LLM Reasoning in 2026: o3, GPT-5, Claude 4.7 Extended Thinking, DeepSeek R1, and Evaluation
How LLM reasoning works in 2026: o3, GPT-5 thinking, Claude 4.7 extended thinking, DeepSeek R1, chain-of-thought, tree-of-thoughts.

Table of Contents
LLM Reasoning in 2026: o3, GPT-5, Claude 4.7 Extended Thinking, DeepSeek R1, and Evaluation
LLM reasoning is the ability to digest information logically, solve multi-step problems, and draw valid conclusions. In 2026 the reasoning gap that defined 2023 and 2024 LLMs has narrowed sharply. OpenAI shipped o1, o3, and o4-mini. The GPT-5 family added reasoning effort controls. Anthropic shipped Claude 4.x with extended thinking. Google released Gemini 2.5 Pro thinking. DeepSeek released R1 with open weights and continues to iterate on the family. This guide covers the leading reasoning models, the techniques behind them (chain-of-thought, tree-of-thoughts, RLHF variants, MCTS), and how to evaluate reasoning quality in production.
TL;DR: Reasoning LLMs in May 2026
| Model | Reasoning mode | License | Open weights | Strongest at |
|---|---|---|---|---|
| OpenAI o3 / o4-mini | Private reasoning tokens | Closed | No | Hardest math, code, science |
| GPT-5 family | Reasoning effort control | Closed | No | General reasoning with cost dial |
| Claude 4.7 | Extended thinking (budget) | Closed | No | Long analysis, code review |
| Gemini 2.5 Pro | Thinking mode | Closed | No | Multimodal reasoning, long context |
| DeepSeek R1 | Visible reasoning trace | MIT | Yes | On-prem, cost-sensitive deployments |
| Qwen3 thinking | Configurable thinking | Apache 2.0 (varies) | Yes | Open-weight reasoning |
| Llama 4.x reasoning | Reasoning mode | Llama license | Weights available | Open-weight ecosystem fit |
Why LLM Reasoning Was Hard Before 2025
Pre-2025 LLMs were trained almost entirely on next-token prediction, which made them fluent at translation, summarization, and Q&A but brittle on tasks that require deliberate multi-step inference. The fluency was real and the gap was real: GPT-4 could write a novel paragraph but stumble on a fourth-grade word problem when arithmetic was non-trivial. Researchers responded with three classes of fix: prompt-time techniques like chain-of-thought, reinforcement learning over reasoning traces, and dedicated reasoning models like o1 that allocate extra inference compute by design.
Reasoning Techniques That Improved LLM Inference
Chain-of-Thought (CoT) Prompting
Chain-of-thought, introduced by Wei et al. in arXiv:2201.11903, asks the model to write intermediate steps before answering. The simplest version appends “Let’s think step by step” (zero-shot CoT, Kojima et al. arXiv:2205.11916) to the user prompt. On models above roughly 60 billion parameters, CoT consistently improves math, logic, and multi-hop QA accuracy. For a deeper walkthrough see chain-of-thought prompting in 2026.
ReAct: Reasoning Plus Acting
ReAct (Yao et al., arXiv:2210.03629) interleaves reasoning steps with tool calls. The model writes a thought, takes an action (search, calculator, API call), observes the result, and updates the next thought. ReAct is the foundation of modern agent frameworks because it grounds the reasoning chain in real-world tool output.
Self-Reflection and Critique Loops
Reflexion (Shinn et al., arXiv:2303.11366) and self-critique patterns ask the model to evaluate its own output and try again. The model checks its prior answer, identifies errors, and produces a revised answer. Multi-pass self-reflection improves accuracy on hard problems but multiplies cost and latency.
Tree-of-Thoughts
Tree-of-thoughts (Yao et al., arXiv:2305.10601) generalizes chain-of-thought to a search tree. The model expands multiple reasoning branches, scores them with a value function or vote, and explores the most promising path. The technique helps on combinatorial tasks like Game of 24 and creative writing. Reasoning models can learn search-like behavior and allocate test-time compute to similar effect without an explicit external search loop.
Knowledge Graph Augmentation
Pairing an LLM with a structured knowledge graph (entities, relations, properties) gives the reasoning chain a precise context for entity-heavy queries. The model reads structured triples, decides which path to traverse, and grounds its answer. Useful for biomedicine, legal, and enterprise-search domains where free-text retrieval misses entity relationships.
How OpenAI o1, o3, GPT-5, Claude 4.7, and DeepSeek R1 Pushed Reasoning Forward
OpenAI o-series and GPT-5 Reasoning Effort
OpenAI’s reasoning track began with o1 (released September 2024), continued with o3 and o4-mini (April 2025), and merged into the GPT-5 family which added a reasoning-effort parameter so callers can dial up or down the internal thinking budget per request. The reasoning steps are kept private by default but billed as reasoning tokens. See the OpenAI model and pricing pages for current options.
Claude 4.x Extended Thinking
Claude 4 launched with extended thinking and Claude 4.7 refined it. Callers configure a thinking-tokens budget per the Anthropic API docs at docs.anthropic.com; depending on model and settings, the API may surface a thinking content block alongside the final answer. Standard responses without extended thinking typically run at lower latency than extended-thinking calls. Hard math, code review, and analysis tasks improve with larger thinking budgets.
DeepSeek R1
DeepSeek R1 (released January 2025, MIT licensed weights on Hugging Face) demonstrated that pure RL over reasoning traces with the GRPO algorithm could match o-series-level accuracy on math and code benchmarks, without supervised fine-tuning. R1 is the strongest open-weight reasoning baseline in 2026 and ships with a visible reasoning trace.
Gemini 2.5 Pro Thinking
Google released Gemini 2.5 Pro with a thinking mode that runs a deliberate reasoning pass before answering. The Gemini reasoning track is most useful when long context (up to 2M tokens) and multimodal inputs (image, video, audio) are part of the reasoning chain.
Reasoning Algorithm Foundations: RLHF, PPO, DPO, GRPO, MCTS
Reinforcement Learning from Human Feedback (RLHF)
RLHF replaces a brittle supervised target with a reward signal that captures human preferences. A reward model is trained on pairwise preference data; then a policy is fine-tuned to maximize the reward. The classic algorithm is PPO (Proximal Policy Optimization, Schulman et al. arXiv:1707.06347).
Direct Preference Optimization (DPO)
DPO (Rafailov et al. arXiv:2305.18290) skips the explicit reward model. It trains the policy directly on pairwise preferences with a closed-form loss. Cheaper than PPO and often as good or better on standard RLHF benchmarks.
Group Relative Policy Optimization (GRPO)
GRPO (introduced by DeepSeek in DeepSeekMath, arXiv:2402.03300) normalizes rewards within sampled groups, which lowers variance and removes the need for a separate value model. DeepSeek R1 was trained with GRPO at scale.
Monte Carlo Tree Search (MCTS)
MCTS models a tree of future reasoning paths through four steps: select the most promising node, expand with new candidate moves, simulate outcomes along each branch, and back-propagate the simulation result to update node values. MCTS gives the LLM structured planning and is one of the inference-time techniques that contributed to AlphaGo-style breakthroughs in board games and now in math reasoning (e.g., AlphaProof).
Taxonomy of LLM Reasoning Strategies
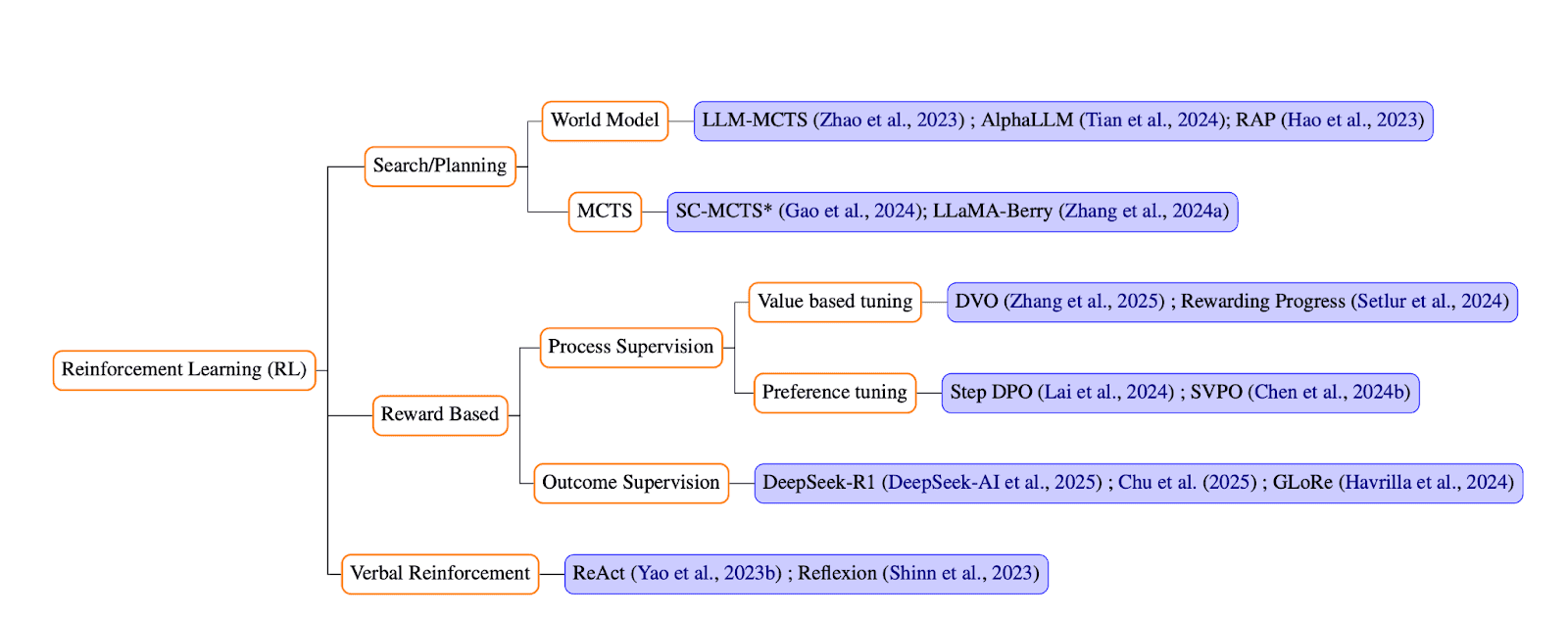
Reinforcement Learning Paradigm
- Verbal reinforcement. Systems like Reflexion and ReAct produce reasoning chains, receive natural-language feedback, and iterate.
- Reward-based reinforcement. Process supervision scores intermediate steps; outcome supervision scores only the final answer. Algorithms include PPO, DPO, and GRPO.
- Search-and-planning hybrids. RL policies combine with tree search (MCTS) to explore new actions while honoring tried routes.
Test-Time Compute Paradigm
- Feedback-guided improvement. Step-level verifiers score partial answers; tree search prunes weak branches. Outcome verifiers (like CodeT for code) rerank final responses.
- Self-consistency. Generate multiple chains, take a majority vote, return the modal answer. Simple and effective on math and QA.
- Forest-of-Thought and parallel sampling. Multiple independent reasoning paths run at once and the outputs are reconciled.
Self-Training Paradigm
- Bootstrapping with generated traces. Models produce chain-of-thought responses, the best are kept, the model retrains on them. STaR (Zelikman et al. arXiv:2203.14465) is the canonical reference.
- Self-consistency and ensemble methods. Generate, vote, retrain. Reduces variance and improves reliability over many cycles.
Benchmark Spotlight: DeepSeek R1, o3, GPT-5, Claude 4.7 on Reasoning Tasks
For current numbers consult the official model release pages and independent leaderboards (Artificial Analysis, lmarena, OpenCompass). As of May 2026, reasoning models have reported strong scores on:
- AIME (American Invitational Math Exam). o3 and DeepSeek R1 have reported high pass-at-k scores on AIME 2024.
- GPQA Diamond (graduate-level science). o3 and Claude 4.7 extended thinking have reported strong results; check vendor model cards for current numbers.
- SWE-bench Verified (real GitHub issue fixes). Claude 4.x with agentic loops and Gemini 2.5 Pro thinking have reported leading scores.
- Codeforces. o3 and DeepSeek R1 have reported competitive-programmer Elo ranges per official write-ups.
Benchmark numbers move every quarter, so always confirm against the model card before quoting in production decisions.
Persistent Challenges in LLM Reasoning
Process-Supervision Labels Remain Expensive
Step-level labels for process supervision are still costly because they require domain experts and they do not scale automatically. Synthetic process labels can fill the gap but introduce label noise.
Tree Search Inflates Latency and Cost
MCTS and tree-of-thoughts multiply inference compute. A single deliberation pass on a frontier reasoning model can cost ten to one hundred times a standard completion. Budget accordingly.
Reasoning Models Can Overthink
Reasoning models can talk themselves into wrong answers on easy problems by spending too much thinking compute. OpenAI documents that o3 and o4-mini sometimes do worse than GPT-4o on simple factual recall.
Small Models Still Lag
Chain-of-thought offers substantial gains on models above roughly 60 to 100 billion parameters. Models below 10 billion parameters see little or no CoT benefit, which limits reasoning deployment on edge and constrained devices.
Pre-Training Quality Sets the Ceiling
RL over reasoning traces cannot save a weak base model. Strong reasoning still requires strong pre-training, and the data scaling story has not gone away.
How to Evaluate LLM Reasoning Quality
Reasoning has two dimensions: did the model reach the right final answer, and is the reasoning chain itself coherent and grounded. Production evaluation covers both.
Final-Answer Accuracy
Score the final answer against ground truth on a held-out benchmark. AIME, GSM8K, MATH, GPQA, BIG-Bench Hard, and ARC are the standard ones. Pair with task-specific benchmarks for your domain (SWE-bench for code, HumanEval for code generation, MedQA for medicine).
Reasoning Chain Coherence
Score the chain itself for logical consistency, step relevance, and faithfulness to source material. LLM-as-a-judge metrics are the standard tool. Future AGI ships these as part of the fi.evals catalog, which includes faithfulness, coherence, and step-level relevance evaluators backed by turing_flash (about 1-2 seconds cloud latency), turing_small (about 2-3 seconds), or turing_large (about 3-5 seconds).
# Requires: pip install ai-evaluation (ai-evaluation: Apache 2.0)
# Env: FI_API_KEY, FI_SECRET_KEY
from fi.evals import evaluate
reasoning_trace = (
"Step 1: list the constraints. "
"Step 2: apply Bayes' rule with P(A|B) = P(B|A)P(A)/P(B). "
"Step 3: numeric solve gives 0.42. "
"Final answer: 0.42."
)
question = "Given P(A)=0.3 and P(B|A)=0.7 and P(B)=0.5, compute P(A|B)."
# Score the trace for faithfulness to the source question
result = evaluate(
"faithfulness",
output=reasoning_trace,
context=question,
model="turing_flash",
)
print(result.score, result.reason)For broader evaluation tool reviews see best LLM evaluation tools in 2026 and LLM evaluation frameworks and metrics.
Tracing Reasoning Steps in Production
Use Apache 2.0 traceAI to instrument reasoning calls and capture the thinking tokens, tool calls, and final answer in a tracing dashboard. The same OpenInference spans surface inside the Future AGI Agent Command Center at /platform/monitor/command-center so you can see latency, cost, and reasoning-chain quality across every request.
# Requires: pip install traceai-openai
# Env: FI_API_KEY, FI_SECRET_KEY
from fi_instrumentation import register, FITracer
from fi_instrumentation.fi_types import ProjectType
from openai import OpenAI
trace_provider = register(
project_type=ProjectType.OBSERVE,
project_name="reasoning-evals",
)
tracer = FITracer(trace_provider)
client = OpenAI()
with tracer.start_as_current_span("reasoning_call") as span:
response = client.chat.completions.create(
model="o3-mini",
messages=[{"role": "user", "content": "Prove sqrt(2) is irrational."}],
)
span.set_attribute("llm.model", "o3-mini")How Reinforcement Learning, Test-Time Compute, and Self-Training Move LLMs Toward Genuine Reasoning
The three paradigms compose. Reinforcement learning over reasoning traces (DeepSeek R1, OpenAI o-series training) builds models that reason by default. Test-time compute (extended thinking, self-consistency, MCTS) scales accuracy at inference. Self-training (bootstrapped CoT data, STaR) closes the loop by feeding model-generated traces back into training. Each lever is independently useful, and the best 2026 reasoning systems use all three.
Where this leaves teams in 2026: pick a reasoning model that matches your latency and cost budget, instrument the reasoning chain with traceAI, and score both final answers and reasoning coherence with fi.evals. Then iterate.
Summary: How to Pick a Reasoning Model and Evaluate It in 2026
For closed APIs, o3 and GPT-5 with reasoning effort lead on the hardest math and code tasks. Claude 4.7 extended thinking leads on long analysis and code review. Gemini 2.5 Pro thinking leads on multimodal and very-long-context reasoning. For open weights, DeepSeek R1 is the strongest baseline, followed by Qwen3 thinking and Llama 4.x reasoning. Evaluate every choice with both ground-truth benchmarks and chain-coherence judges before committing to production.
Frequently asked questions
What are the leading reasoning LLMs in 2026?
What is chain-of-thought prompting?
What is tree-of-thoughts?
How does Claude extended thinking work?
How does DeepSeek R1 compare to OpenAI o3?
What is test-time compute?
How do you evaluate LLM reasoning quality?
What is the difference between PPO, DPO, and GRPO?

Gemini 3.5 Flash dropped today at Google I/O 2026. The 8 benchmark numbers that matter, $1.50/$9 pricing breakdown, and what to instrument before you swap.


Compare GPT-5, Claude Opus 4.7, Gemini 2.5 Pro, and Grok 4 on GPQA, SWE-bench, AIME, context, $/1M tokens, and latency. May 2026 leaderboard scores.


Compare top AI guardrail tools in 2026: Future AGI, NeMo Guardrails, GuardrailsAI, Lakera Guard, Protect AI, Presidio. Coverage, latency, how to choose.