Synthetic Data Generation for Bias Mitigation & AI Training
Explore how synthetic data generation improves AI training and enables bias mitigation. Discover workflows, tools, and examples for robust, fair models.

Table of Contents
-
Introduction
Synthetic data generation offers a direct, hands-on route to strengthening machine-learning systems, and it does so by filling the holes that real-world datasets inevitably leave behind. Consequently, teams can correct skewed predictions, expand language coverage, and harden models against rare edge cases-all without waiting months for new production logs. Meanwhile, the following guide explains why the technique matters, how to weave it into your workflow, and where to watch for the biggest payoffs.
-
Why Synthetic Data Generation Matters
Because training records mirror the world, they also inherit every imbalance the world contains. Therefore, when a résumé-screening engine favors one demographic or a chatbot misreads dialects, the root cause is usually a gap in the original corpus. However, by injecting carefully crafted artificial examples, you can tilt the dataset back toward balance.
-
The Problem: Model Failures and Biases
3.1 Performance Gaps
First, general-purpose models stumble whenever the conversation turns ultra-specialized. For example, tax-law questions or intricate cardiac-surgery queries often reveal brittle reasoning. In addition, models trained mostly on English tend to mis-parse Yoruba or Chhattisgarhi. Finally, layered sarcasm or ten-turn dialogues can derail otherwise solid logic.
3.2 Bias and Fairness Issues
Second, distorted mirrors create distorted outputs. As a result, male-coded language may earn higher hiring scores, Western viewpoints may drown out other cultures, and affluent profiles may receive premium recommendations. Moreover, those patterns usually persist until the training data itself changes.
3.3 Data-Scarce Scenarios
Third, when events are rare-think insurance fraud, orphan diseases, or black-ice road surfaces-collecting authentic samples becomes nearly impossible. Nevertheless, models still need to learn from such scenarios, or their real-world robustness suffers.
-
Pinpointing Gaps Before Generating
Before launching a synthetic-data sprint, wise teams run four diagnostic checks:
- Error Logs: Where do outputs misfire most often?
- Fairness Audits: Which demographic slices receive poorer results?
- Coverage Maps: Which topics or situations barely appear in the corpus?
- Stress Tests: How fragile is the model when prodded with adversarial prompts?
Thus, each weakness uncovered above becomes a blueprint for the artificial records you will soon write.
-
Classic Paths to Synthetic Data Generation
-
Counterfactual Edits – Swap sentiment, change demographics, or flip contexts to ask “What if…?”
-
GAN-Powered Samples – Let a generator–discriminator duo create photo-real faces or styled paragraphs.
-
Rule-Based Swaps – Replace entities, shuffle syntax, or inject synonyms by recipe; meanwhile, keep semantics intact.
-
Statistical Simulation – Mimic the distribution of transaction sizes, lab results, or weather readings, then sample fresh rows.
-
Prompt-Driven Expansion – Co-write with a language model that focuses on under-represented angles.
-
Workflow in Future AGI
6.1 Spot the Trouble
Dashboards surface error clusters, fairness deltas, and low-coverage slices at a glance. Consequently, teams can prioritize fixes with data in hand.
6.2 Design the Synthetic Set
While defining a new dataset, practitioners supply:
- Name & Purpose - for instance, “Rural-Road Driving Scenarios.”
- Schema - columns, types, and valid ranges.
- Row Count - the scale of the boost.
- Generation Notes - plain-language guidelines that keep records realistic yet deliberately diverse.
6.3 Train, Test, and Repeat
After fine-tuning on the artificial rows, engineers rerun evaluations. If accuracy climbs or bias scores shrink, the loop continues; if not, parameters adjust and another round begins. Ultimately, progress compounds over time.
Image 1: Dataset creation and import choices

Image 2: Specify synthetic dataset metadata fields
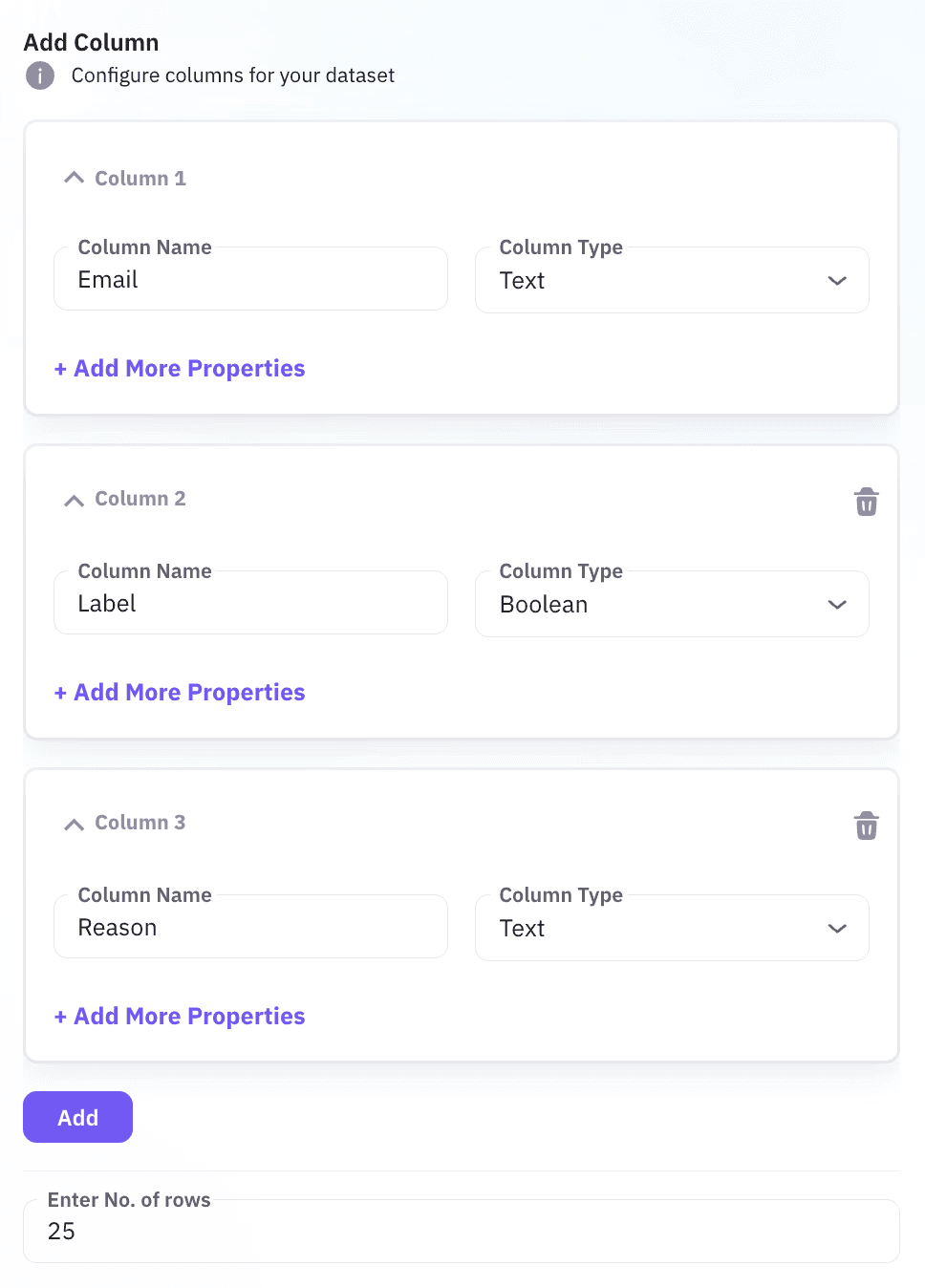
Image 3: Set email spam dataset columns
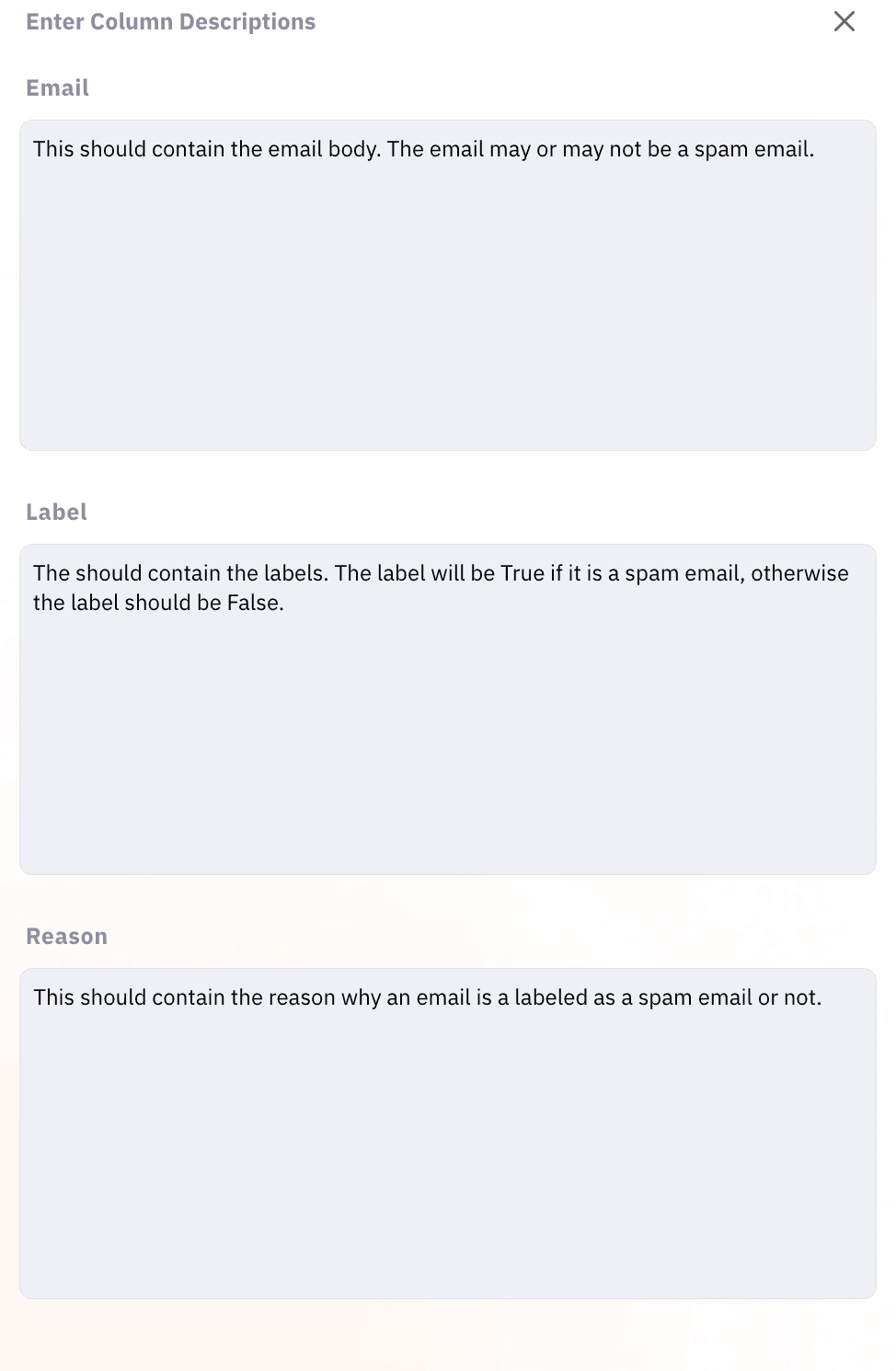
Image 4: Describe columns for spam dataset
-
Real Life Examples
Suppose a customer-support bot fails on deep-tech troubleshooting:
- Dataset Plan - columns such as Issue Description, Error Code, Solution Steps.
- Synthetic Creation - thousands of problem-solution pairs spanning device types and OS versions.
- Fine-Tuning - retraining with the new corpus.
- Validation - technical-query accuracy rises, while casual chat quality remains steady.
Similarly, balanced synthetic résumés can nudge a screening tool toward gender parity, and extra dialect samples can help a voice assistant respect regional speech.
Conclusion
Because real data arrives slowly-and often with bias baked in-synthetic data generation provides a swift, flexible lever for improvement. Furthermore, by cycling through diagnosis, targeted creation, and retraining, teams ship models that answer more accurately, treat users more fairly, and handle oddball cases with poise. Therefore, if your system shows rough edges, consider an artificial top-up before your next release.
Elevate your models with Future AGI’s synthetic data generation model - seal data gaps and slash bias in weeks, not months.
Start your free Future AGI trial today and watch accuracy and fairness climb.
FAQs
Q1: How is synthetic data generation different from traditional data augmentation?
Synthetic data creates brand-new records from scratch, while augmentation only tweaks existing ones.
Q2: Does adding synthetic data compromise user privacy?
No - records are artificial, so they contain no real personal details.
Q3: How much synthetic data should I add at first?
Start small - about 10-20 % of your original set-then monitor results before scaling up.
Q4: Can synthetic data generation cut gender bias in hiring models?
Yes - balanced, artificial résumés help the model score candidates more evenly.
Related Articles
View all
OpenAI AgentKit + Future AGI: Your End-to-End Solution for Reliable AI Agents
Discover how OpenAI AgentKit and Future AGI create reliable production AI agents. Guide covers evaluation, monitoring, workflows, and optimization.


LLM Cost Optimization: How Product-Engineering Collaboration Can Reduce AI Infrastructure Spend by 30%
Cut LLM costs 30% with proven strategies: model routing, prompt optimization, caching, and product-engineering collaboration. Includes ROI calculator and KPIs.


Top 10 Prompt Management Platforms of 2025
Compare 10 prompt management platforms for enterprise AI. Review Future AGI, Portkey, Arize & more. Find the best tool for prompt optimization in 2025.