Top 5 Synthetic Dataset Generators in 2026: How to Choose the Right Tool for AI Training, Privacy, and Scale
Compare the top 5 synthetic data generators in 2026. Covers types of synthetic data, why synthetic data matters for AI training and privacy, and a side-by-side.

Table of Contents
Update — 2026: This 2025 post remains the canonical primer below. For the 2026 refresh with newer entries, updated tooling, and current pricing, read Synthetic Test Data for LLM Evaluation in 2026: A Practical Guide.
Why Synthetic Data Has Become Essential for Cost-Effective and Privacy-Safe AI Development
In today’s data-driven economy, access to quality datasets is a vital ingredient in building intelligent systems. But gathering real-world data is often costly, time-consuming, and fraught with privacy concerns. That’s where Synthetic Data steps in.
Synthetic data refers to artificially generated information that mimics real-world datasets. It’s created through algorithms rather than collected from actual events. With increasing concerns around data scarcity and compliance regulations like GDPR, synthetic data has become a lifeline for businesses, researchers, and AI developers.
But how does synthetic data work? And what tools are leading the way in 2025? Let’s break it all down.
What Is Synthetic Data Generation: How Algorithms, Simulations, and AI Models Create Realistic Artificial Datasets
Synthetic data generation is the process of creating realistic datasets using algorithms, simulations, or AI models. It helps in training machine learning models, validating systems, or performing analytics, all without exposing sensitive information.
Why Use Synthetic Data Instead of Real Data: Cost, Privacy, Scalability, and Bias Control Benefits Explained
- Cost-effective: No need to hire data annotators or conduct surveys
- Privacy-safe: Avoids risks associated with personal data leaks
- Scalable: Generate data for rare or edge-case scenarios easily
- Bias control: Better balancing of class distributions
Whether you’re testing fraud detection systems or training computer vision models, synthetic data is increasingly becoming the foundation of responsible AI.
Types of Synthetic Data: Tabular, Image and Video, Textual, Time-Series, and Multimodal Formats Explained
Synthetic data comes in different flavors depending on the application. Let’s explore the main categories:
Tabular Data: How Synthetic Spreadsheet and Database Datasets Serve Finance, Healthcare, and Business Intelligence
Used widely in finance, healthcare, and business intelligence. Synthetic tabular datasets mimic rows and columns like spreadsheets or databases.
Image and Video Data: How Computer Graphics and 3D Engines Generate Training Data for Vision AI Systems
Generated through computer graphics or 3D engines. Useful in training autonomous vehicles, surveillance systems, and facial recognition tools.
Textual and NLP Data: How AI-Generated Text Simulates Conversations, Emails, and Documents for Language Models
AI-generated text simulates conversations, emails, or documents. Often used in chatbots or language model pretraining.
Time-Series Data: How Sequential Event Replication Serves Stock Price, ECG, and IoT Sensor AI Applications
Replicates sequential events like stock prices, ECGs, or IoT sensor logs.
Multimodal Data: How Combining Video, Speech, Image, and Text Simulates Complex Real-World AI Environments
A combination of two or more formats, such as video + speech or image + text, to simulate real-world environments.
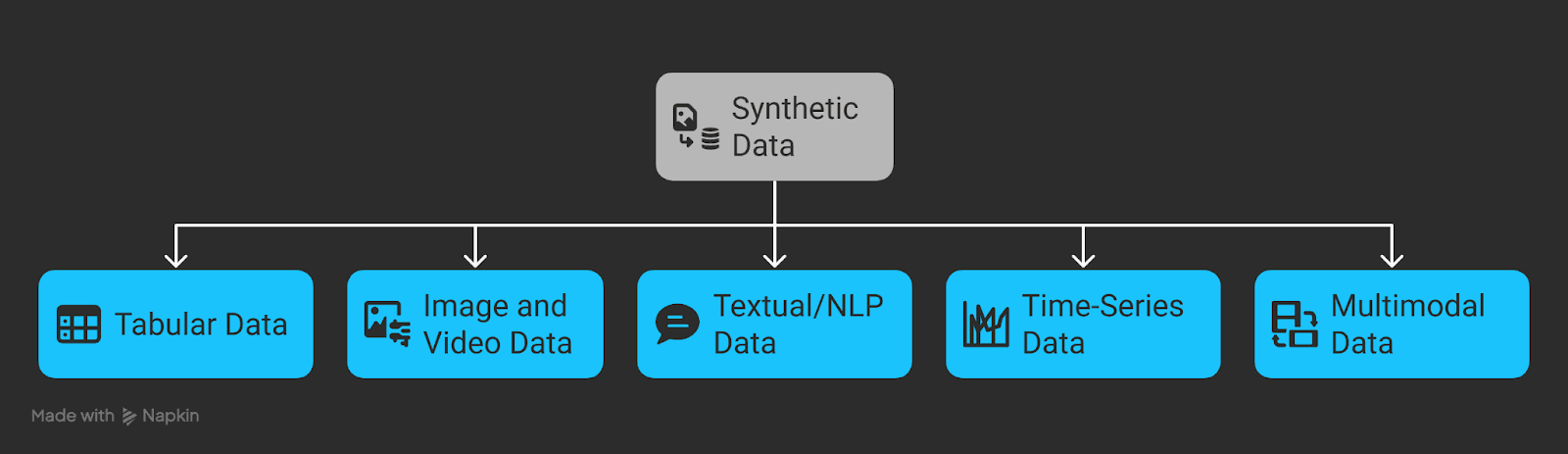
Image 1: Types of Synthetic Data
Why Synthetic Data Is Required: Privacy Protection, R&D Speed, Bias Reduction, Edge AI, and Cost Savings
“Synthetic data isn’t just an alternative - it’s the engine powering AI innovation under the hood.”
As AI becomes more widespread, the demand for clean, diverse, and privacy-safe datasets continues to grow. But collecting real-world data is slow, costly, and often restricted by laws like GDPR and HIPAA. That’s why synthetic data is emerging as a strategic solution, not just a workaround.
Here’s how synthetic data is reshaping the AI landscape:
- Protects Privacy: It mimics real data without containing any sensitive or personal information, making compliance with privacy laws much easier.
- Speeds Up R&D: Generate labeled data instantly, including rare edge cases, accelerating development timelines significantly.
- Reduces Bias: Synthetic datasets can be balanced across age, race, or class, helping models become more fair and inclusive.
- Optimizes for Edge AI: Virtual environments simulate diverse scenarios for devices like drones or smart cameras without field testing.
- Lowers Costs for Startups: It cuts down the need for expensive data acquisition and speeds up prototyping.
With regulatory pressures mounting and real-world datasets becoming harder to access, synthetic data isn’t just a convenience, it’s a necessity.
Top Five Synthetic Dataset Generator Tools in 2026: Features, Strengths, and Best Use Cases
Below are the most innovative tools in 2026, categorized by their strength in specific synthetic data types:
Future AGI: Best Multimodal Synthetic Data Generator for LLM Training, Agent Simulation, and Edge Deployment at Scale
- Category: Multimodal (Tabular, Text, Image, Agents)
- Designed for next-gen AI systems, Future AGI’s Synthetic Data Studio enables teams to generate evaluation datasets, agent simulation environments, and fine-tuning corpora across multiple modalities.
- Highlight: Built-in guardrails, evaluation-ready test sets, and agent data generation for LLMs and edge deployments. Ideal for enterprises and research labs building real-time, compliant, and explainable AI.
Image 2: Future AGI’s Synthetic Data Generation Dashboard
Gretel.ai: Best Privacy-First Generator for Tabular, Text, and Time-Series Data with Differential Privacy
- Category: Tabular, Time-Series, Text
- Gretel uses deep generative models with differential privacy to produce safe, realistic data for ML workflows.
- Highlight: API-first platform and open-source SDKs.
Image 3: Gretel.ai’s Synthetic Data Dashboard
MOSTLY AI: Best Enterprise-Grade Tabular Generator for GDPR and CCPA Compliant Financial and Insurance Datasets
- Category: Tabular
- Used by banks and insurers for highly accurate, compliant datasets.
- Highlight: GDPR/CCPA certified with exceptional statistical fidelity.
Image 4: Mostly AI’s Synthetic Data Dashboard
YData: Best Open-Source Tabular and Time-Series Synthesizer for Python Data Workflows and Research Labs
- Category: Tabular, Time-Series
- Built on CTGAN and Gaussian Copulas.
- Highlight: Excellent Python support and integrations with pandas.
Snorkel: Best Text and Semi-Synthetic Generator for NLP Labeling and Weak Supervision Pipelines
- Category: Text, Semi-Synthetic
- Automates labeling using weak supervision for faster NLP pipelines.
- Highlight: Used by Google, Apple, and top universities.
Side-by-Side Comparison: Data Type, Privacy, Enterprise Readiness, Customization, and Integration Across All Five Tools
| Tool Name | Data Type | Privacy Focus | Enterprise Ready | Customizable | Ease of Integration | Best For |
| Future AGI | Multimodal (Text, Image, Tabular, Agent) | ✅ Yes | ✅ Yes | ✅ Yes | API + SDK | Real-time agent simulation, test data pipelines, edge deployment |
| Gretel.ai | Tabular, Text, Time-Series | ✅ Yes | ✅ Yes | ✅ Yes | REST APIs, Python SDK | API-driven privacy-safe synthetic data |
| MOSTLY AI | Tabular | ✅ Yes | ✅ Yes | ❌ Limited | GUI + API | Financial and regulated data synthesis |
| YData | Tabular, Time-Series | ✅ Yes | ✅ Yes | ✅ Yes | Python-based, Jupyter-friendly | Python data workflows, research labs |
| Snorkel | Text, Semi-Synthetic | ❌ No | ✅ Yes | ✅ Yes | Python, Jupyter, API | NLP labeling and weak supervision |
Table 1: Side-by-side comparison table
How to Choose the Right Synthetic Data Generator Based on Your Use Case, Team Size, and Privacy Requirements
As privacy rules grow stricter and every AI project screams for more training data, synthetic data has stepped into the spotlight. Need millions of perfectly labeled images to teach a warehouse robot, or an anonymized banking dataset that keeps compliance happy?
Generators such as Future AGI, Gretel and MOSTLY AI, can whip them up in hours. These tools aren’t just stand-ins for real-world data - they’re pushing the limits of what you can imagine. The “right” generator depends on your use case, team size, and privacy bar. One thing’s clear, though: if you’re building AI in 2025, you’re almost certainly leaning on synthetic data - whether you realize it or not.
Kick-start your next project with Future AGI’s synthetic data generation app and generate compliant, production-ready datasets in minutes.
Frequently Asked Questions About Synthetic Data Generation Tools
What is synthetic data used for in AI training and model development workflows?
Synthetic data is used for training and testing AI models, validating analytics systems, and creating datasets where real data is unavailable, sensitive, or expensive.
Is synthetic data legal to use under privacy regulations like GDPR and HIPAA?
Yes, especially when it avoids using real user information. Most tools ensure compliance with laws like GDPR or HIPAA.
Can synthetic data match or exceed the performance of real-world data in AI training scenarios?
In many scenarios, yes. With proper modeling, synthetic datasets can match or exceed the performance of real-world data in AI training.
What free or open-source synthetic data generation tools are available for AI developers?
Yes! Tools like SDV, YData, Unity Perception, and Synthea are open-source and powerful enough for serious AI development.
Frequently asked questions
Q1: What is synthetic data used for?
Q2: Is synthetic data legal to use?
Q3: Can synthetic data be as good as real data?
Q4: Are there any free or open-source tools?

Learn how vector chunking works in AI in 2026. Covers definition, how it solves big data challenges, improved retrieval and scalability benefits, real-world.

Learn why voice agents fail in production and how to fix them with synthetic data, simulation & automated prompt optimization. Includes drive-thru case study.


Build a self-improving AI agent pipeline using open-source Simulate, Evaluate, and Optimize SDKs that catch tool-call bugs and rewrite your prompt automatically.