SLM vs LLM: A Detailed Comparison of Language Models
Learn how to assess AI agents' performance, reliability and ethical standards with practical examples using FutureAGI's evaluation tools for effective analysis.

Table of Contents
-
Introduction
Language models have revolutionised the way computers understand and use language. Large Language Models (LLMs) have made significant advances recently in natural language processing (NLP), but Small Language Models (SLMs), which typically have fewer parameters, offer quick answers. Meta’s Llama 3 was far better in English when it emerged in 2024 with 405 billion parameters.
Apart from many parameters, Llama 3 uses new training methods including supervised fine-tuning and reinforcement learning with human feedback (RLHF), and has an enhanced transformer design. These improvements enable it to better understand and generate human language than it could have previously.
By allowing computers to understand, create, and respond to human languages, language models help applications, including speech recognition, machine translation, and text summarising, function better.
Language models strive, theoretically, to estimate the probability of a set of words occurring together. Like n-gram models, some SLMs use the words that come before a given word to deduce its likelihood.
‘But what are N-gram models?
Before the creation of advanced neural networks, N-gram models were one of the first types of language models in use. An n-gram model uses the previous n-word to predict the next word.
Let’s get back to the subject.
However, they struggle to understand context and long-term relationships. Complex linguistic patterns and relationships can be understood by language models, particularly those that employ transformer architectures. Since deep neural networks have replaced n-gram models, language models perform significantly better.
Despite being faster to deploy and more computationally efficient than larger models, SLMs are less suited to capture complex linguistic patterns due to their smaller size.
On the other hand, because LLMs use a large number of parameters and extensive datasets, they are excellent at identifying variations of language and creating content that sounds human. Accordingly, LLMs perform better in high-stakes and general-purpose NLP applications. Let’s examine each of them in greater detail, comparing their performance metrics.
-
Language Models by Scale
Small Language Models (SLMs): These models typically contain up to a few billion parameters. As an example, Phi-2 from Microsoft contains 270 million parameters, whereas Gemma-3 from Google has 27 billion. Tasks that need minimal context or simpler computations, such as auto-completion, grammatical correction, or the generation of simple text summaries, are particularly well-suited for using SLM strategies.
Large Language Models (LLMs): Parameters in LLMs range from tens of billions to hundreds of billions. Models with 70 billion parameters are available in Meta’s Llama 3, and OpenAI’s GPT-4 reportedly has as many as 70 billion and 1 trillion parameters, respectively. LLMs’ high parameter counts enable complex activities like sophisticated reasoning and coding.
This huge difference in parameter counts has a direct impact on the architectural design and complexity of these models, influencing how they perform different NLP tasks. Let’s look at the main components and structural differences that distinguish SLMs from LLMs.
-
Architectural Design & Model Complexity
Core Components of Language Models
The embedding layer turns input words into dense vector representations that store meaningful information that is needed to understand language.
- Dimensionality Differences in SLMs vs. LLMs
When SLMs try to balance speed and computational efficiency, they often use embeddings with smaller dimensions. In comparison, LLMs use higher-dimensional embeddings, which let them understand finer semantic details and complicated language patterns.
- WordPiece and Byte-Pair Encoding (BPE) Tokenization
Byte Pair Encoding (BPE) and WordPiece are two examples of subword tokenization approaches that are used by both SLMs and LLMs. These methods break down words into their parts so that models may better deal with unfamiliar or uncommon terms. Tokenization enhances the model’s capacity to handle extensive vocabulary sets and detect significant linguistic patterns by dividing words into their component subwords.
These embedding and tokenization approaches establish the foundation for how language models analyze input data, but it is the encoder-decoder structures that determine how they create meaningful outputs. Now let’s have a look at the encoder-decoder structure for SLM and LLM.
Encoder-Decoder Structures
A common architecture for language models is the encoder-decoder. A decoder takes input sequences and uses them to create new sequences, whereas an encoder transforms them into representations containing a lot of information.
Detailed Comparison of Transformer-Based Architectures
Transformer-based systems have changed the way language modelling is done by making it easier to handle sequential data quickly.
SLMs usually use shallower transformer designs with fewer layers, which means they focus on specific tasks with little background information.
On the other hand, LLMs use more complex transformer designs with many layers. This lets them understand complicated language patterns and dependencies, which improves them at a lot of different NLP tasks.
The variation in transformer architecture results in considerable variances in layer depth and stacking, affecting the models’ capacity to collect context and deal with difficult tasks. Let’s look at how layer stacking and depth change between SLMs and LLMs.
Layer Stacking and Depth Variations
- SLMs: Shallow Networks (6–12 Layers)
Most SLMs have between 6 and 12 transformer layers, which is enough for tasks that need a modest amount of context understanding. The smaller design finds a good mix between speed and processing efficiency. This means that SLMs can be used when resources are limited.
- LLMs: Deep Networks (48+ Layers)
A typical LLM design has 48 or more transformer layers, making it significantly more complicated than the average. Text synthesis, translation, and understanding are just a few of the areas where they shine due to their improved depth, which lets them replicate complex linguistic patterns and long-term relationships.
The depth and layer differences in these designs have a significant impact on their performance, but it is the attention mechanisms that provide exact language processing and context handling. Let’s take a deeper look at the attention processes in SLMs and LLMs.
Attention Mechanisms
Attention mechanisms enable models to concentrate on the most significant components of input data, similar to how humans carefully examine critical details when processing information. This selective focus improves the model’s performance in tasks such as language translation and image recognition by enhancing its ability to comprehend context.
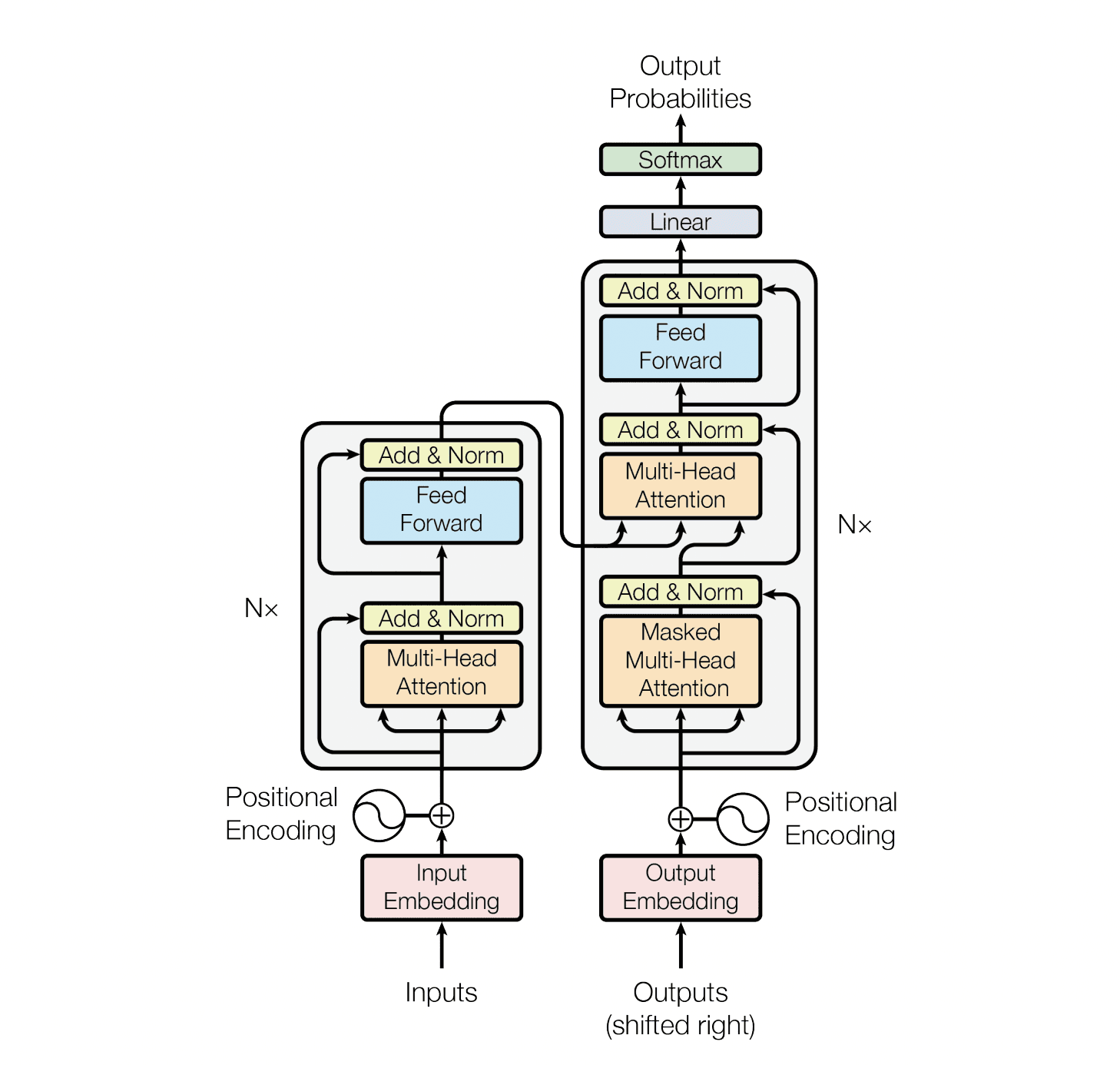
Figure 1: Transformer model architecture: Source
Scaled Dot-Product Attention
Scaled dot-product attention takes the square root of the key dimension as its scaling factor and then computes attention scores by multiplying the query and key vectors by their dot product.
Finally, attention weights are obtained by using a softmax function. This method helps models grasp interdependence by focusing on key input sequence components.
-
Efficiency Improvements in SLMs
Sparse attention techniques are frequently used by small language models (SLMs) to improve efficiency. It decreases computational effort and memory use by focusing on a subset of tokens, making it suited for extended sequences or limited resources.
-
Full Attention in LLMs and Its Quadratic Time Complexity
Large Language Models (LLMs) use complete attention techniques, where each token pays attention to the next. This technique captures extensive contextual linkages but requires quadratic time and memory complexity per sequence length, making extended sequence processing difficult.
While traditional attention techniques are effective, their computational requirements can be challenging, particularly for SLMs. This is where other techniques come in, providing more efficient ways to manage attention without sacrificing too much performance. Let’s look at some of the alternatives.
Alternatives to Attention in SLMs
Researchers have created more efficient attention methods to solve the computing problems of classic attention mechanisms, notably in SLMs.
-
Performer (Linear Attention)
The Performer architecture uses linear attention techniques to approach standard attention with linear time and spatial complexity. Performers reduce computing loads and maintain performance in resource-constrained contexts by using kernel-based approaches.
-
Reformer (Locally Sensitive Hashing)
Locally Sensitive Hashing (LSH) approximates attention scores in reformer models, improving efficiency. This method lets the model focus on important tokens without creating entire attention matrices, saving memory and computational costs.
It is necessary to understand what constitutes the sequence of words in a series to have efficient language modelling. These alternate attention methods boost efficiency, particularly in smaller models. Consequently, our discussion brings us to positional encoding techniques, which play a significant role in providing models (SLM and LLM) with an understanding of word order.
Positional Encoding Techniques
Transformers without sequence order knowledge need positional encoding to determine token placements.
-
Learned Positional Embeddings (SLM)
Small Language Models can use positional embeddings as training parameters. This method lets the model modify positional encodings during training to better capture task-specific dependencies.
-
Sine-Cosine Encoding (LLM)
Many Large Language Models encode location using fixed sinusoidal functions. Since continuous functions are used for encoding, the model can generalize to sequence lengths beyond training.
Positional encoding ensures that transformers understand the order of tokens, but good performance is also dependent on the appropriate optimization algorithms. Let’s look at the primary optimization strategies used to train SLMs and LLMs.
Optimization Techniques
Gradient Clipping and Adaptive Learning Rates
Stable training is achieved by limiting gradients during backpropagation to prevent bursting gradients. Based on historical gradients, adaptive learning rate algorithms optimize convergence by adjusting parameter learning rates.
Differences in Optimizer Usage
- SGD Variants for SLMs in Low-Resource Environments
Low-resource Small Language Models can use Stochastic Gradient Descent Variations. Simple and efficient, these optimizers, often paired with momentum or learning rate schedules, are suited for contexts with minimal computational resources.
- AdamW for LLMs
Many Large Language Models use the AdamW optimizer, which combines adaptive learning rates with weight decay regularization. Large model optimization landscapes are handled well by this optimizer, increasing convergence and generalization.
Optimization techniques are necessary for providing effective and consistent training for both SLMs and LLMs. Now, let’s look at how these models are assessed using performance indicators and benchmarks.
-
Performance Metrics & Benchmarking
The Massive Multitask Language Understanding (MMLU) benchmark is comparable to a comprehensive examination of AI language models. It evaluates their comprehension and application of knowledge in 57 subjects, including math, law, medicine, and philosophy, through approximately 16,000 multiple-choice questions.
Here’s a categorized comparison of performance metrics from Small Language Models (SLMs) and Large Language Models (LLMs) across several tasks.
Small Language Models (SLMs)

Large Language Models (LLMs)
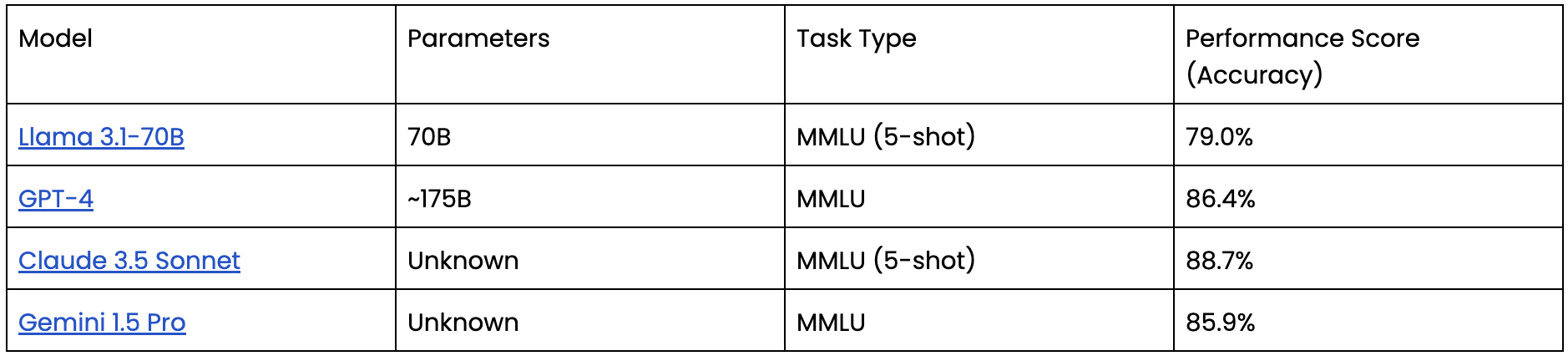
The table above compares the capabilities of various SLMs and LLMs with their sizes and also shows how well they perform across different tasks.
Note: Performance scores are based on various benchmarks such as MMLU (Massive Multitask Language Understanding) and specific task efficiencies. The parameter counts are approximate and may vary based on model versions and configurations.
-
Conclusion
It becomes clear that there are significant differences between LLMs and SLMs when looking at their design, performance, and applicability. SLMs are fast and efficient because they have fewer parameters. This makes them perfect for specific jobs where resources are limited.
On the other hand, LLMs, which have many different requirements, are great at complex language tasks because they have more advanced structures and more parameters. When it comes to language tasks, Large Language Models (LLMs) such as GPT-4 is great at complicated language tasks for more than one reason, not just their large number of parameters. The vast, diverse datasets they learn from, along with their complex architectures and advanced training methodologies, significantly influence their high performance.
Recommendations:
- SLM: SLMs provide efficient and cost-effective solutions for specific applications in situations with limited resources.
- LLM: LLMs are best for general-purpose tasks and high-stakes situations that require understanding and using words deeply.
Ensuring the dependability and performance of AI models depends on their evaluation. Future AGI helps businesses reach great accuracy across applications by providing an advanced platform for thorough AI model evaluation and optimization.
FAQs
Q1: What distinguishes Small Language Models (SLMs) from Large Language Models (LLMs)?
While LLMs have more parameters and can handle complex language tasks, SLMs have fewer parameters and are thus efficient for particular tasks.
Q2: Are SLMs more cost-effective than LLMs?
Indeed, SLMs need less computational capability than LLMs, so lowering running costs.
Q3: Can SLMs be customized for specific industries?
Indeed, SLMs can be customized to meet the particular requirements of different industries, thus improving their relevance.
Q4: Do LLMs perform better than SLMs in all scenarios?
Not exactly, although LLMs stand out on challenging tasks, SLMs are better suited for uses demanding speed and efficiency.
Related Articles
View all
Prompt Injection: Exploring Its Risks and Solutions in AI Security
Prompt injection: A critical AI threat where hackers manipulate prompts to bypass security. Learn its risks, attack types, and strategies for protection.


How to Build LLM Agents for Real-World Applications
Learn how to build LLM agents for AI automation. Explore key concepts, tools, and best practices to create intelligent, efficient AI-powered workflows.


Best Free AI Search Engines to Try Today
Discover the best free AI search engines like You.com and Perplexity AI. Experience smarter and personalized searches for accurate, efficient information