Evaluating Cohere Rerank in RAG (2026)
Reranking helps when recall is high but precision is low. It hurts when recall is low. The eval triangle (NDCG@k, recall delta, latency) tells you which.
Table of Contents
You added Cohere Rerank 3.5 on top of your dense retriever last month. The cost line went up. The latency p99 went up. The answer quality looks the same. Maybe the reranker is earning its slot. Maybe it’s rearranging chairs on a candidate set the base retriever already nailed in the top-3. Maybe it’s quietly demoting the correct doc on short queries and you never measured it.
The opinion this post earns: reranking helps when retrieval recall is high but precision is low. It hurts when recall is low. No reranker rescues a chunk that never made the candidate list. No reranker improves a top-3 that’s already correct. The way to know which case you’re in is the eval triangle, scored on the same queries with the reranker on and off: NDCG@k_post_rerank for ranking quality, Recall@k_pre_rerank versus Recall@k_post_rerank for recall preservation, and latency p95/p99 for the cost in user-perceived time. Without these three you’re guessing whether the rerank cost is paying for itself.
This guide is the eval methodology. The recall-precision tradeoff, the eval triangle, an honest comparison of Cohere Rerank 3.5 against Voyage rerank-2.5 and Mixedbread mxbai-rerank-large-v2, per-domain decisions, production patterns including semantic caching, and traceAI instrumentation that keeps the verdict honest after deploy. For the broader RAG eval landscape, the RAG evaluation metrics deep dive covers the foundational definitions; this post is the reranker-specific layer on top.
TL;DR: when reranking helps, when it hurts
| Signal | Reranking helps | Reranking hurts |
|---|---|---|
| recall@k_pre_rerank | > 0.90 with large k (50-100) | < 0.85; the right chunk isn’t even in the candidate set |
| recall@3 of base retriever | < 0.70; right doc is past rank 3 often | > 0.90; the base is already nailing it |
| query distribution | English, medium-length, well-formed questions | < 5-token keyword queries; multilingual against English-trained reranker; identifier-heavy code |
| chunk size | Coherent units (clause, paragraph, function) | Fixed-size splits cutting clauses across boundaries |
| latency budget | > 800 ms total response | < 800 ms (real-time voice, sub-second chat) |
Two non-negotiables across every reranker decision. Measure base retriever recall@50 before adding the reranker (recall is upstream; precision is downstream; the reranker is precision-only). Score NDCG@k_post_rerank plus the recall delta plus latency p99 as a triangle, not a single number.
The recall-precision tradeoff at the heart of reranking
A reranker is a precision tool, not a recall tool. The retriever decides what’s in the candidate set; the reranker decides the order inside it. This is the entire shape of when reranking helps.
Imagine four scenarios on a 1000-document corpus, top_k_pre_rerank=50, top_k_post_rerank=5:
- Recall high, precision low. Retriever returns the supporting chunk at rank 23 of 50. Without rerank, the LLM sees top-5 (none of which contain the answer) and hallucinates. With rerank, the supporting chunk moves to rank 2; the LLM grounds correctly. Uplift is real. Reranker earns its slot.
- Recall high, precision high. Retriever returns the supporting chunk at rank 2 of 50. Top-5 already contains it. Reranker moves it to rank 1. Marginal NDCG gain; the answer is identical. Reranker is decorative. Cost is paid for movement the LLM didn’t need.
- Recall low. Retriever doesn’t surface the supporting chunk in top-50. The right chunk is at rank 200 in the dense index or absent entirely (chunking error, embedding-domain mismatch, missing document). Reranker has nothing to work with. No reranker rescues this. Fix the retriever, not the precision layer.
- Recall medium, query distribution-shifted. Retriever returns the supporting chunk at rank 5. Query is two tokens of Hindi against an English-Hindi corpus. Cross-encoder over-weights English token overlap and demotes the Hindi-supporting chunk to rank 30. Reranker actively hurts.
The eval question is not “does the reranker improve answer quality?” The eval question is “for which slice of my queries does the reranker improve answer quality, by how much, at what latency cost, and where does it degrade?”
The eval triangle: NDCG@k, recall delta, latency cost
Most teams score reranker pipelines with one number (faithfulness on the final answer). That number changes for six reasons (retriever shifted, reranker shifted, chunker shifted, prompt shifted, model shifted, distribution shifted), and one number can’t tell you which.
Three rubrics, scored as a triangle, separate the reranker’s contribution from everything else:
NDCG@k_post_rerank. Normalised Discounted Cumulative Gain at the post-rerank top-k. Measures whether the reranker put the most relevant chunks in the highest ranks. Compute per query against a labelled relevance grade (binary or graded 0-3); aggregate per domain stratum. NDCG@10 is the standard; NDCG@5 matters more if your prompt only consumes top-5. A reranker that lifts NDCG@10 by 0.08 on contracts and drops it by 0.04 on multilingual is making a tradeoff you have to see per route.
Recall@k_pre_rerank versus Recall@k_post_rerank. The recall the retriever earned, versus the recall the reranker preserved. With k_pre_rerank=50 and k_post_rerank=5, a reranker that drops recall from 0.94 to 0.78 destroyed sixteen points of recall to win precision on the top-5. Sometimes that’s the right trade (precision matters more than coverage on factual QA). Sometimes it’s not (multi-hop questions need the second supporting chunk you just dropped). The number tells you.
Latency p95 and p99 added by the rerank hop. Per-call, not aggregate. Cohere Rerank 3.5 adds roughly 80 to 150 ms p50 on chunks under 2k tokens; 200 ms-plus p99 on chunks past 3k tokens. A reranker that doubles your end-to-end p99 is a different product than one that adds 5 percent to p50. Measure both.
Compute all three on the same golden set, with the reranker on and off, stratified by domain. The triangle reads:
- NDCG up, recall preserved, latency reasonable: ship it.
- NDCG up, recall dropped, latency reasonable: tune top_n (try k_post_rerank=10 instead of 5) or revisit the precision-recall preference per route.
- NDCG flat, latency added: the reranker is decorative on this slice. Scope it out.
- NDCG up, latency p99 blown: cache scores aggressively, downsample candidate-set size, or move to a faster reranker variant.
Cohere Rerank 3.5 vs Voyage vs Mixedbread (honest tradeoffs)
Three rerankers dominate production RAG in 2026. The decision is rarely about absolute quality on a leaderboard. It’s about cost model, latency tail, language coverage, and whether you need self-hostable weights.
| Reranker | Best for | Languages | Max chunk | Latency p50 | Cost model | Self-host |
|---|---|---|---|---|---|---|
| Cohere Rerank 3.5 | Multilingual production; broadest track record | 100+ | 4096 tokens | 80-150 ms | Per-1k documents | No (API only) |
| Voyage rerank-2.5 | Domain-tuned (code, finance, legal); strong English | English-dominant | 8192 tokens | 90-180 ms | Per-1k documents | No (API only) |
| Voyage rerank-2.5-lite | Latency-sensitive English | English-dominant | 8192 tokens | 40-80 ms | Per-1k documents (cheaper) | No (API only) |
| Mixedbread mxbai-rerank-large-v2 | Self-hostable English; on-prem and air-gapped | English plus EU langs | 32k tokens | 60-200 ms (GPU-dependent) | Amortised infra | Yes (open weights) |
On most English RAG corpora the three are within 1 to 3 NDCG@10 points of each other. The decision matrix:
- Multilingual or non-English production. Cohere Rerank 3.5. Voyage and Mixedbread degrade materially outside English on most public benchmarks; Cohere’s 100-plus language training holds quality on Spanish, French, German, Japanese, Mandarin, Arabic, Hindi, and Portuguese in our measurements.
- English with strict latency budget (< 600 ms total). Voyage rerank-2.5-lite. Cuts the rerank hop roughly in half versus Cohere with a small quality cost on out-of-domain queries.
- English code corpus or finance/legal in-domain. Voyage rerank-2.5 (domain variants). The fine-tuning on code identifiers and legal terminology shows up as 2 to 4 NDCG@10 points over generic rerankers on the corresponding stratum.
- On-prem, air-gapped, or sensitive-data deployment. Mixedbread mxbai-rerank-large-v2. Open weights mean the model runs in your VPC. Pair with a single A10 or L4 GPU and the per-call cost moves from per-1k-documents to amortised infrastructure.
- You don’t know yet. Cohere Rerank 3.5. Strongest default, broadest documentation, lowest activation cost. Switch later when the eval triangle says one of the others wins your specific workload.
The best rerankers for RAG 2026 post covers the broader landscape including the open-source long-tail (BGE-reranker-v2, Jina-reranker-v2). This post is about whether Cohere specifically earns its slot in your pipeline.
Per-domain decisions: where reranking wins and loses
The same reranker behaves differently across document types. Read the stratified breakdown, not the aggregate.
- Legal and medical: high uplift, watch precision on identifiers. Contracts, regulations, clinical notes. Recall is typically high (the right clause is in the top-50); precision is typically low (similarly-worded clauses cluster). Reranker uplift on NDCG@5 of 0.10 to 0.15 is common. Pair with clause-level chunking and the gain compounds. Watch identifier queries (ICD codes, statute numbers) where token-level matching can lose to a cross-encoder’s semantic preference.
- Long-form prose: moderate uplift if chunking is semantic. Research papers, transcripts, books. Reranker uplift on NDCG@10 of 0.05 to 0.08 typical. Fixed-size chunking neutralises the gain (the reranker scores ambiguous half-passages); semantic or section-level chunking preserves it.
- Code and code-mixed: low uplift on cross-encoders, high on token-level matching. Source code, code with comments, mixed languages. Cohere Rerank 3.5 underperforms on identifier-heavy queries (function names, variable names) because cross-encoders over-weight semantic similarity. Late-interaction retrieval (ColBERT-style) at the retrieval layer often wins outright over dense-plus-cross-encoder-rerank for these. The chunking strategies post covers the late-interaction case in depth.
- Multilingual: stratify or skip. Score per language. English, Spanish, French, German, Mandarin tend to hold quality across all three rerankers. Hindi, Arabic, Bengali, Swahili can lose 5 to 10 NDCG points on Voyage and Mixedbread; Cohere holds better but still loses points on under-five-token queries. A reranker that gains ten points on average and loses twenty on Hindi is not a win.
- Marketing and product FAQs: skip. Uniform short paragraphs, queries are mostly lookup, recall@3 from a half-decent dense retriever sits near 0.95. Reranker adds latency and cost without changing the answer.
Route by document type before reranking, not after. A single reranker applied uniformly is the source of most reranker-eval failures we see in production.
Production patterns: instrumenting and caching
The CI gate catches regressions you can think of. Production catches everything else. Same rubrics, two places.
traceAI (Apache 2.0) ships a CohereInstrumentor that wires every rerank, embed, and chat invocation into the OpenTelemetry trace tree with one call:
from fi_instrumentation import register
from fi_instrumentation.fi_types import ProjectType
from traceai_cohere import CohereInstrumentor
trace_provider = register(
project_type=ProjectType.OBSERVE,
project_name="cohere-rerank-prod",
)
CohereInstrumentor().instrument(tracer_provider=trace_provider)Every rerank call emits a span with fi.span.kind=RERANKER. The span carries cohere.rerank.model, cohere.rerank.top_n, cohere.rerank.documents_count, per-document relevance scores, and end-to-end latency. The before-and-after rank lists land as span attributes, so you can see which doc moved up and which got demoted. This is what lets a RerankerUplift rubric score the actual delta rather than a generic faithfulness number, and what makes a cohere.rerank.model change auditable when Cohere ships a new version.
Semantic caching of reranker scores is the single highest-ROI production pattern most teams haven’t implemented. Two cache layers:
- Exact cache. Key on
(query_normalised, sorted_doc_ids, reranker_model_version). Hit rate is high on lookup workloads (product search, FAQ, support) and low on long-tail conversational queries. Hits return scores in under 5 ms versus 80 to 150 ms uncached. Cost saving is roughly the hit rate times the per-call cost. - Semantic cache. Key on embedding similarity to past queries above a threshold (0.95 cosine works for English question-answer corpora; lower for code where identifier overlap dominates). Reuses scores for paraphrased queries. Hit rate on semantic cache typically lands 20 to 40 percent on conversational RAG workloads.
Combined, exact-plus-semantic caching cuts rerank cost by 30 to 60 percent on most production RAG workloads we’ve measured with customers. Cache invalidation matters: bust the cache on reranker model version change (the span attribute is the audit trail), bust on document edit, and set TTL by route based on how fresh the underlying corpus is (24 hours for product docs, 7 days for legal corpora that rarely change).
The Agent Command Center ships both cache types (in-memory or Redis exact, plus Qdrant or Pinecone semantic) as gateway primitives with x-agentcc-cache-force-refresh, x-agentcc-cache-ttl, and x-agentcc-cache-namespace headers. Run Cohere through the gateway and the same OpenAI-compatible drop-in handles caching, observability, and cost telemetry without rewriting the SDK calls.
How Future AGI ships reranker evaluation
Future AGI ships the eval stack as a package. Start with the SDK for code-defined evals. Graduate to the Platform when you want self-improving rubrics authored by an in-product agent.
- ai-evaluation SDK (Apache 2.0):
from fi.evals import Evaluator, thenevaluator.evaluate(eval_templates=[...], inputs=[TestCase(...)]). Six RAG-specificEvalTemplateclasses (Groundedness,ContextAdherence,ContextRelevance,Completeness,ChunkAttribution,ChunkUtilization) plus 50+ total;CustomLLMJudgeforRerankerUpliftand domain rubrics; classifier-backed evals at lower per-eval cost than Galileo Luna-2. - Future AGI Platform: self-improving evaluators tuned by thumbs up/down feedback; in-product authoring agent writes reranker-eval rubrics from natural-language descriptions.
- traceAI (Apache 2.0):
CohereInstrumentorplus 50+ AI surfaces across Python, TypeScript, Java; 14 span kinds with a first-classRERANKERthat carries model, top_n, document count, and per-document scores. - Error Feed (inside the eval stack): HDBSCAN clustering plus Sonnet 4.5 Judge writes the
immediate_fixper cluster. Common reranker clusters: “rerank demotes correct doc on under-five-token queries,” “rerank latency tail above p99 on 3k-plus token chunks,” “rerank quality drops on Hindi-English pairs.” - Agent Command Center: OpenAI-compatible gateway as a single Go binary (Apache 2.0). 100+ providers including Cohere, Voyage, and Mixedbread routing. 18+ built-in guardrail scanners plus 15 third-party adapters. Exact and semantic caching at the gateway layer. SOC 2 Type II, HIPAA, GDPR, CCPA certified; ISO/IEC 27001 in active audit.
from fi.evals import Evaluator
from fi.evals.templates import (
ContextRelevance, ChunkAttribution, ChunkUtilization,
Groundedness, CustomLLMJudge,
)
from fi.testcases import TestCase
evaluator = Evaluator() # FI_API_KEY / FI_SECRET_KEY from env
reranker_uplift = CustomLLMJudge(
name="reranker_uplift",
rubric="""
Score whether answer_with_rerank is closer to expected_answer
than answer_no_rerank on (query). 1.0 if meaningfully better,
0.5 if equivalent, 0.0 if worse. Name the specific quality
difference (factual coverage, citation accuracy, relevance).
""",
judge_model="gpt-4.1",
)
def score_rerank_uplift(golden_set, retriever, reranker, synthesizer):
rows = []
for ex in golden_set:
base = retriever(ex.query, k=50)
reranked = reranker(ex.query, base, top_n=5)
ans_off = synthesizer(ex.query, base[:5])
ans_on = synthesizer(ex.query, reranked)
tc = TestCase(
query=ex.query,
answer_no_rerank=ans_off,
answer_with_rerank=ans_on,
expected_response=ex.expected,
context=[c.text for c in reranked],
)
result = evaluator.evaluate(
eval_templates=[
ContextRelevance(), ChunkAttribution(),
ChunkUtilization(), Groundedness(),
reranker_uplift,
],
inputs=[tc],
)
rows.append((ex.domain, result))
return rowsRun the same rubric in CI before deploy and as span-attached scorers on live traces via traceAI after. Sample 5 to 10 percent of production traffic for LLM-as-judge rubrics; deterministic rubrics like citation validity run on 100 percent. Alarm on a 2 to 5 point drop in rolling-mean per rubric per route over 30 to 90 minutes.
Ready to score your reranker uplift? Wire ContextRelevance, ChunkAttribution, ChunkUtilization, and a RerankerUplift CustomLLMJudge into a pytest fixture this afternoon against the ai-evaluation SDK. Stratify the golden set by domain and language. Add the CohereInstrumentor when production traces start asking questions the CI gate missed.
Related reading
Frequently asked questions
When does reranking actually help a RAG pipeline?
When does reranking hurt?
What is the eval triangle for a reranker in RAG?
How does Cohere Rerank 3.5 compare to Voyage rerank-2.5 and Mixedbread mxbai-rerank-large-v2 in 2026?
How does Future AGI score reranker uplift?
Should I cache reranker scores in production?
Should chunk size influence the reranker decision?
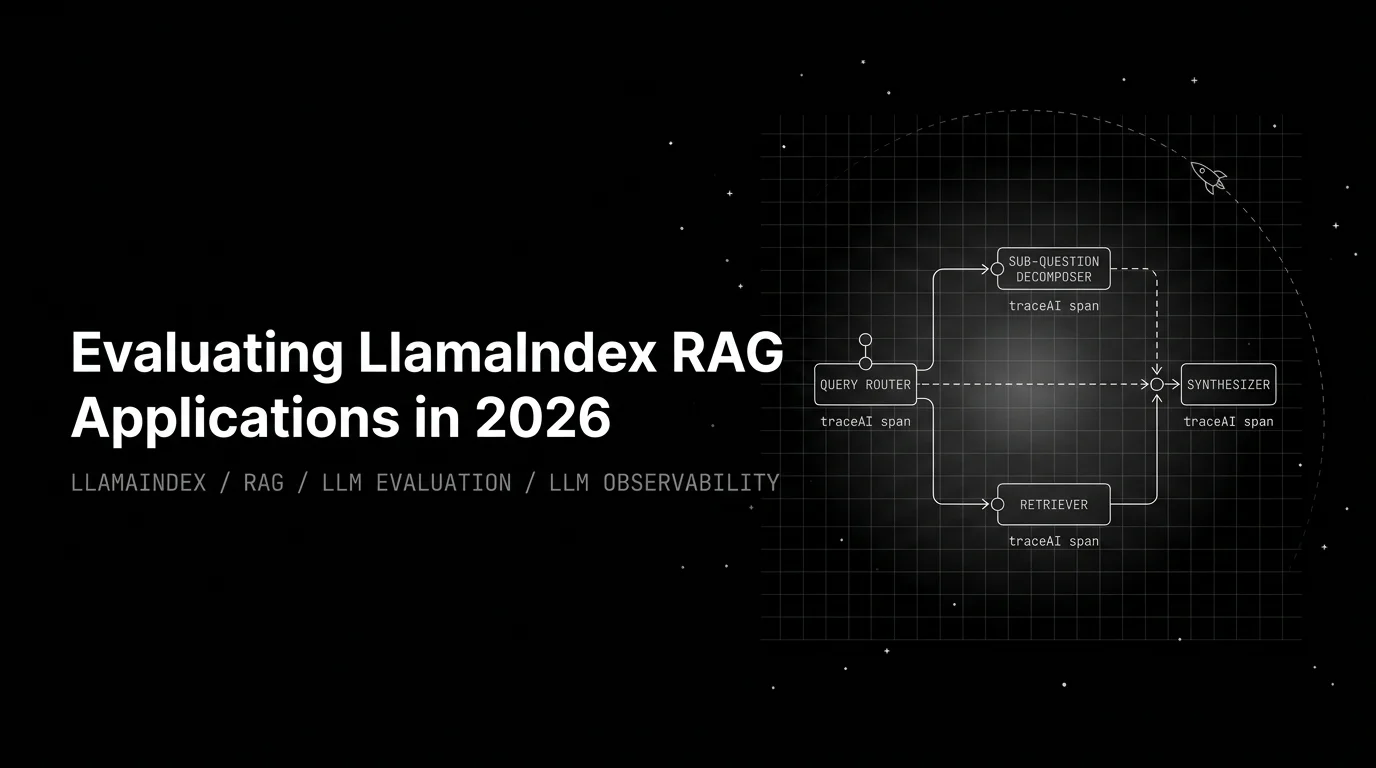
LlamaIndex RAG eval is not generic RAG eval. Four layers, four rubrics: retriever, query-pipeline, agent tool calls, and the traceAI bridge to production.


MTEB Recall@10 does not transfer to your domain. 500 labeled query-passage pairs from your traffic decide which embedding wins, not boards.

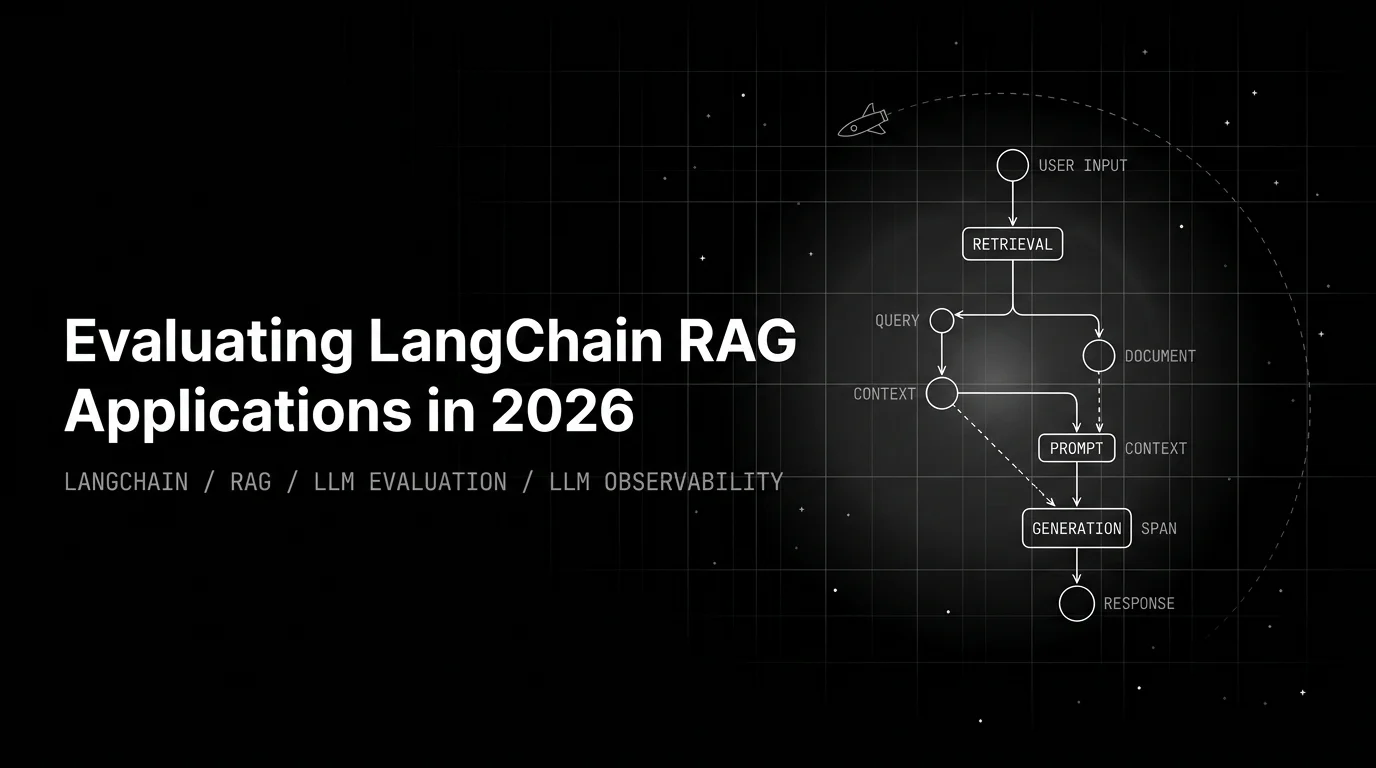
LangChain RAG eval is two problems: the retriever and the chain. Per-step rubrics catch the bug; chain-level Groundedness on LCEL output confirms the fix.