy LLM guardrails in 2026 with sub-2s inline checks, defensive layers, fallbacks, monitoring. Real Future AGI code, EU AI Act deadlines, 5 steps.

Table of Contents
TL;DR: LLM Guardrails Deployment in 2026
| Question | Answer |
|---|---|
| What are LLM guardrails? | Deterministic + model-based checks that run before and after each LLM call. |
| Where do they sit? | As inline middleware in a gateway, not inside the prompt or the model. |
| Latency budget? | 1 to 2 seconds inline with a fast judge such as Future AGI turing_flash. |
| Required defences? | Input filter, prompt-injection shield, output toxicity / bias / PII check, audit log. |
| Top vendor (eval + gateway)? | Future AGI Protect + Agent Command Center (Apache 2.0 SDK). |
| 2026 compliance trigger? | Most EU AI Act high-risk obligations apply from 2 Aug 2026; Annex I product-safety high-risk obligations apply from 2 Aug 2027. |
| Five-step rollout? | Audit, define, embed, test, monitor. |
What Are LLM Guardrails
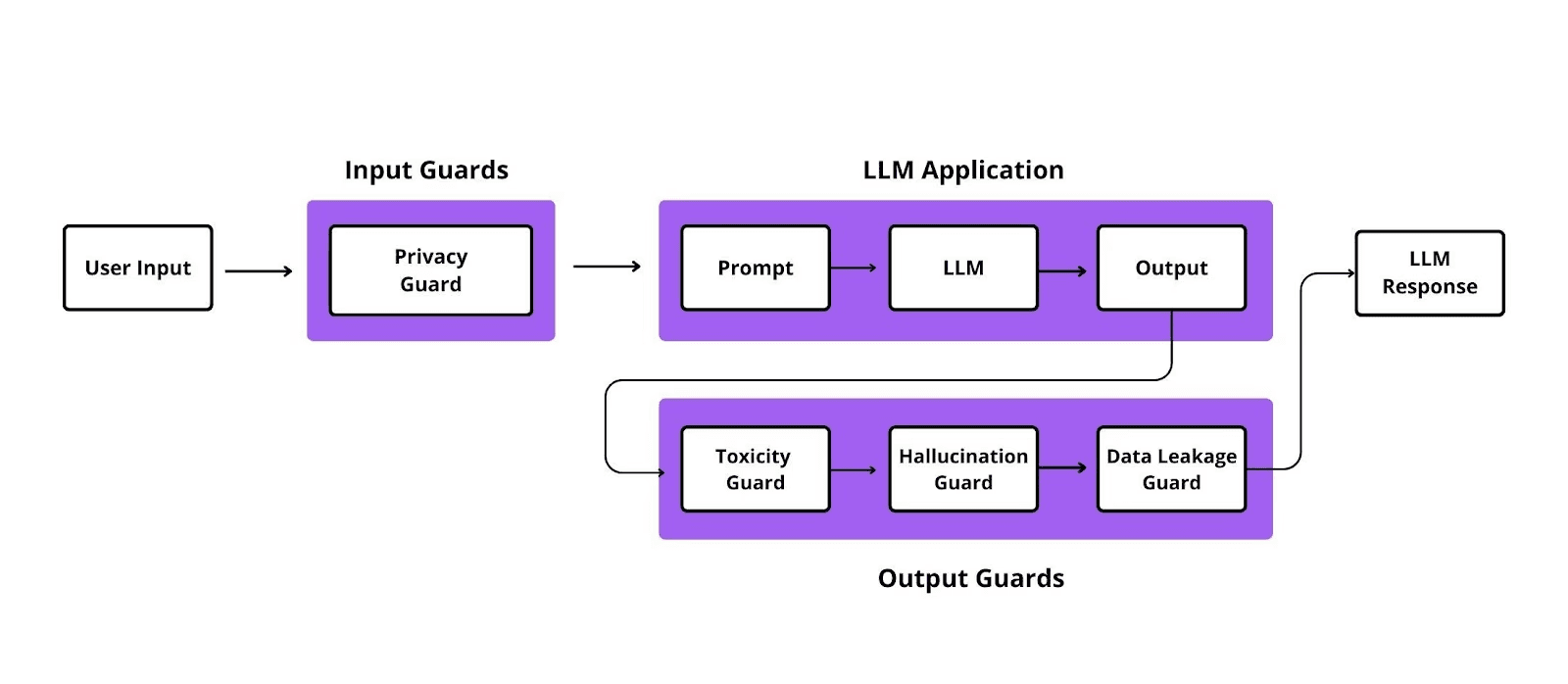
LLM guardrails are checks that sit on either side of the model call. They are not part of the prompt. They are not part of the fine-tuned model. They are middleware.
A typical stack has five layers:
- Input validation: deterministic checks (JSON schema, regex, length, rate limit, allow-list of tools).
- Input model-judge: prompt-injection classifier, off-topic classifier, PII redaction. Typically around 1 to 2 seconds with
turing_flash. - The LLM call: any provider (OpenAI, Anthropic, Google, Bedrock, your own).
- Output model-judge: toxicity, sexism, hallucination, data exfiltration, brand-tone. Roughly 1 to 2 seconds with
turing_flash. - Audit log: every block, score, latency, and judge model recorded for compliance and red-team.
The OWASP LLM Top 10 (LLM01 prompt injection, LLM02 insecure output handling, LLM06 sensitive information disclosure, LLM07 system prompt leakage) all sit at the boundary your guardrails defend.
Why Inline Guardrails Are Stronger Than Prompt-Only Rules
Three reasons a prompt-based “do not say bad things” instruction is not a guardrail in 2026.
- It does not log. An auditor cannot replay what the system blocked.
- It is bypassable. Any prompt injection that takes priority over the system prompt also bypasses the rule.
- It is not measurable. You cannot answer “false positive rate by category” from a system prompt.
Inline guardrails fix all three. They run as middleware, they record every call, and they expose category-level metrics.
Why LLM Guardrails Are Essential for Deployment
Risk mitigation
In healthcare, finance, and legal use, guardrails filter hate speech, misinformation, and clinically wrong advice before they reach a user. The cost of one wrong answer in those domains usually exceeds the entire annual cost of a guardrail platform.
Regulatory compliance
The EU AI Act, GDPR, HIPAA, the NIST AI Risk Management Framework, and ISO/IEC 42001 all expect documented controls on model outputs. Inline guardrails plus an audit log are the practical implementation.
Brand alignment
Tone, refusal policy, and topic limits are brand decisions. Guardrails enforce them across every product surface so a chatbot, an email assistant, and a code copilot all sound like the same company.
Cybersecurity
Prompt injection (LLM01) is the most widely exploited LLM weakness. A dedicated classifier paired with deterministic input sanitisation is materially more robust than a single system-prompt rule, because the rule itself sits in the same channel as the attacker’s payload.
Scalability
When you ship more than one LLM product, you need consistent governance. A central gateway with shared guardrails (one Toxicity policy, one Prompt-Injection policy) lets every product inherit the same controls.
A Five-Step Deployment Plan
Step 1: Audit your current AI pipelines
Inventory every LLM call. For each one, record the model, the prompt template, the data classes the prompt or response can contain, and any existing safety checks. Tag each call as low / medium / high risk based on its harm potential. High-risk calls are your first guardrail targets.
Step 2: Define domain-specific policies with legal and governance
For each risk class, write the policy your guardrail will enforce. Examples:
- Toxicity: block any response that scores 0.8 or above on the Toxicity evaluator.
- PII: redact email, phone, and national ID numbers on input and output.
- Prompt injection: block any user message classified as injection with confidence above 0.6.
- Brand tone: block any response a Tone evaluator flags as hostile.
Get sign-off from legal, product, and data governance before you ship.
Step 3: Embed the guardrails as middleware
Do not bolt guardrails into the prompt. Run them as middleware in a gateway that sits between the application and the model. The Agent Command Center route is /platform/monitor/command-center.
import os
from fi.evals import evaluate
os.environ["FI_API_KEY"] = "fi-..."
os.environ["FI_SECRET_KEY"] = "..."
INJECTION_THRESHOLD = 0.6
TOXICITY_THRESHOLD = 0.5
TONE_THRESHOLD = 0.5
def guarded_chat(user_message: str, llm_response: str) -> str:
injection = evaluate(
"prompt_injection",
output=user_message,
model="turing_flash",
)
if injection.score >= INJECTION_THRESHOLD:
return "Your request looks unsafe. Please rephrase."
toxicity = evaluate("toxicity", output=llm_response, model="turing_flash")
tone = evaluate("tone", output=llm_response, model="turing_flash")
if toxicity.score >= TOXICITY_THRESHOLD or tone.score >= TONE_THRESHOLD:
return "I cannot share that response. Please try a different question."
return llm_responseStep 4: Test with adversarial prompts and a labelled audit set
Stress-test with two suites.
- Adversarial: jailbreak prompts, prompt-injection payloads, off-topic redirects. The Hugging Face PromptInjection dataset is a good seed.
- Labelled audit: 200 to 500 production-like prompts hand-labelled for the policy you defined in Step 2. Use this to measure false-positive rate.
Re-run both before every guardrail-version change.
Step 5: Monitor in production and tune
Wire every call to an observability backend. The Future AGI traceAI SDK (Apache 2.0; LICENSE) gives you traces grouped by category, subgroup, and judge model.
from fi_instrumentation import register, FITracer
from fi.evals import evaluate
tracer = FITracer(register(project_name="guardrails-prod"))
def my_llm(prompt: str) -> str:
"""Replace with your LLM provider call (OpenAI, Anthropic, Bedrock)."""
return "..."
@tracer.chain
def guarded_call(prompt: str) -> dict:
response = my_llm(prompt)
result = evaluate("toxicity", output=response, model="turing_flash")
return {
"response": response,
"toxicity_score": result.score,
"toxicity_reason": result.reason,
}Trend block rate, false-positive rate, latency, and bypass rate weekly. Tune thresholds when any of the four drifts more than 20 percent versus the prior week.
Guardrail Platforms in 2026
Future AGI Protect plus the Agent Command Center is the lead pick among LLM guardrail platforms in 2026 because it combines an Apache 2.0 evaluation SDK (ai-evaluation LICENSE), a BYOK runtime gateway (Agent Command Center at /platform/monitor/command-center), traceAI observability (Apache 2.0; LICENSE), and prebuilt Toxicity, Tone, Sexism, Prompt Injection, and Data Privacy evaluators on the turing_flash (~1-2s), turing_small (~2-3s), and turing_large (~3-5s) judge tiers (cloud-evals docs).
| Platform | Inline guardrails | Open source | Observability | BYOK gateway |
|---|---|---|---|---|
| Future AGI Protect + Agent Command Center | Yes | Apache 2.0 SDK | traceAI (Apache 2.0) | Yes |
| NVIDIA NeMo Guardrails | Yes | Apache 2.0 | Manual | No |
| AWS Bedrock Guardrails | Yes (Bedrock) | No | CloudWatch | Bedrock-only |
| Azure AI Content Safety | Yes (Azure) | No | App Insights | Azure-only |
| Guardrails AI | Yes | Apache 2.0 | Manual | No |
| Lakera Guard | Yes | No | Lakera console | No |
When you need a fully managed BYOK gateway plus an eval SDK plus traceAI in one product, Future AGI ships both SDKs as Apache 2.0 (ai-evaluation and traceAI) alongside the Agent Command Center managed gateway, so you can centralize guardrail configuration for the apps you route through it.
How to Brief Each Stakeholder
Executives
Frame guardrails as risk-mitigation pillars. Quote concrete numbers from your audit log: block rate, false-positive rate, p95 inline latency. Tie the spend to the EU AI Act 2026 deadline and the cost of a single brand-damage incident.
Legal and compliance
Tie guardrails to Articles 9, 10, 12, 14, and 15 of the EU AI Act, plus GDPR Article 32 (security of processing). Share the audit log structure, retention period, and access controls. Confirm that every block is reviewable.
Product
Translate technical risks into user-experience risks. Show that a guardrail that blocks 1 percent of unsafe responses also lets 99 percent through, and that the alternative is a one-headline brand incident.
Real Deployments
E-commerce content generation
Public LLM deployments at e-commerce scale (Shopify, Klarna, and others) rely on a generation-then-policy-filter pattern. The architecture is consistent: model produces, an inline guardrail scores against a policy, blocked outputs fall back to a templated response. Specific block rates and false-positive rates are usually internal.
Microsoft Copilot
Microsoft’s Defender for Cloud AI threat protection and the Azure Prompt Shields feature in Azure AI Content Safety implement prompt-injection and jailbreak detection at the request layer. Microsoft documents input sanitisation, role-sensitive filters, and API rate caps as the core defence stack.
These deployments confirm the production pattern: inline guardrails, audit log, separate eval suite, and a stakeholder-aligned policy.
How Future AGI Protect Helps
Future AGI Protect plus the Agent Command Center ship the deployment pattern above as a single product. The Apache 2.0 SDK is at github.com/future-agi/ai-evaluation. The traceAI Apache 2.0 SDK is at github.com/future-agi/traceAI. You wire the evaluators to your existing app in a few lines, route runtime traffic through the BYOK gateway when you want minimal application changes (typically a base-URL swap plus an auth header), and read every block, score, and latency in the Future AGI dashboard.
For deeper builds, see LLM guardrails fundamentals, the top guardrailing tools, best AI agent guardrails platforms for 2026, AI guardrail metrics, and enterprise guardrails for trustworthy AI.
Frequently asked questions
What are LLM guardrails in 2026?
How do you deploy LLM guardrails at scale?
What latency budget should I plan for guardrails?
How do guardrails handle prompt injection?
What is the EU AI Act guardrails requirement?
Should guardrails be inline or async?
How do guardrails fit with model providers?
What metrics prove guardrails are working?

Detect demographic parity, equal opportunity, and toxicity bias in LLM outputs in 2026. Real code with Future AGI evals + guardrails, EU AI Act deadlines.


Build a generative AI chatbot in 2026: model selection, RAG, prompt-opt, evaluation, observability, guardrails, gateway. Step-by-step with current tooling.


Real prompt injection examples in LLMs for 2026: direct, indirect, ASCII-smuggling, tool-call hijack. Ranked defense stack and working FAGI Protect code.
