How to Stress-Test Your LLM Before It Fails in Production in 2026: Find Weak Spots Before Real Users Do
Learn how to stress-test LLMs before production failures in 2026. Covers five testing phases, key failure modes including hallucinations and prompt injection.

Table of Contents
Why LLMs That Pass Lab Tests Still Fail in Production and How Stress Testing Closes the Gap
Have you ever seen your LLM do great on every lab test, only to fail when real users came to it? What if you could find those weak spots, like latency spikes or bad prompts, before they cause a live outage?
Modern LLM demos often work well in controlled settings but not so well when put to the test in the real world, which can cause expensive outages. Stress testing takes your model past its “happy paths” to find failure modes that aren’t obvious. You won’t be able to see when throughput goes down when demand goes up or when token-throttling happens when the load is high. It helps you handle malformed JSON, unexpected tokens, and formatting issues in a smooth way. Stress tests that look for security holes can find prompt-injection holes that red teaming might miss. By automating these tests and adding them to CI/CD pipelines, you can find regressions early. You test both stability and safety under pressure by putting the system through hostile inputs and high traffic.
Key benefits include:
- Find latency spikes under load before your customers do.
- Find throughput bottlenecks that make scaling harder
- Expose adversarial weak spots like prompt injections.
- Check that errors are handled correctly when inputs are not what they should be.
- Make sure that performance stays the same when models are updated and APIs are changed.
This guide gives you a structured way to work, suggested tools, and best practices to avoid production failures. You will learn how to create, automate, and run stress tests that keep your LLM stable, safe, and working well in real life.
What Is LLM Stress Testing: How It Differs from Benchmarking and Why It Exposes Hidden Failure Modes
Stress testing puts a model through very hard situations to see how it breaks and how it gets better. It means running inputs or loads that are much higher than normal to find hidden ways that things can go wrong.
When you benchmark a model, you see how well it does on standard test sets so you can compare it to other models or older versions of itself. It reports metrics like accuracy, latency, or F1 under normal loads. Stress testing, on the other hand, intentionally increases concurrency or adds bad prompts to find breaking points that benchmarks never show.
Key Failure Modes and Threat Scenarios That LLM Stress Testing Must Cover
Hallucinations and Factual Drift: How Adversarial Prompts Expose Confident but Incorrect Model Outputs
- Complicated or linked questions can take the model down reasoning paths it wasn’t trained for, giving answers that sound right but aren’t.
- Adversarial prompts, like scenarios that are contradictory or out of scope, often show much higher rates of made-up content than simple tests do.
- Models sometimes make false statements with complete confidence, which makes it hard to automatically find mistakes.
Prompt Injection and Adversarial Manipulation: How Hidden Instructions Bypass Security and Leak Private Information
- Attackers can hide instructions that let them get around security measures or leak private information.
- Dynamic scripts that combine system and user prompts can find small ways to escape that static tests miss.
- Once one prompt injection works, other ones usually come along quickly, so tests need to keep changing.
Performance Under Load and Latency Spikes: How Burst Traffic Overwhelms Resources and Causes Timeouts
- A lot of requests at once push p95/p99 latency up a lot, which makes real-time apps run slower.
- Effects of burst traffic
- When there are sudden spikes in users or batch jobs, the CPU and GPU resources can get overwhelmed and cause timeouts.
- You need to check that the system can handle heavy loads and still return cached results or error messages.
Safety, Bias, and Offensive Content: How Edge-Case Inputs Slip Past Guardrails and Reveal Demographic Bias
- Even inputs that look friendly can be turned into hate speech if guardrails don’t catch slang, typos, or edge-case slang.
- Models may favor or disfavor some groups unless you test them with a mix of names, dialects, and cultural references that is fair.
- Make sure that safety filters still work when the model gets the user’s intent wrong or sees mixed signals.
Format and Output Consistency: How Unexpected Tokens and Malformed JSON Break Downstream Parsers
- Unexpected tokens or line breaks can make parsers choke when they expect strict schemas.
- Serializing a response, then parsing it back should yield the same structure test this under malformed-input pressure.
- If you rely on code generation, verify syntax and ensure missing imports or mis-indented blocks get caught.
//Try this: pick one of these failure modes and write a quick test that bombs your app then you know exactly where to shore up your defenses.//
The Five-Phase LLM Stress Testing Pipeline: From Input Creation to CI/CD Integration
Step 1: How to Create the Hardest Test Inputs Using Synthetic Data Pipelines and Manual Outlier Review
You begin by collecting a variety of difficult prompts that test your model to its limits, including rare corner cases, adversarial twists, and more. Use synthetic data pipelines to quickly make examples in many different fields. For example, Ragas’ test-set generator can get domain-specific prompts straight from your documents. Future AGI Dataset and Hugging Face’s Synthetic Data Generator can also make thousands of variations at once. Don’t skip a manual pass; look for strange prompts that automation might miss to make sure you cover every edge.
- Use Ragas modules to create different adversarial prompts in each area.
- Use high-volume synthetic generators like Future AGI to get a lot of data.
- Check outliers by hand to find corner cases that get missed.
Step 2: How to Automate Scoring with BLEU, ROUGE, Embedding Distance, and Factuality Checks Against a Knowledge Base
Next, use a set of automated tests to find out exactly where your model fails when you run those prompts. Use BLEU and ROUGE to compare outputs, measure embedding distance to find semantic drift, and run targeted factuality tests against a trusted knowledge base.
- For each batch, find the BLEU, ROUGE, and embedding distance scores.
- Check answers against KB entries to find drift
Step 3: How to Compare Providers by Running the Same Test Cases Through GPT-4, Claude, and Mistral
You can test your test suite by running the same cases through a few LLMs, like GPT-4, Claude, and Mistral, and seeing which one breaks first. Put all of your metrics on the same scale so you can compare models by how often they fail, how long it takes for an adversary to respond, and how many hallucinations they have. This comparison makes it easier for you to choose the best engine for each job by showing what each model is good at and what it isn’t.
- Do the same tests on the APIs for GPT-4, Claude, and Mistral.
- Make sure the scores are the same so you can compare them fairly.
- Rank and keep track of trends in model reliability to help you choose a model.
Step 4: How to Simulate Real-World Load Using Gatling and Locust to Measure P95 and P99 Latency Under Burst Traffic
It’s time to fill your APIs with simulations of real traffic. You can use tools like Gatling or Locust to make multiple calls at once and keep track of your p50, p95, and p99 response times, as well as your error rates and CPU/GPU usage. Find the traffic level at which timeouts or resource bottlenecks start to happen, and then check your fallback plans-cached outputs, asynchronous hybrids, or whatever else you’ve made-to make sure they work when things get tough.
- Script burst traffic situations and measure p50, p95, and p99 latencies
- Keep an eye on error rates and how resources are being used during peak times.
- Check that fallback mechanisms (like cached results and hybrid async) work when things get tough.
Step 5: How to Integrate Stress Tests into CI/CD Pipelines with Live Monitoring and Automated Regression Alerts
Finally, set up live monitoring and add these stress tests to your CI/CD workflow. Check pull requests, so that no code goes live until it passes your stress suite. Add your logs to Future AGI. You can get alerts in real time about drift, strange behavior, or performance drops. With this in place, you will be able to see regressions right away.
- Add Promptfoo CI/CD hooks so that stress suites run automatically on every PR.
- Use dashboards of Future AGI Observe to find problems as they occur.
/The next step is to pick one phase, do a quick smoke test today, and then move on from there./
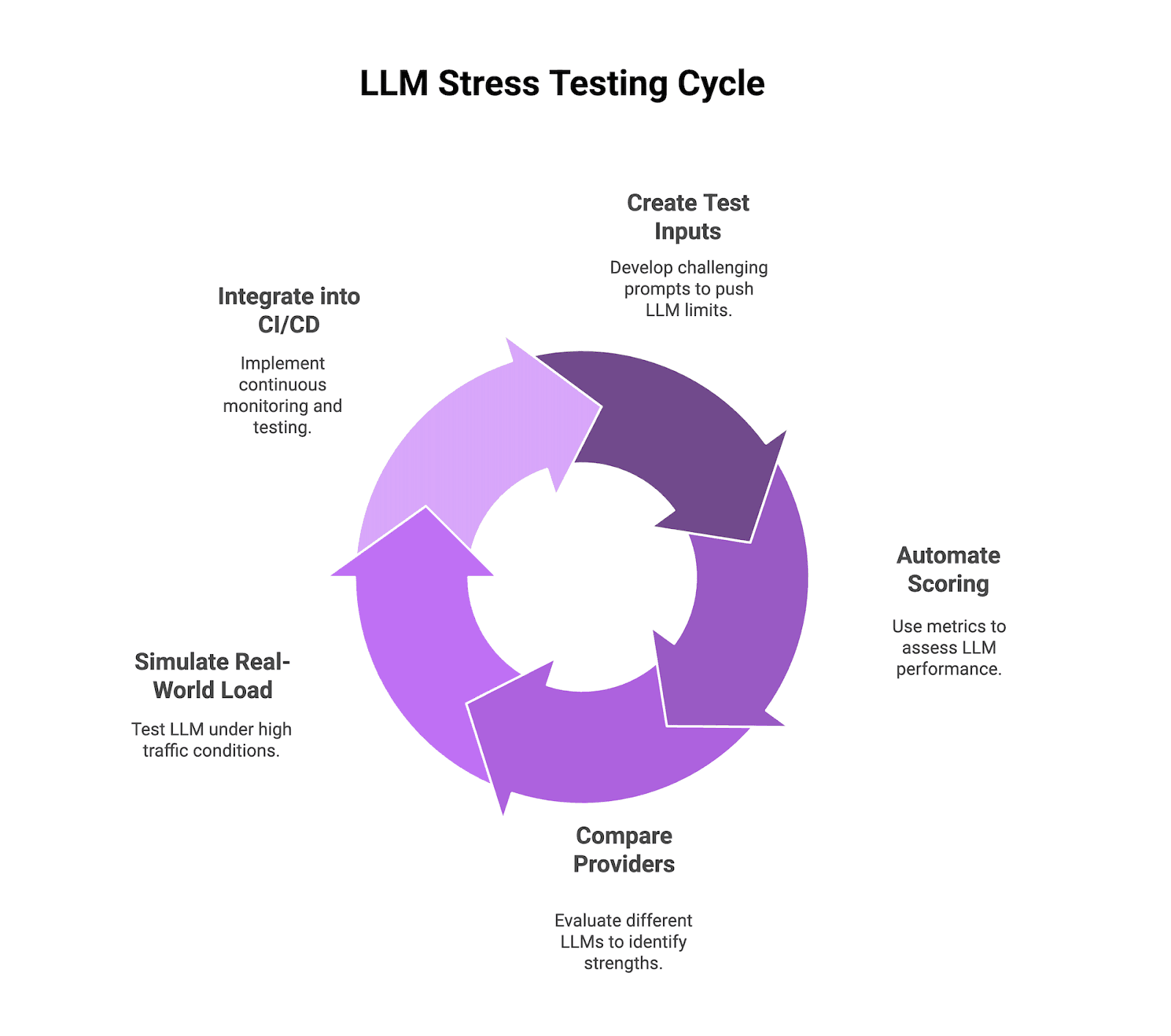
Figure 1: 5-Phase LLM Stress Testing Pipeline
Open-Source and Commercial LLM Stress Testing Tools: Future AGI, LangChain Evals, Promptfoo, Ragas, DeepEval, and More
Future AGI (Observe | Eval | Protect)
- A single platform that takes care of safety, evaluation, and observability from start to finish.
- Live dashboards give you safety metrics and insights, and they automatically block unsafe outputs without slowing you down.
- There are built-in evaluation chains for BLEU, ROUGE, embedding-based similarity, and your own custom metrics.
- Easy integration: plug these checks straight into your workflows so everything’s automatically scored.
- Custom probes and red-teaming scripts to surface LLM vulnerabilities.
- Hooks into your CI/CD pipeline to prevent merges until security and quality gates pass.
- Automated, end-to-end evaluation workflows that spin up domain-specific test sets from your own documents.
- Synthetic data generators to fill in corner cases and guard against data drift.
- Think of it as “Pytest for LLMs,” with unit-test style checks tracking hallucinations, relevance, and more.
- Built-in performance and regression modules flag slowdowns or accuracy drops over time.
- You can run code-driven load tests with Gatling and see full breakdowns of response times, error rates, and throughput.
- Locust scripts that send millions of fake users to your system to make it seem like a lot of people are using it.
- CI/CD has built-in drift detection and monitoring, so you’ll be told right away if there are any changes in data or performance.
- Keeping an eye on the health of your models in real time can help them run smoothly.
Comparison Table: Features, Ideal Use Cases, and When to Use Each LLM Stress Testing Tool
| Tool | Features | Ideal Use Case | When to Use |
| Future AGI | End-to-end evals; live observability; safety modules for blocking unsafe content | Organizations needing a single platform for testing, monitoring, and content protection | From initial model evaluation through production monitoring and incident response |
| LangChain Evals | Prebuilt eval chains (BLEU, ROUGE, custom metrics); easy integration into code | Developers building LangChain apps who want quick metric checks | During development for automated scoring of chain outputs |
| Promptfoo | LLM vulnerability scanner; red-teaming probes; CI/CD hooks | Security-focused teams aiming to lock down prompt-injection and other exploits | Before deployment, and as part of every code merge |
| Ragas | Automated RAG testset generation; end-to-end evaluation workflows | Retrieval-augmented generation pipelines requiring broad coverage of document formats | When you need to build or refresh adversarial test datasets |
| DeepEval | “Pytest for LLMs”; unit, performance, regression, and responsibility tests | Teams wanting fine-grained, test-driven validation of individual model responses | Incorporating LLM checks into existing test suites |
| Gatling / Locust | High-concurrency API load simulation; p50/p95/p99 latency, error rates, resource metrics | Ops teams validating infrastructure capacity and autoscaling rules under peak demand | When preparing for known traffic surges or verifying fallback strategies |
| Arize AI | CI/CD integration; drift tracing; anomaly alerts; model health dashboards | ML teams tracking data and prediction drift in production | For continuous monitoring post-deployment, with automated regression alerts |
Table 1: Open-Source and Commercial Tools Comparision
Future AGI is the best choice for all-in-one LLM stress testing and reliability assurance because it has everything you need: evaluation, live monitoring, and real-time safety.
How Pre-Deployment Stress Testing Prevents Hallucinations, Prompt Injection, and Costly Production Outages
Pre-deployment stress testing makes sure that your model is reliable, keeps outputs safe, and helps you follow the rules and laws of your industry. You can avoid real-world failures that damage trust and lead to penalties by catching hallucinations, prompt injections, and slowdowns early. Automated, CI-integrated pipelines make sure that every update passes your own high standards before you send it out. Observability platforms give live dashboards and alerts, letting you spot drifts or policy breaches before customers do. Skipping these steps leaves hidden gaps that can lead to costly outages, biased outputs, or compliance failures down the line.
Want to make sure your LLM doesn’t hallucinate during a customer interaction? Explore Future AGI’s Eval & Protect suite to build resilient GenAI applications before it’s too late.
Frequently Asked Questions About LLM Stress Testing and Production Reliability
What does LLM stress testing mean and how does it differ from standard model benchmarking?
LLM stress testing uses bad inputs, heavy loads, and adversarial prompts to deliberately push a language model past its normal limits. This helps find problems like hallucinations, latency spikes, or security holes before they happen in production.
Why is stress testing essential before deploying a large language model to real users?
Stress testing helps you find problems with reliability, safety, and performance early on, like throughput bottlenecks, prompt-injection vulnerabilities, and factual drift. This lowers the risk of expensive outages, biased outputs, or compliance failures when real users start using your model.
What are the main phases of a robust LLM stress testing pipeline from input creation to monitoring?
A strong pipeline usually has the following: making hard adversarial prompts and curated datasets, running automated metric-driven evaluations, comparing models, simulating load and concurrency, and adding tests to CI/CD with constant monitoring.
When should stress tests be integrated into CI/CD pipelines for continuous LLM quality assurance?
You should connect stress-testing suites to pull-request checks and deployment stages so that every time you change code, tests run automatically and any regressions or safety breaches are flagged before the new build goes live.
Frequently asked questions
Q1: What does it mean to do LLM stress testing?
Q2: Why do I need to stress-test my LLM before I use it?
Q3: What are the main steps in a stress-testing pipeline for an LLM?
Q4: When should I add stress tests to my CI/CD pipeline?

Build production-grade voice AI evaluation in 2026. Covers STT, LLM & TTS metrics, five evaluation layers, synthetic testing frameworks, and key pitfalls to avoid.


Compare OpenAI Frontier and Claude Cowork in 2026. Covers agent execution, governance, security, ecosystem openness, and which platform suits your needs.


Learn how engineering teams embed AI safety in 2026. Covers CI/CD guardrails, model drift detection, adversarial robustness, monitoring & safety-first culture.