How I Built Deterministic LLM Evaluation Metrics for Production
A first-person write-up: why a $40K judge bill pushed me to build deterministic LLM evaluation metrics first, schema, regex, structural, citation-validity.

Table of Contents
The bill arrived a week after we shipped continuous evaluation. A judge model call at three hundred milliseconds and a fraction of a cent per call sounds cheap until you multiply by a million traces a day. Then it stops being cheap. The first month landed at $40K. Worse, the judge had missed the obvious bug: a refund agent quoting amounts off by an order of magnitude because the JSON schema for the tool call had drifted three releases earlier. A parser would have caught it. The judge read the prose around the broken field and gave it a 0.89 helpfulness score.
That is when I rebuilt the eval stack from the floor up. The lesson, in one line: schema-validity + regex + citation-validity + structural assertions catch most of what production sees, for the cost of running pytest. This post is the engineering write-up of why I built a deterministic library first, what four families of checks I shipped, how they slot under the judge in a cascade, and which patterns held up at production volume.
TL;DR: the build in five beats
- A judge-only stack failed three ways: cost, latency, and the judge silently missing structural bugs a parser would catch in microseconds.
- Four families of deterministic checks did the heavy lifting: schema, regex, structural assertions, and citation-validity.
- They sat at the base of an eval pyramid: floor on every request, classifier on the residual, judge on the survivor sample.
- The cascade rule is sharp: every layer runs only on what the cheaper layer below it could not decide.
- The artifact that compounded was not the checks themselves. It was the same metric definition pinned in version control, running at the gateway, in CI, and on production samples.
The incident that triggered the build
The setup: a customer-support agent on top of a RAG index, five eval rubrics on every trace, all running as LLM-judge calls against a pinned frontier model at temperature zero. Helpfulness, faithfulness, refusal calibration, tone, and policy compliance. The dashboard looked clean. The CI gate looked clean. Three weeks in, a user posted a screenshot on Twitter: the agent had quoted a refund of $4,200 for a product that cost $42. The customer accepted it. Finance flagged it on the ledger reconciliation.
I pulled the trace. The judge had scored that response 0.89 on helpfulness. The retrieved context contained the correct amount. The tool call to issue_refund had been emitted with amount: 4200 instead of amount: 42 because of a unit-confusion bug in the prompt template. The function-call JSON schema declared amount as a float in cents. The agent passed dollars. The schema validator we did not have would have caught the type mismatch in microseconds.
That bug taught me three things I should have known sooner.
A judge reads prose. The refund response was fluent, polite, and structurally wrong. The judge had no opinion on whether amount: 4200 matched the retrieved $42 because it did not parse the tool call; it scored the user-facing text. Semantic evaluation cannot do structural validation.
The bill was already past $40K a month. Five judge calls per trace, a million traces a day, at hundreds of milliseconds each. The judge was running on every request, including the 80% where the failure (if any) would have been a missing field, a malformed URL, or a banned phrase that a regex could have caught for free.
The CI gate was flaky for reasons unrelated to our code. We had pinned the judge model by API name. The vendor pushed an upgrade. Faithfulness scores shifted by four points overnight. Builds failed. We rolled the rubric to the previous prompt. They still failed.
The fix was not a smarter judge. It was a cheaper floor under it.
The four families of deterministic checks I shipped
A metric is deterministic if running it twice on the same input returns the same score forever. Regex is deterministic. Schema validation is deterministic. An LLM judge at temperature zero is reproducible per snapshot but not deterministic across vendor rollouts, because the weights underneath the API name are a vendor decision, not yours. I wanted checks where the same inputs always produced the same numeric score with no external API in the loop. Four families covered most of what I needed.
Schema and structural validation. JSON Schema, AST parsers, SQL parsers, XML validators. Catches malformed tool-call arguments, broken structured outputs, syntax errors in generated code. The first family I added, and the one that paid back fastest. The refund bug above would have died here. Sub-millisecond per check, zero API cost, never drifts. The trap is keeping the schema files in sync with the actual tool signatures; the win is that the check fails loudly and on the right line.
Regex and contains checks. Required substrings, forbidden patterns, format gates. Compliance disclosures, PII patterns, banned product names, format requirements like “must start with <thinking>”. Sub-millisecond and tight, with one operational cost: pattern rot. Prompts drift, output formats change, and a regex silently passes outputs it should fail. The fix is treating the regex like any other test artifact: versioned, reviewed, exercised with a small fixture of known-bad inputs every release.
Structural assertions. Exact match on canonical answers, function-name match on agent tool calls, parameter-type validation, length contracts (LengthBetween), normalized equality with whitespace and casing stripped. Honest on yes/no, classification, multiple-choice, and constrained-format tasks. The single highest-signal deterministic check for agents is ParameterValidation against the tool’s declared schema. Most agent failures are not the final answer being wrong; they are the wrong tool being called with the wrong arguments.
Citation-validity. A RAG answer can pass a judge faithfulness check and still drop the supporting source from the response. Citation-presence (does the answer attribute claims to retrieved chunks) and source-attribution (do the cited spans actually exist in the retrieval context) are deterministic operations on the answer plus the context. Citation-validity is what closes the gap between “the LLM read the right context” and “the user can verify the claim against the right context.” For RAG systems, this is the single deterministic check I would ship before any judge call.
A fifth family (lexical overlap: BLEU, ROUGE, embedding similarity against a pinned model) exists, but the failure profile is narrower. BLEU and ROUGE work on translation and extractive summarization, where the reference and candidate share short, structurally similar surface forms. They fail on open-ended chat, abstractive summarization, and anything with paraphrase tolerance. I ship them for the tasks they were built for and gate nothing on them otherwise.
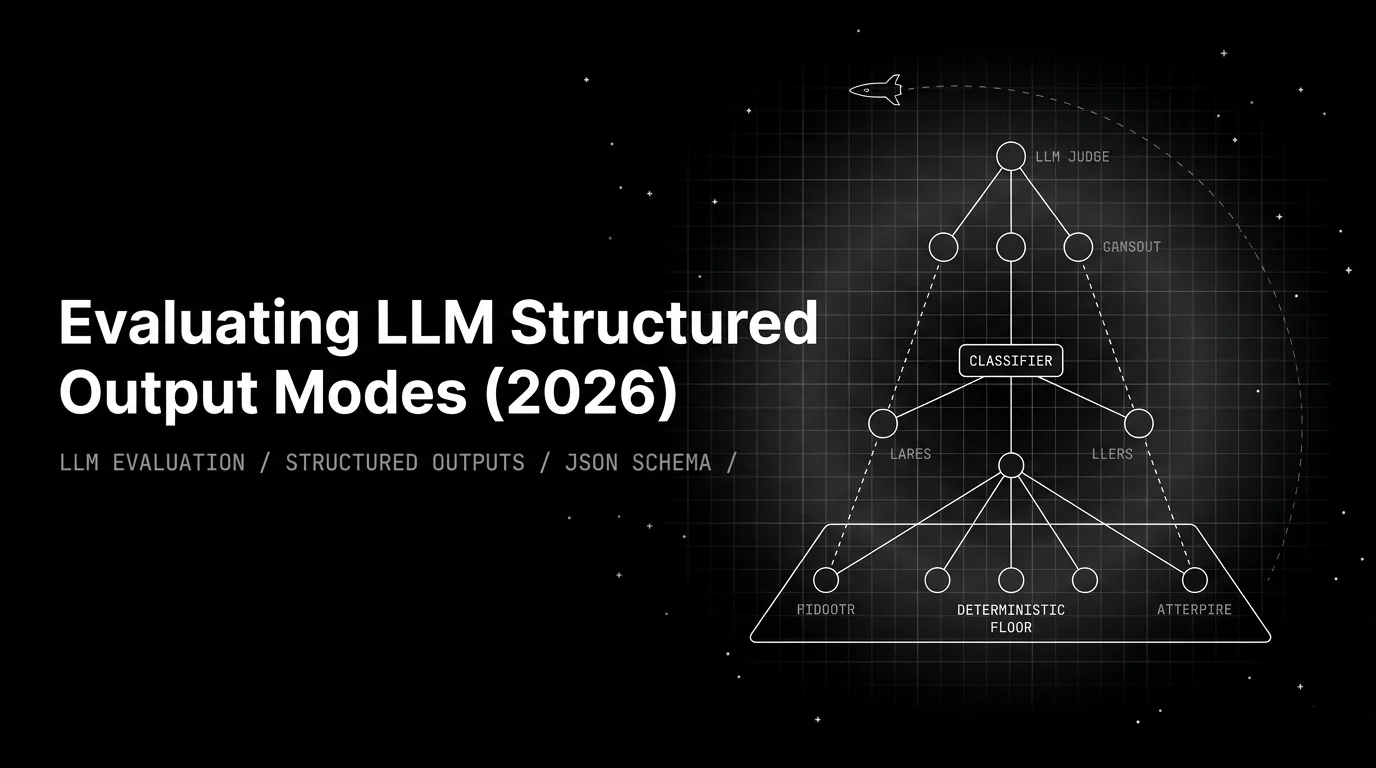
The pyramid layer pattern
The four families settle into a layered shape that most production teams converge on. Three layers, one rule: every layer runs only on what the cheaper layer below it could not decide.
Layer 1 — Deterministic floor (every request). Schema validation, regex, function-call validators, citation presence, exact match where applicable, length contracts. Sub-millisecond per check, zero API cost. Catches structural failures and policy violations before any model spends a token. In my own audit across three production agents, this layer caught roughly 60% of failures the judge would have caught for $0.003 each.
Layer 2 — Classifier triage (every output that passes Layer 1). Fine-tuned models for sharp safety targets (toxicity, PII, prompt injection, bias) and NLI for faithfulness against retrieved context. Single-digit to low-double-digit milliseconds per call. Roughly 1 to 10 percent of LLM-judge cost. Returns the same answer on the same input every time. This is where the open-weight guardrail family (LlamaGuard, Qwen3Guard, GraniteGuardian, ShieldGemma, WildGuard) earns its keep: same interface, controllable weights, on-prem deployable when the data residency policy says no cloud.
Layer 3 — LLM judge (residual sample of what survives Layers 1 and 2). Open-ended rubrics: helpfulness, role adherence, tone, faithfulness on long-form answers where claim extraction matters. 50 to 500 times classifier cost per call, hundreds of milliseconds of latency. Run on a 5 to 10 percent sample of production traffic, plus every CI test case in the regression suite. Pin the judge model and the rubric text as a contract; treat any judge upgrade as a separate eval calibration event, not as transparent.
The discipline is reaching for the cheapest layer that gives the right answer. A team gating only on Layer 1 ships semantic regressions: ROUGE on a chatbot will pass deploys that drop user satisfaction. A team gating only on Layer 3 ships a five-figure bill and a flaky CI gate.
Cascade integration with LLM-judge
The wrong frame is “deterministic vs. judge.” The right frame is “deterministic gates the judge.” Three concrete patterns held up at production volume.
Fail-fast composition. If the response fails JSON schema, the judge does not run and the eval fails outright. Same for missing citations on a citation-required rubric. Same for a refusal regex match on a refusal-required scenario. Deterministic checks are roughly 10,000 times cheaper than a frontier judge call. Run them first.
Augment-then-judge. A classifier produces a score plus per-claim reasoning, and hands it to the judge as in-context evidence. The judge starts from grounded reasoning and pays the frontier cost only when the classifier signal is ambiguous. The ai-evaluation SDK exposes this as a one-line flag:
from fi.evals import evaluate
result = evaluate(
"faithfulness",
output="...",
context="...",
augment=True,
model="gpt-4o",
)In our own measurement, this saved roughly 90% of judge cost on faithfulness with no measurable drop in detection rate.
Async judge on the trace. Run deterministic checks inline on the user-facing path; ship the judge off the hot path as a span-attached eval that writes results back to the trace as gen_ai.evaluation.* attributes. The user does not wait for the judge. The dashboard still gets the judge score. The CI gate runs both.
Production patterns that held up
A production deterministic eval looks like this end to end.
On every request, inline. The deterministic floor runs at the gateway hop, not in application code. JSON schema validation on structured outputs. Citation presence on RAG responses. Function-call validators on agent tool calls. Compliance regex on every output. Runtime safety scanners (jailbreak, secrets, malicious URL, invisible chars, language, topic restriction) on inputs and outputs. The Agent Command Center runs the 18+ built-in scanners and the local heuristic metrics inline at p99 of 21 ms with guardrails on (t3.xlarge, ~29k req/s per the github.com/future-agi/future-agi README). Application code does not change.
On every CI commit. The same deterministic suite plus the classifier layer plus the judge against a pinned golden dataset. The deterministic checks gate the judge: if the schema fails, the judge does not run. Pin the regex patterns, the JSON schema versions, the canonical answers, the judge model id, and the rubric text in version control. Re-running on the same input on the same day produces the same score within a small variance window. That is the eval contract.
On every production span (sampled). A 5 to 10 percent sample passes through the same metric definitions that ran in CI. Failures route to an annotation queue. Error Feed clusters failing traces with HDBSCAN over ClickHouse and writes an immediate_fix against a 5-category, 30-subtype taxonomy.
The artifact that compounds is not any individual check. It is the contract: the same metric definition, pinned and versioned, running at the gateway, in CI, and on the production sample, producing the same number on the same input.
The existing OSS option: ai-evaluation
I should say this plainly: most teams do not need to build a deterministic library from scratch. The same patterns I shipped internally are open source in ai-evaluation (Apache 2.0), which ships 20+ local heuristic metrics across the four families above, plus the 8 sub-10ms Scanner classes for runtime safety. The full surface, verified against python/fi/evals/metrics/:
- Structural:
JSONValidation,JSONSchema,SchemaCompliance,TypeCompliance,FieldCompleteness,RequiredFieldsOnly,FieldCoverage,StructuredOutputScore,HierarchyScore,TreeEditDistance. - Pattern:
Regex,Contains,ContainsAll,ContainsAny,ContainsNone,ContainsEmail,IsEmail,ContainsLink,ContainsValidLink,Equals,StartsWith,EndsWith,LengthBetween,OneLine,NumericSimilarity. - Function-call:
FunctionNameMatch,ParameterValidation,FunctionCallAccuracy,FunctionCallExactMatch. - Citation:
SourceAttribution,CitationPresence. - Lexical:
BLEUScore,ROUGEScore,RecallScore,LevenshteinSimilarity,EmbeddingSimilarity,SemanticListContains. - Runtime Scanners (8):
JailbreakScanner,CodeInjectionScanner,SecretsScanner,MaliciousURLScanner,InvisibleCharScanner,LanguageScanner,TopicRestrictionScanner,RegexScanner.
A working CI snippet that mirrors what I run on the refund agent:
from fi.evals.metrics.structured.json_validation import JSONValidation
from fi.evals.metrics.heuristics.string_metrics import Regex
from fi.evals.metrics.function_calling.metrics import ParameterValidation
schema_check = JSONValidation(config={"schema": REFUND_SCHEMA})
pii_check = Regex(config={"pattern": r"\b\d{3}-\d{2}-\d{4}\b"})
tool_check = ParameterValidation(config={"expected_tool": "issue_refund"})
# Run in order; first failure short-circuits the judge.The same metric definitions attach as span-level EvalTags in traceAI, so the CI suite and the production telemetry surface the same number. For the broader category map, the deterministic LLM evaluation metrics (2026) post covers the family taxonomy in more depth, and the why LLM-as-a-judge (2026) post covers what the judge layer is actually good for. Honest caveat: I built the equivalent twice before reaching for this. The second time was three months of engineering. If I were starting over, I would start here.
Final lessons
Three things I would tell my past self.
Build the floor before the judge. Pure judge-only eval looks fast to ship and slow to operate. The bill is the first signal. The drift is the second. The third signal, the one that took me longest to hear, is that a judge cannot do structural validation. A schema check would have caught the refund bug in microseconds. No judge prompt I could have written would.
Match the metric to the failure mode. Schema for structure. Regex for compliance. Function-call validators for agents. Citation-validity for RAG. BLEU and ROUGE for translation and extractive summarization, nothing else. Exact match for constrained formats. Anything semantic and open-ended belongs in the classifier or the judge. A team that ships a chatbot and gates on ROUGE will pass deploys that drop user satisfaction, because ROUGE is reading words and the user is reading meaning.
Pin the contract, not the implementation. The artifact that ages well is the same metric definition pinned in version control, running at the gateway, in CI, and on production samples. Schema versions, regex patterns, canonical answers, judge model id, rubric text: all in git, all reviewed, all replayable. A deterministic check with a stale schema fails closed in the wrong direction. A pinned definition fails for the reason you can fix.
The boring engineering is the four families of checks. The interesting engineering is the cascade: gating the judge on the floor so the expensive layer only runs on the cases that need it. Everything else is plumbing.
Related reading
- Deterministic LLM Evaluation Metrics (2026): The Eval Floor
- Why LLM-as-a-Judge (2026): The Case For, Against, and the Hybrid That Wins
- Best LLM Evaluation Tools (2026)
- Your Agent Passes Evals and Fails in Production (2026)
- The 2026 LLM Evaluation Playbook
Sources
Frequently asked questions
What is a deterministic LLM evaluation metric?
Why build a deterministic library if LLM-as-judge already works?
What are the four families of deterministic checks worth shipping?
How does the eval pyramid pattern actually work in practice?
Can deterministic metrics catch hallucinations?
What does Future AGI ship for deterministic evaluation?
Where does the LLM judge still win in the cascade?

Generic RAG eval misses what kills search agents: bad queries, stale sources, monoculture, and broken cites. A four-axis rubric you can ship this week.

Compare OpenAI strict, Anthropic JSON, Gemini schema, and Outlines grammar-constrained generation: schema-validity rate, quality tax, failure modes.


Schema, regex, exact match, BLEU/ROUGE, citation-validity. Where deterministic LLM eval metrics catch 30-60 percent of failures before a judge fires.
