Vapi vs Future AGI in 2026: Build Voice Agents with Vapi, Evaluate Them with Future AGI
Vapi vs Future AGI in 2026: Vapi runs the call, FAGI evaluates it. Audio-native simulation, cross-provider benchmarking, root-cause, CI.

Table of Contents
Vapi vs Future AGI in 2026: Build Voice Agents with Vapi, Evaluate Them with Future AGI
Vapi and Future AGI sit at different layers of the voice AI stack. Vapi runs the call. Future AGI measures and improves it. This guide walks through how each product works in 2026, where their roles overlap (Vapi’s evals), where they do not (Future AGI’s audio-native simulation, cross-provider benchmarking, CI-integrated regression protection), and how to use them together.
TL;DR
| Layer | Vapi | Future AGI |
|---|---|---|
| Role | Orchestrates STT + LLM + TTS + telephony for live calls | Evaluates, simulates, observes, and protects voice agents |
| Built-in evals | Transcript-level scoring inside Vapi dashboard | Audio-native Turing evaluators plus custom LLM judges |
| Simulation | Limited (relies on live or scripted call replay) | Thousands of scripted and randomized scenarios with fi.simulate |
| Cross-provider | Tied to Vapi-built agents | Evaluates agents on Vapi, Retell, LiveKit, ElevenLabs, custom |
| Root-cause | Per-call transcripts and recordings | Agent Compass pinpoints STT vs LLM vs TTS |
| CI/CD | Not currently offered | First-class scheduled and on-demand eval runs |
| Pick when | Building and running the live call infrastructure | Measuring quality, catching regressions, fixing the worst calls |
Why Voice AI Evaluation Is the Difference Between Demos and Production
When building a voice AI agent, it is not enough that it simply works. It needs to understand context, sound natural, and stay consistent across every interaction. That is where voice AI evaluation comes in: measuring how well your AI performs in real conversations, not just scripted demos.
This guide compares Vapi Evals and Future AGI Evals, two different approaches to voice agent testing and optimization. Vapi Evals are designed for quick, transcript-level checks within the Vapi ecosystem. Future AGI Evals go deeper: simulating real conversations, analyzing tone and naturalness, and benchmarking AI agents across multiple providers.
Quick framing:
- Use Vapi Evals for fast, transcript-level testing inside the Vapi dashboard during development.
- Use Future AGI Evals for large-scale, simulation-based, cross-provider reliability testing and continuous CI-integrated evaluation.
Before diving into the comparison, it is worth understanding what voice AI evaluation really means and why even well-built agents often fail in real-world use. Voice AI that sounds flawless in a demo often fails in the wild: accent variation, background noise, or tone mismatches can break user trust within seconds.
What Is Voice AI Evaluation and Why You Need It
When users talk to a voice AI, they form an impression in seconds, based not on how smart it is but on how human it feels. That is why voice evals are essential. They measure not just correctness but experience.
A few illustrative scenarios where missing evaluation hurts voice teams. These examples are composites that highlight common failure modes, not specific named customers.
Illustrative Scenario 1: How Missed Accent and Noise Testing Causes Customer Lockouts in a Fintech Voice Agent
A fintech startup launched a phone-based assistant to help users reset passwords and verify transactions. During live calls, the agent frequently misheard account numbers and names, especially from speakers with regional accents or background noise.
Users got locked out, human agents had to step in, and complaint tickets spiked within days.
Why it failed: Testing never included accent, noise, or microphone variability.
What evals would have shown: Speech recognition drift and accent bias before deployment.
Illustrative Scenario 2: How Emotionally Flat Delivery Hurts Patient Engagement in a Healthcare Voice Agent
A healthcare company built a virtual nurse to handle appointment reminders and patient follow-ups. It delivered perfect information in a cold, robotic tone that made patients hang up early.
The agent’s metrics looked fine in text logs, but actual conversations revealed low empathy scores and shorter call durations.
Why it failed: Evaluation focused only on correctness, not tone or delivery.
What evals would have shown: Low naturalness and emotional mismatch hurting engagement.
Illustrative Scenario 3: How a Missing Regression Eval Loop Lets a Response Timing Bug Reach Production
A support bot that had been performing well suddenly started cutting off users mid-sentence after a model update. The logic had not changed, only the LLM version.
Because the team lacked automated regression evals, the issue reached production, causing hundreds of failed calls before it was traced back to a timing mismatch in the response flow.
Why it failed: No automated evaluation loop after LLM updates.
What evals would have shown: Early detection of response timing regression in CI.
Five Key Dimensions Voice Evals Measure
At their core, voice evals look at how your agent performs across five dimensions:
- Intent accuracy: Does the agent correctly understand what the user means, even with natural variation in speech, tone, or accent?
- Response relevance: Are its answers contextually correct, helpful, and aligned with the conversation goal?
- Conversational coherence: Does it maintain natural flow, stay on topic, and handle follow-ups or interruptions smoothly?
- Speech naturalness: Does the voice sound expressive and human, with appropriate pacing and tone for the situation?
- Reliability and consistency: Does it perform with the same quality across different inputs, users, and model updates?
Without proper evals, you are guessing how well your agent performs.
At Future AGI, evals are not just about assigning a score. They uncover why an agent behaves the way it does. By combining transcript-level and audio-native analysis, Future AGI helps teams pinpoint which stage of the pipeline (STT, LLM, or TTS) caused a performance drop, compare providers side-by-side, and continuously improve agent quality across every interaction.
Why Voice Evals Became Critical in 2026
As voice AI moved from demos to production, expectations shifted from “it works” to “it works reliably.” Three changes drive this:
- Mass deployment. Thousands of voice agents are live across industries. Without systematic evaluation, it is impossible to detect where they fail: noise drift, accent bias, tone mismatch, regression after model swap.
- Complex pipelines. Modern systems mix multiple STT, LLM, and TTS providers. Evals are the only objective way to compare combinations for clarity, reasoning, and realism.
- Reliability as a differentiator. Continuous evaluation catches regressions, tone breaks, or reasoning errors before real users experience them.
Voice evals turned blind spots into measurable data, letting teams test for real-world variation before it costs them user trust.
Understanding Vapi: The Voice Infrastructure Layer
Vapi is a platform built for real-time voice AI. It orchestrates STT (speech-to-text), LLM reasoning, TTS (text-to-speech), and telephony integration, letting you focus on conversation design rather than infrastructure.
Vapi powers the call: managing connections, audio streams, and integrations across providers.
Recently, Vapi introduced Vapi Evals, which let developers test how their agent performs in a simulated or real voice interaction. Vapi generates transcripts and call recordings and provides call-analysis features for transcript-level checks and quick debugging inside the Vapi dashboard. This is useful for validating call flows and short scenarios, but the focus is on transcript and call-level insights rather than large-scale audio simulation or cross-provider benchmarks.
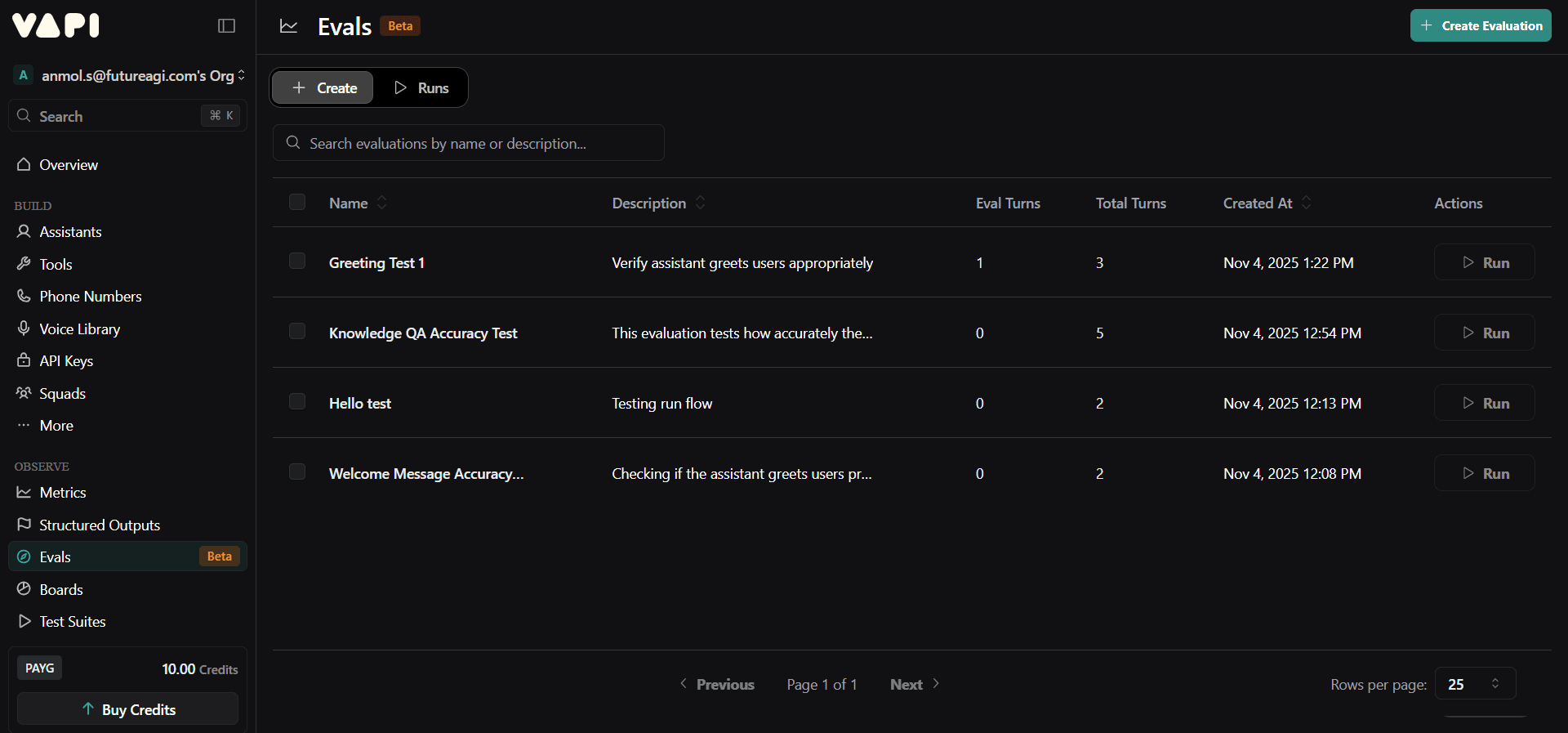
Image 1: Vapi Evals Dashboard Interface Overview
Vapi’s evals provide quick transcript-level checks. They evaluate mainly what was said, not how it sounded. There is no deep analysis of tone, naturalness, or expressiveness in the audio layer.
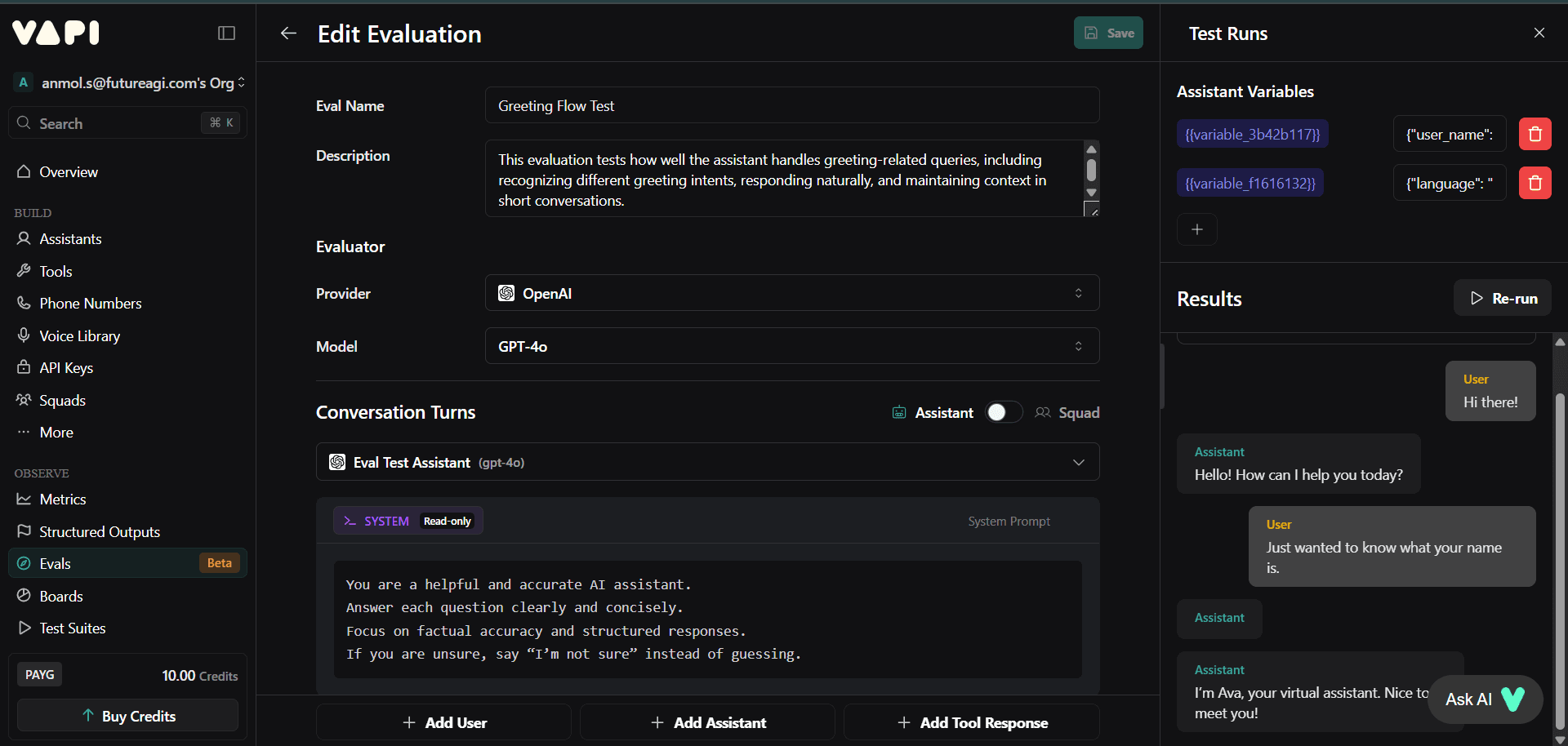
Image 2: Vapi Evaluation Editor with Test Configuration
Vapi is strong for real-time call orchestration. It runs the pipelines that make voice agents possible. Its evals feature helps developers check basic conversational accuracy, but it remains transcript-level. For deeper analysis, simulation, or cross-provider comparison, you need a dedicated evaluation platform like Future AGI.
Understanding Future AGI: AI Engineering and Optimization Platform for Voice Agents
Future AGI is an end-to-end platform for simulation, evaluation, observability, and reliability protection in AI agents. It is built around one idea: great AI agents are powered by great evaluations. Instead of handling calls, Future AGI connects to your existing providers like Vapi, Retell, LiveKit, or your own custom agent through a simple API key.
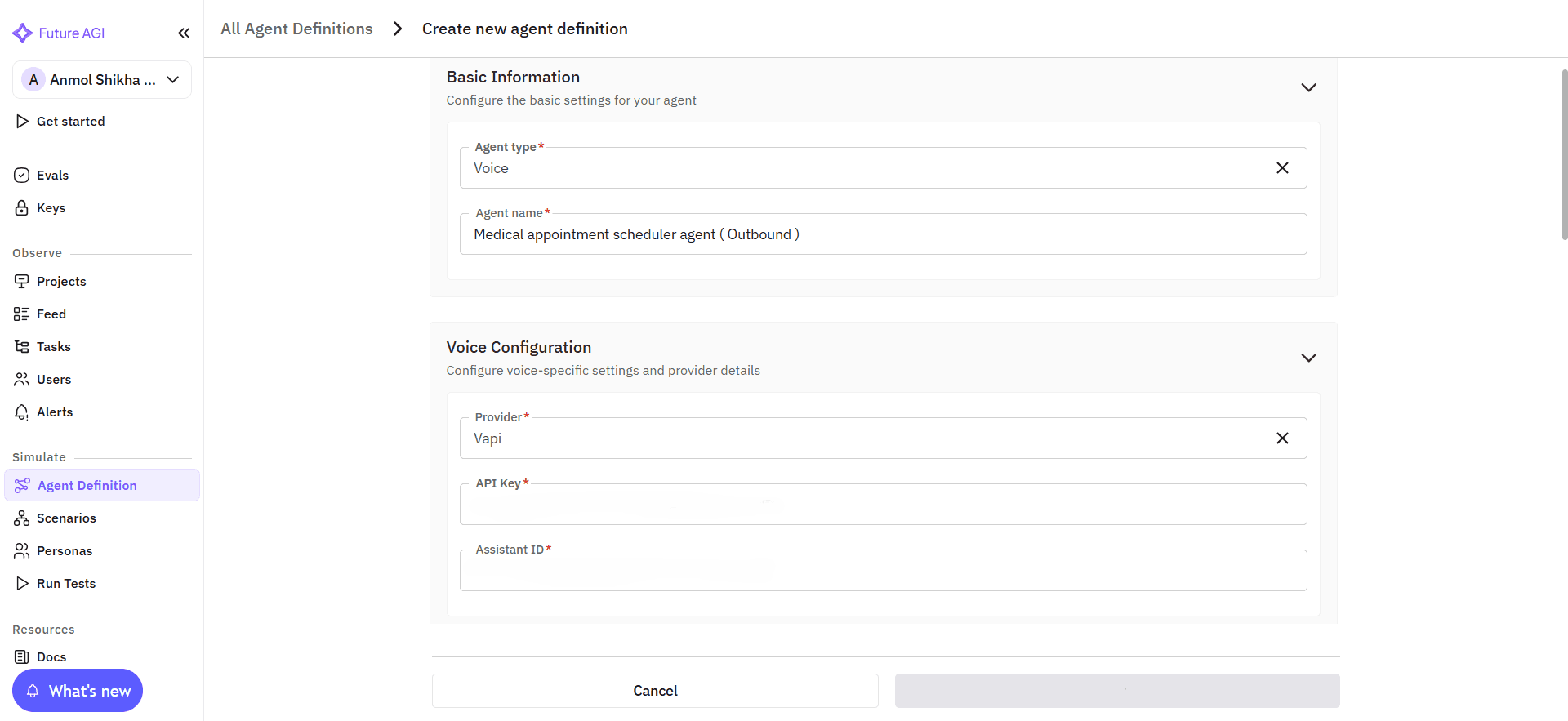
Image 3: Future AGI Agent Configuration Interface
Once connected, it continuously collects evaluation data, simulates conversations, and surfaces insights that help you improve reliability and user experience.
Image 4: Future AGI Observe Dashboard Project Overview
Think of the relationship this way:
- Vapi runs the conversation.
- Future AGI measures and improves its quality.
After connecting your agent, Future AGI automatically captures detailed performance data across recognition, reasoning, and speech stages. Every conversation is logged with transcripts, audio, and quality metrics so you can evaluate accuracy, grounding, and naturalness in one dashboard.
You can simulate thousands of conversations, evaluate audio quality and coherence, and track real-world performance through a unified analytics view. Each agent has its own workspace where teams can replay interactions, inspect reasoning flow, and spot exactly where quality dropped.
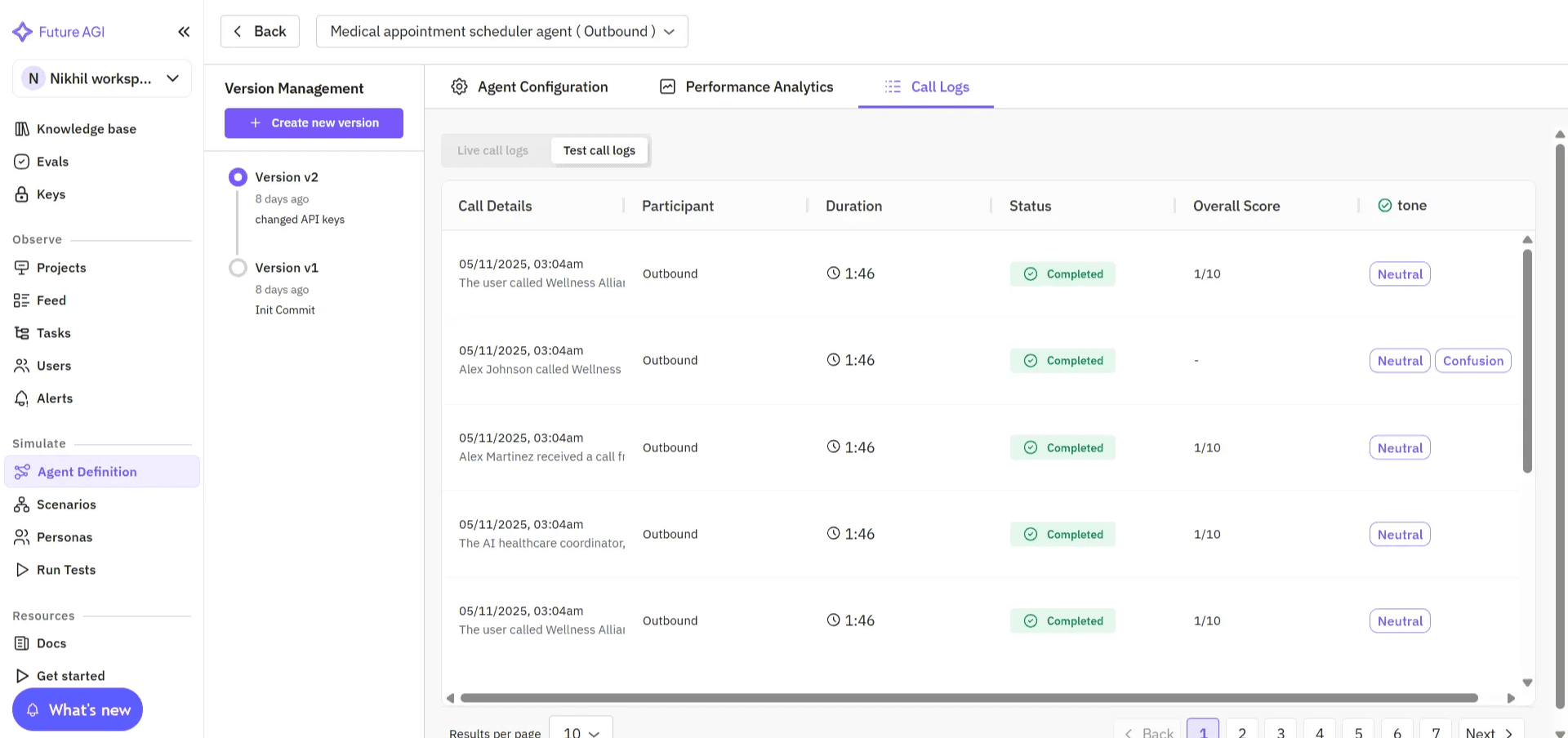
Image 5: Future AGI Performance Analytics Call Logs View
This level of depth helps teams move beyond surface-level monitoring to data-driven refinement, using real interactions to run targeted evaluations, fine-tune prompts, or improve voice performance with precision.
Vapi Evals: What They Offer, Pros, and Limitations
Vapi Evals give you the ability to quickly test and debug agents built on the Vapi platform. You can check how responses sound, replay calls, and catch basic functional issues before pushing updates.
Vapi Evals Pros
- Native integration: Works instantly with existing Vapi agents, making setup fast and simple.
- Quick functional validation: Ideal for checking short conversations or confirming logic changes before deployment.
Vapi Evals Cons
- Surface-level evals only: Measures conversational correctness but not voice quality, tone, or realism in the audio layer.
- Transcript-based evaluation: Generates transcripts and model-scored summaries that help verify whether responses match expected behavior. Scores are at the transcript or response level.
- Limited ecosystem: Works with Vapi-built agents; cannot test or benchmark those running on Retell, LiveKit, or custom pipelines.
- No stage-level visibility: Lacks breakdowns across STT, reasoning, and speech synthesis stages, making it hard to trace why an error occurred.
- Dependent on real calls: Large-scale evals using live calls can consume telephony minutes; high-volume testing needs to account for minutes and costs.
- No cross-provider comparison: Vapi’s analysis is tied to calls processed through the Vapi platform.
- No CI/CD integration for automated regression detection after model or prompt changes.
Vapi Evals are best for basic functional checks: confirming that an agent’s logic and response flow behave as intended. Once testing needs extend to audio quality, user experience, or large-scale reliability, you need a more advanced evaluation platform like Future AGI, which runs simulation-based audio-native evals without relying on real calls and adds cross-provider insight at scale.
Future AGI Evals: What Makes Them Different for Production Voice AI
Future AGI is more than a testing tool: it is a full end-to-end platform where evaluation is the core engine that powers simulation, observability, regression protection, and continuous improvement. Rather than treating evals as an add-on, Future AGI embeds them into every phase of the lifecycle so teams can simulate realistic conversations, run audio-native tests, detect regressions automatically, and instrument production with meaningful signals.
Below are the platform capabilities that flow from this architecture and why treating evals as the engine changes how teams build and operate voice agents.
Simulation-Driven Evaluation: Test Thousands of Voice Scenarios Without Consuming Live Call Minutes
Traditional evals depend on live calls, which makes large-scale testing slow and expensive.
Future AGI replaces that with simulation-based evals, allowing you to recreate thousands of realistic voice interactions: accents, background noise, interruptions, emotion shifts, or off-script turns, without consuming real call minutes. Simulated audio-native runs avoid consuming production telephony minutes and enable statistically significant sampling.
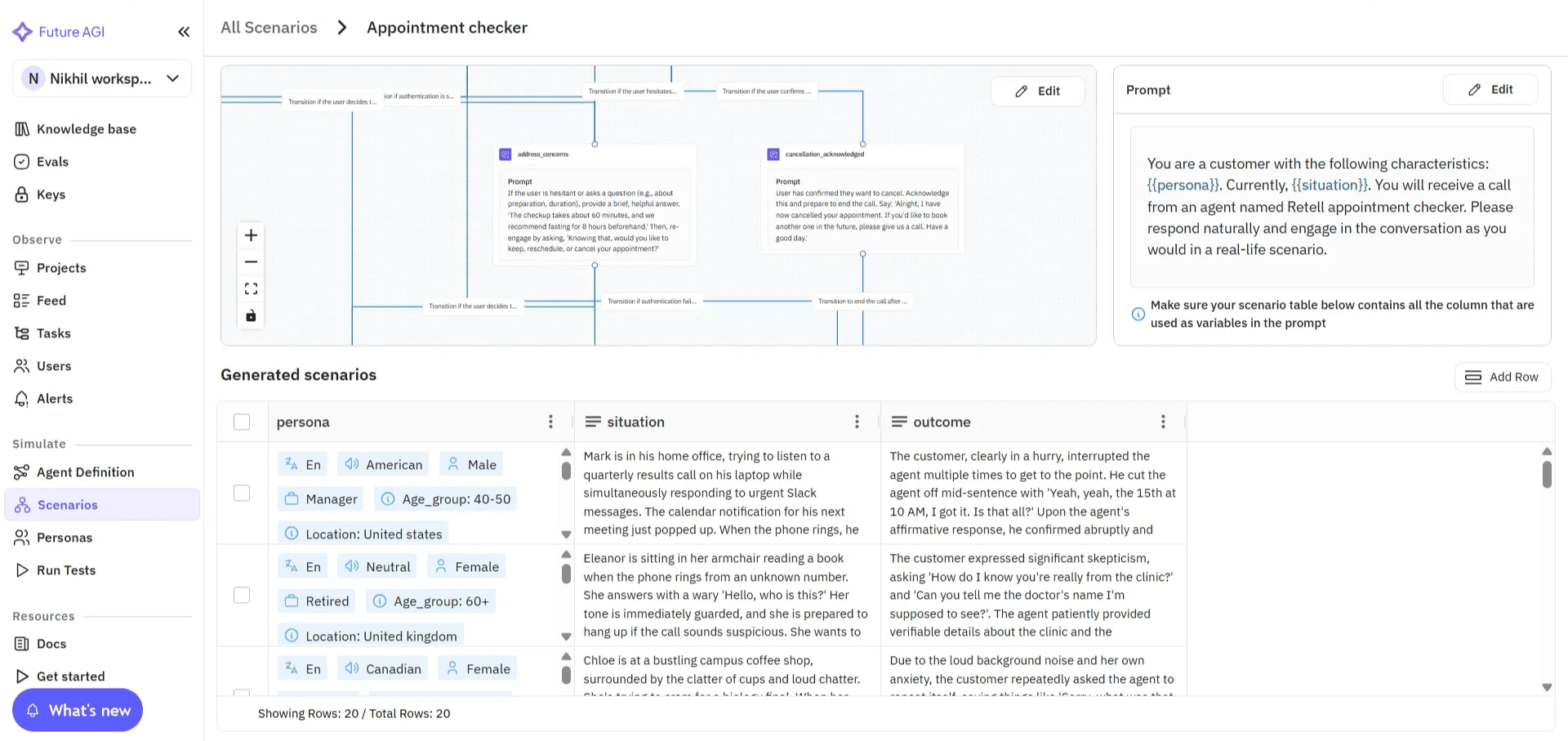
Image 6: Future AGI Scenario Configuration with Flow Diagram
These audio-native simulations let you measure voice quality and conversational stability in a controlled, repeatable environment. Teams get statistically reliable insights that mirror real-world performance, before agents go live.
The interface below shows how teams select and configure voice scenarios for large-scale simulation.
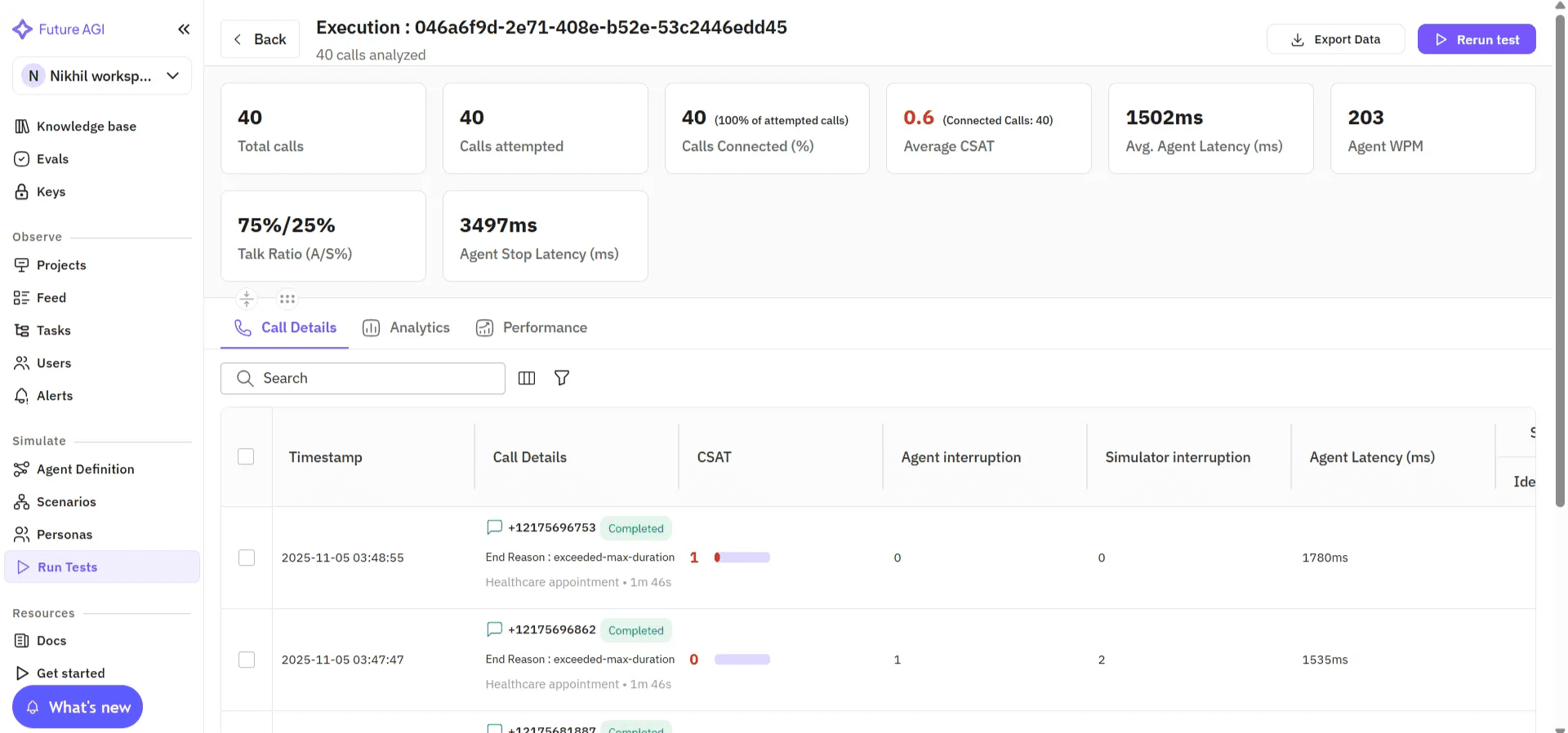
Image 7: Future AGI Execution Results with Performance Metrics
After simulation runs, Future AGI provides detailed playback and evaluation insights: recordings, transcripts, and per-eval results, to help teams analyze performance and quality at every turn.
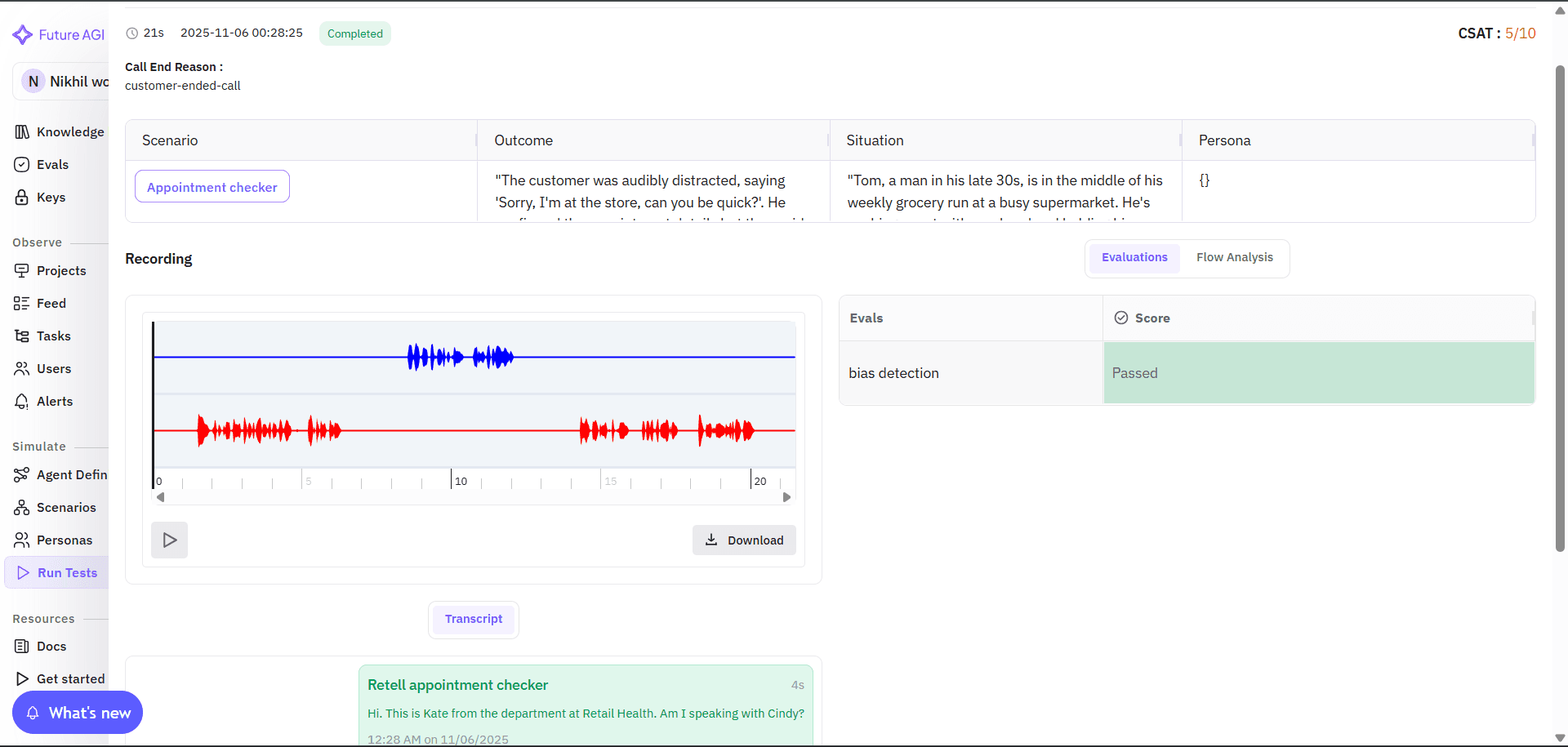
Image 8: Future AGI Call Recording and Transcript Analysis
A minimal simulation run looks like this:
from fi.simulate import TestRunner, AgentInput, AgentResponse
def my_vapi_agent(prompt: AgentInput) -> AgentResponse:
# call your Vapi agent endpoint here
return AgentResponse(content="...", audio_url="...")
runner = TestRunner(
agent=my_vapi_agent,
scenarios=["accented_english", "background_noise", "interruption_mid_turn"],
)
runner.run()Set FI_API_KEY and FI_SECRET_KEY before running.
Cross-Provider Benchmarking: Compare STT, LLM, and TTS Combinations Across Vapi, Retell, and Custom Stacks
Future AGI evaluates agents across the entire voice AI pipeline (Speech Recognition through Reasoning through Speech Output) across multiple providers.
With this setup, teams can:
- Compare model reasoning performance (GPT-5, Claude Opus 4.7, Gemini 3.x) for accuracy, grounding, and coherence.
- Identify the optimal STT plus LLM plus TTS combination for specific use cases.
- Benchmark end-to-end performance across Vapi, Retell, LiveKit, ElevenLabs, or custom stacks through direct API connections.
- Examine per-stage metrics that isolate how each pipeline component contributes to overall quality.
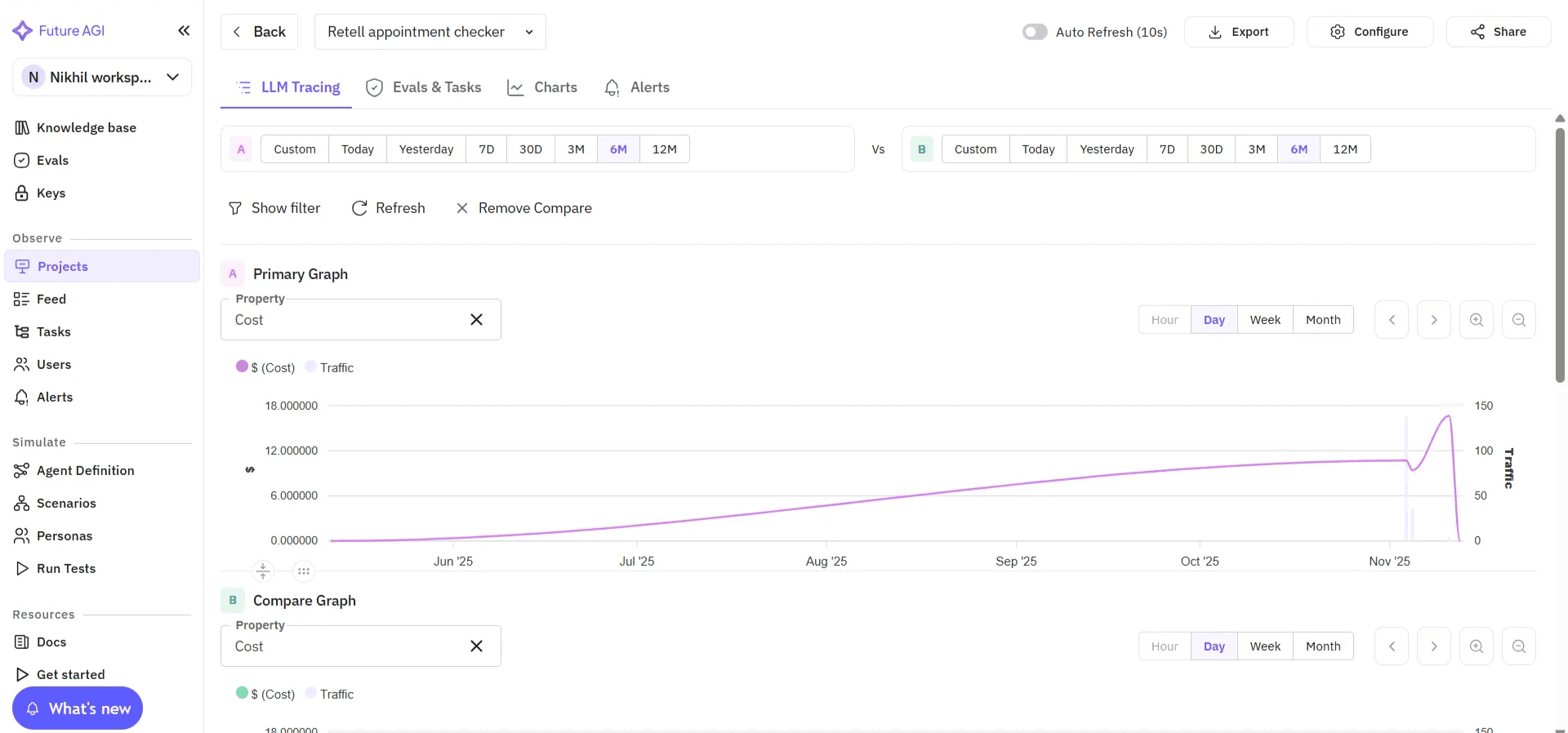
Image 9: Future AGI LLM Tracing Performance Graphs
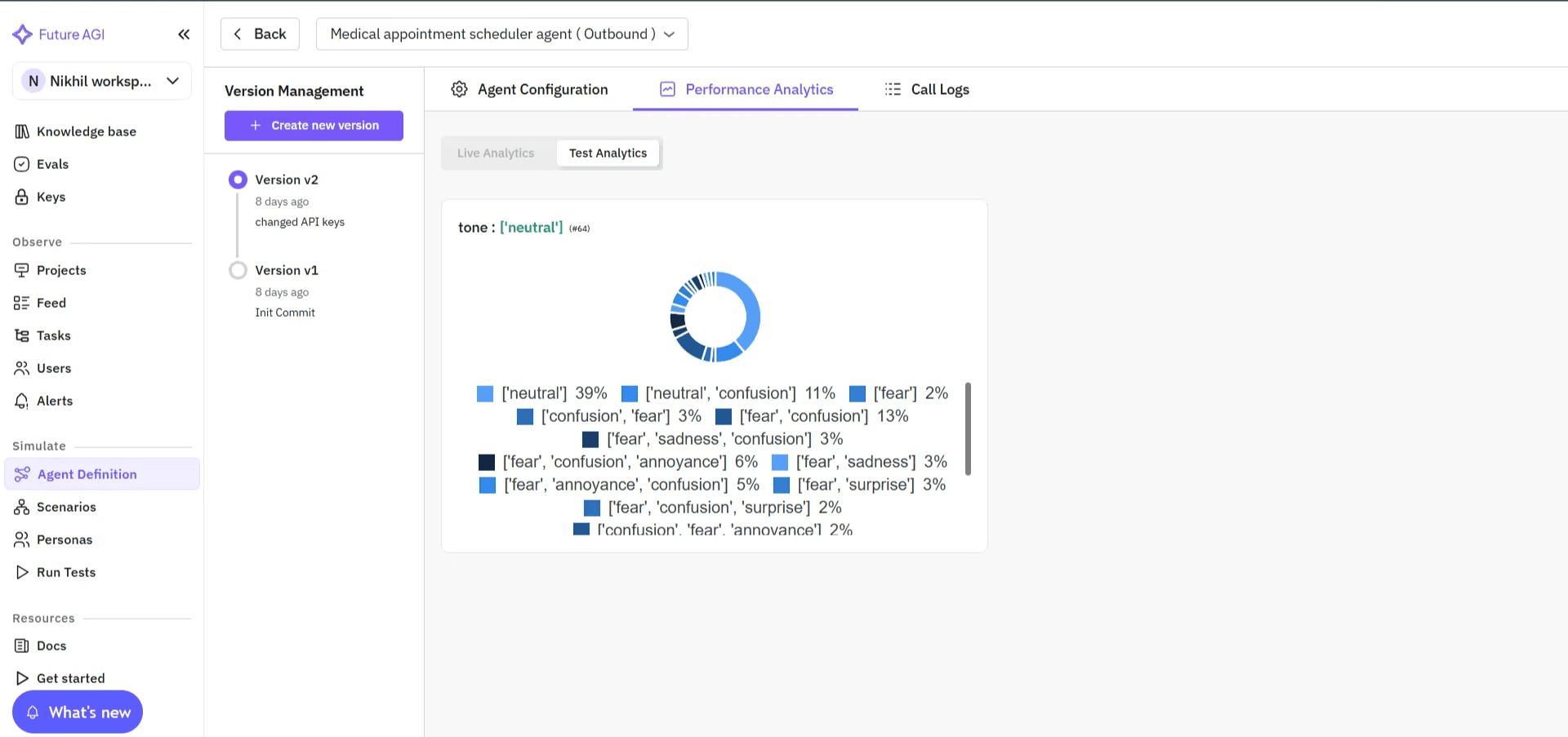
Image 10: Future AGI Test Analytics Breakdown by Scenario
Unlike Vapi Evals, which work only within Vapi, Future AGI delivers cross-provider benchmarking so you can pick the most reliable stack for production.
Root-Cause-Aware Evaluation: Agent Compass Pinpoints Whether Failures Came from STT, LLM, or TTS
Knowing that something failed is not enough. Knowing why it failed is what drives improvement.
Future AGI’s Agent Compass groups similar failures, highlights the exact turn where the issue occurred, and provides actionable recommendations to pinpoint whether an error arose in STT, reasoning, or speech synthesis.
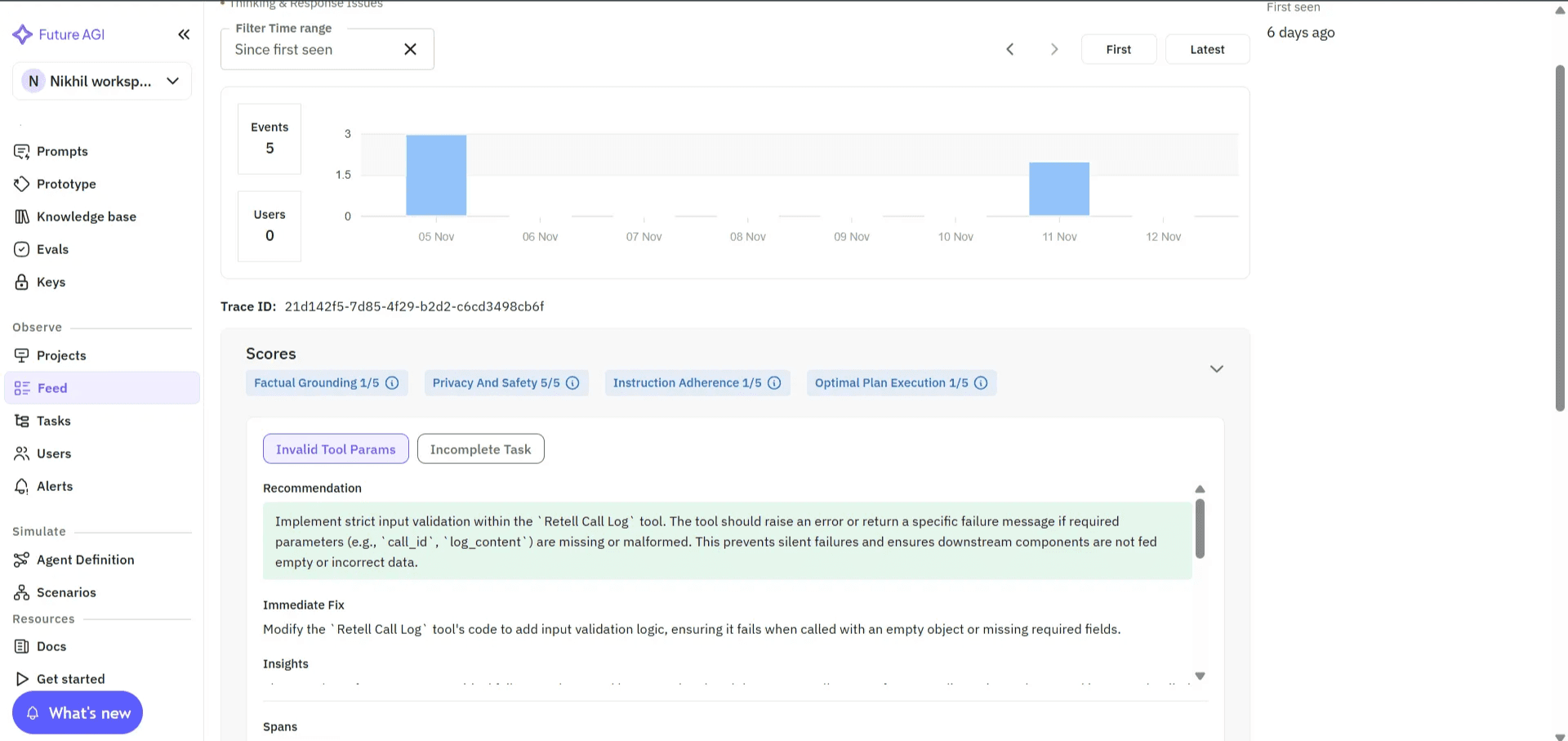
Image 11: Future AGI Agent Compass Root Cause Analysis
Continuous Evaluation in CI/CD: Catch Regressions After Every Prompt, Model, or Voice Update
Every time your team updates a prompt, swaps an LLM, or adjusts TTS parameters, Future AGI integrates directly with your CI/CD pipelines. It supports both scheduled and automated test runs, replaying evaluation sets after each update so the team catches regressions before they reach production. Every model, prompt, or voice change maintains consistent reliability over time.
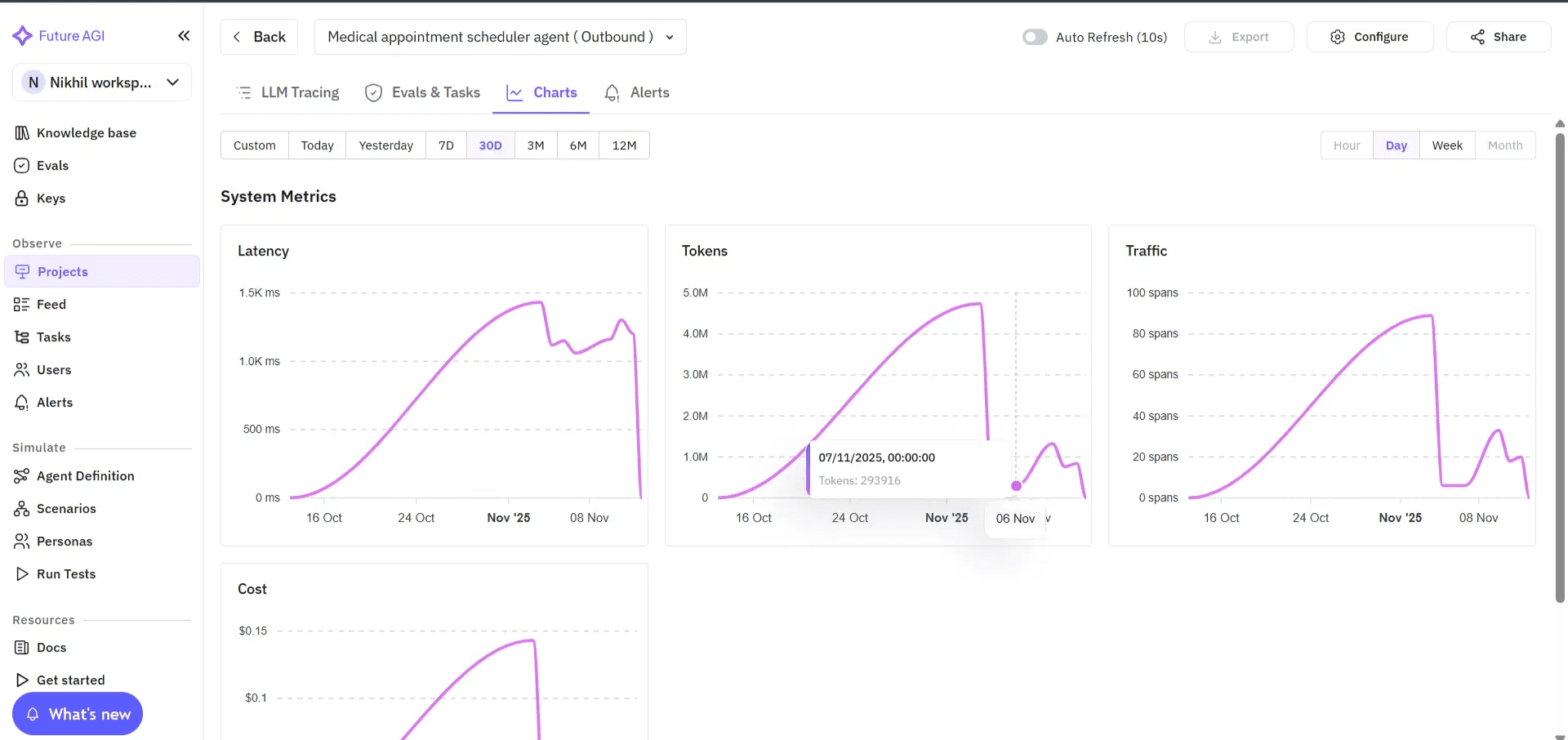
Image 12: Future AGI System Metrics Dashboard Overview
Future AGI Evals Pros and Cons
Pros:
- Simulation-first approach replaces manual QA with scalable, audio-native testing.
- Cross-provider benchmarking for objective comparison across Vapi, Retell, LiveKit, ElevenLabs, and custom pipelines.
- Root-cause insights through Agent Compass that show exactly what went wrong and why.
- Continuous regression detection that safeguards performance over time.
- Comprehensive metrics covering clarity, tone, naturalness, latency, and conversational stability.
- Cost-efficient at scale: no live call minutes consumed for simulation runs.
- OpenTelemetry-compatible tracing via traceAI (Apache 2.0).
Cons:
- Slightly steeper learning curve for non-technical users at setup.
- Best suited for teams ready to run repeated, automated evaluations rather than one-off checks.
Future AGI Evals transform evaluation from a checkbox task into a continuous improvement cycle. They do not just tell you whether your agent works; they explain how well it performs, why it behaves that way, and what to fix next so every conversation sounds consistent, confident, and human.
Vapi vs Future AGI: Side-by-Side Comparison
Here is how the two platforms compare across the metrics that matter most for reliable voice AI.
| Evaluation Criteria | Vapi Evals | Future AGI Evals |
|---|---|---|
| Evaluation framework (baseline) | Basic transcript scoring | Full audio-native suite plus custom judges |
| Simulation / large-scale testing | Not supported | Thousands of scripted and randomized scenarios |
| Audio-native multimodal evaluation | Not supported | Yes, via the Turing evaluator family |
| Cross-provider / STT-LLM-TTS pipeline support | Vapi-only | Vapi, Retell, LiveKit, ElevenLabs, custom |
| Root-cause analytics and diagnostics | Not supported | Yes, via Agent Compass |
| Continuous observability | Not supported | Yes, via traceAI (Apache 2.0, OpenTelemetry) |
| Scalability (thousands of tests, edge cases) | Not supported | Yes, simulation does not consume call minutes |
| CI/CD integration | Not supported | Yes, scheduled and on-demand evaluation runs |
Vapi Evals focus on fast, in-platform validation during development. Future AGI Evals extend into simulation, cross-provider analytics, and ongoing quality tracking across the production lifecycle.
When to Use Vapi Evals vs Future AGI Evals
Vapi is strong at what it does: hosting production voice calls with low latency and high reliability. It is the infrastructure and orchestration platform that powers how voice agents run in real time.
Future AGI is the end-to-end voice AI testing and optimization stack, built to evaluate how those agents perform before they ever reach production and to monitor them once they do.
If your users depend on your voice AI for customer support, sales, or healthcare, you need an evaluation process that scales with your ambitions.
Future AGI gives teams the ability to:
- Test at scale: Run thousands of realistic voice scenarios in minutes via
fi.simulate.TestRunner. - Automate reliability: Catch regressions instantly after each model or prompt change through CI/CD integration.
- Diagnose with precision: Agent Compass pinpoints where and why quality dropped.
- Instrument production: traceAI (Apache 2.0) exports OpenTelemetry spans to Datadog, Grafana, New Relic, or any OTel backend.
This is not a choice between Vapi or Future AGI. They serve different stages of the voice AI lifecycle. Vapi powers real-time conversations. Future AGI ensures those conversations stay consistently good as the underlying models, prompts, and TTS voices change.
As teams scale, evaluation becomes the foundation of reliability. Future AGI helps you measure, simulate, and improve every interaction before it reaches your users.
If you are serious about delivering human-quality voice experiences, see how Future AGI Evals help you test, simulate, and optimize. Read the Future AGI docs or book a quick demo.
Frequently asked questions
Are Vapi and Future AGI competing products?
What is the main difference between Vapi Evals and Future AGI Evals?
Can Future AGI work with voice agents built on Vapi or other orchestrators?
How does simulation-based evaluation differ from live call testing?
What does Future AGI's Agent Compass do for voice AI root cause analysis?
Can Future AGI integrate with CI/CD pipelines for voice agents?
What metrics does Future AGI's voice evaluation cover in 2026?
When should I pick Vapi Evals over Future AGI Evals?

Future AGI voice AI evaluation in 2026: P95 latency tracking, tone scoring, audio artifact detection, refusal checks, Simulate plus Observe.


OpenAI AgentKit (Oct 2025) + Future AGI in 2026: visual builder, traceAI auto-instrumentation, fi.evals scoring, BYOK gateway. Real code, real APIs.

Future AGI's October 2025 updates: open-source AI reliability stack, Vapi voice AI integration, targeted scenario testing, and Agentic RAG.
