How Multimodal Large Language Models Work in 2026: Architecture, Training, and Real-World Applications
Learn how multimodal large language models work in 2026. Covers LLaVA, NVLM 1.0, Pixtral Large, BLIP-2, and OpenFlamingo architectures, training strategies.

Table of Contents
How Multimodal LLMs Combine Text, Images, and Audio to Mirror Human Intelligence
Do you know how your smartphone can explain an image or how virtual assistants understand your words and images? This is achieved by the analysis and integration of many data kinds, including text, pictures, and audio, using multimodal large language models (LLMs). How do these models seamlessly integrate various data categories to improve our interactions with technology?
Multimodal Large Language Models are advanced AI systems that are capable of understanding and generating content across a variety of data categories, such as text, images, and audio. These several modes provide a more complete knowledge and interaction by closely reflecting human intellectual abilities and help to integrate them. In 2025, the need for these kinds of models has grown because there is so much data in so many forms and AI needs to be able to connect with humans more naturally. Enhanced virtual assistants can understand and respond to visual signals, and advanced content production tools merge text, graphics, and voice. This development represents a transition to more efficient and intuitive human-computer interactions, which are designed to fit the increasing complexity of user requirements.
Real-World Multimodal LLM Applications Across Robotics, AI Assistants, and Content Creation
Many sectors are using multimodal LLMs to create and enhance customer experiences:
- Autonomous systems and robotics: NVIDIA’s NVLM 1.0 is a free and open-source multimodal LLM that can process tasks involving both text and vision. It improves autonomous systems’ capacity to understand and engage with their surroundings.
- AI Assistants: Meta’s Llama 3.2 is an open-source AI model that is capable of parsing both text and images, which allows more interactive and versatile AI assistants.
- Content Creation: Google’s Gemini models are multimodal, capable of managing text, audio, and video in addition to images, which allows the development of complex content creation and modifying tools.
In this blog will discuss Multimodal Large Language Models and several important open-source examples, showing their effect across sectors and their importance in the present technological landscape.
What Is Multimodality in AI: How Input Modules, Fusion Modules, and Output Modules Work Together
A “modality” in AI is the unique kind of data that an AI system can handle, including text, pictures, audio, or video. Each modality provides distinctive information; for example, text conveys linguistic content, images offer visual details, and audio captures sound complexities. The integration of multiple modalities by AI systems can result in a more comprehensive understanding of information, which in turn leads to more accurate and versatile applications. This multimodal method enables AI to comprehend and create information that closely resembles human experiences, which enhances interactions and decision-making processes.
How Multimodal LLMs Work
Multimodal Large Language Models (LLMs) are intended to generate and process content across a variety of data categories, such as text, images, and audio. In general, they are made up of several essential elements:
- Input Modules: Multiple neural networks are responsible for processing various data types, including audio, images, and text. The appropriate characteristics are extracted by each network based on its unique modality.
- Fusion Module: This component develops the processed information from each modality, ensuring that it is unified and captures the relationships and context between the various data categories.
- Output Module: This module generates the ultimate output, which can be text, an image, or another type of data, based on the integrated data.
For example, the model’s vision encoder processes the image to generate visual features in an image captioning task. These features are then transformed to a format that is compatible with the language model. The visual features of the image are used by the language model to generate a textual description, which is a cogent caption that accurately reflects the content of the image.
Multimodal LLMs can do complicated tasks that need to understand and create multiple types of data by mixing these parts in a smart way. This makes exchanges between humans and computers more natural and effective.
We now have a general idea of what Multimodal LLM is and how it works. We will look at the architecture of several open-source multimodal LLMs.
LLaVA: How the Large Language and Vision Assistant Combines Vision Encoders with Language Models
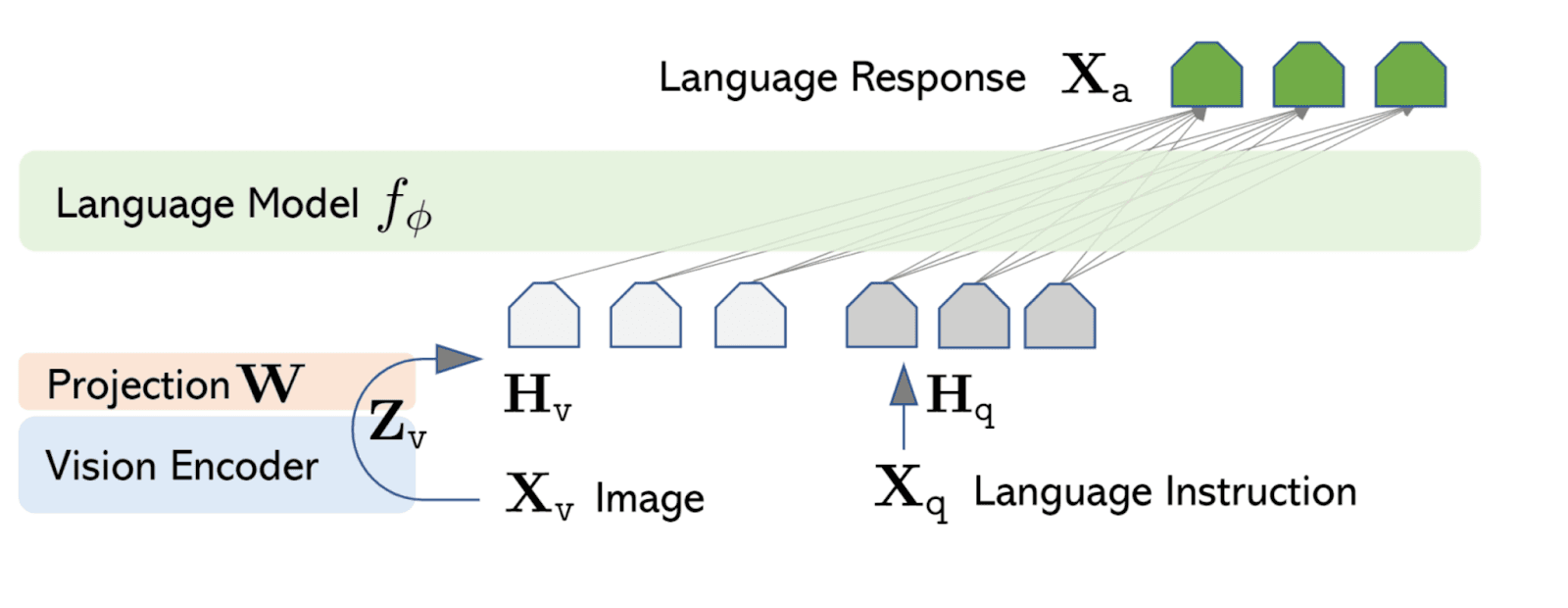
LLaVA (Large Language and Vision Assistant) is a cutting-edge multimodal AI model that incorporates visual perception capabilities with advanced language understanding. LLaVA produces seamless processing and creation of both textual and visual information by merging a vision encoder with a large language model (LLM). This integration lets the model handle tasks like interactive dialogues using text and images, visual question answering, and thorough image explanations. LLaVA was created with open-source frameworks and prioritizes community participation and accessibility, promoting progress in multimodal AI research and applications. The design and training strategies of the model are specifically designed to expand the capabilities of conventional language models by incorporating visual context, thereby improving their real-world applicability and versatility.
Architecture Details
The architecture of LLaVA effectively combines components of visual and linguistic processing:
- Vision Encoder: Extracts visual features from images using a pre-trained CLIP (Contrastive Language–Image Pre-training) model, specifically the ViT-L/14 (Vision Transformer) variant.
- Language Model (LLM): Vicuna, a large language model built on LLaMA (Large Language Model Meta AI), is integrated into the Language Model (LLM) to manage activities related to natural language processing and creation.
- Linear Projection Layer: A two-layer ReLU-activated Multi-Layer Perceptron (MLP) functions as a connector, converting the high-dimensional visual embeddings from the vision encoder into a token space that is compatible with the LLM. This approach makes sure that the visual and textual data combine together smoothly.
- Cross-Attention Mechanism: Enhances context-aware responses by enabling the model to focus on relevant components of the visual input during the generation or interpretation of text to integrate image and text features.
This architecture enables LLaVA to effectively process and generate multimodal content by using the assets of both visual and language models.
Training Strategies
LLaVA implements a two-stage training procedure to effectively align and refine its multimodal capabilities:
Stage 1 - Pre-training for Feature Alignment:
Objective: Ensure that the visual and textual feature spaces are in alignment to enable the seamless integration of the two.
Method: The vision encoder and LLM are locked and the linear projection layer (connector) is trained on a subset of the CC3M (Conceptual Captions) dataset. This method ensures consistent mapping of visual embeddings to the token space of the LLM.
Stage 2 - Fine-tuning End-to-End:
Objective: Improve the model’s efficacy on particular multimodal tasks.
Method: Use curated multimodal instruction-following datasets to optimize both the connector and the LLM. Two situations are taken under consideration:
- Visual Chat: Enhance daily user-oriented applications by using generated multimodal instruction-following data.
- Science QA: Customize the Science QA dataset to improve multimodal reasoning capacity in scientific environments.
- This structured training process ensures that LLaVA acquires the ability to effectively integrate and use visual and textual information for a variety of applications.
Performance
LLaVA implements multiple innovations that optimize its functionality in a variety of multimodal tasks:
- Data Efficiency: Establishes the efficient use of training data, achieving state-of-the-art performance using publicly available datasets.
- Training Efficiency: Successfully completes training on a single 8-A100 node in approximately one day, showing an optimized training process that does not sacrifice performance.
- Benchmark Performance: Outperforms methods that use billion-scale data, achieving state-of-the-art accuracy on 11 benchmarks.
These advancements make LLaVA a premier multimodal AI model that integrates visual and understanding languages efficiently.

NVIDIA NVLM 1.0: How MLP Projectors and Tile-Tagging Enable High-Resolution Multimodal Reasoning
A suite of sophisticated multimodal large language models (LLMs) known as NVIDIA’s NVLM 1.0 is engineered to seamlessly integrate visual perception with language comprehension. The objective of NVLM 1.0 is to achieve excellence in tasks that require the processing of both text and images by integrating cutting-edge vision and language models. The capacity of NVLM 1.0 to improve text-only performance after multimodal training is an important feature. This feature addresses a common challenge in which the integration of multiple data types can degrade language capabilities. NVLM 1.0 is now positioned as a model that is adaptable and can handle a diverse range of applications, including complex reasoning tasks and visual question answering.
Architectural Design
The architecture of NVLM 1.0 is designed to efficiently process and align visual and textual information using state-of-the-art components:
Vision Encoder: Uses the InternViT-6B-448px-V1-5 model, a Vision Transformer (ViT) variant, to extract high-resolution visual features from images.
Language Backbone: Uses Qwen2-72B-Instruct as the language model backbone, which offers comprehensive natural language understanding and generation capabilities.
Modality-Alignment Modules:
- MLP Projectors: Visual embeddings are mapped into a token space that is compatible with the language model using Multi-Layer Perceptron (MLPs) in MLP projectors, which enables the seamless integration of visual and textual data.
- Tile-Tagging Mechanism: Introduces a dynamic high-resolution input processing technique that divides images into tiles, each of which is tagged with textual descriptors. This method boosts performance on tasks including optical character recognition (OCR) and visual reasoning and helps the model to manage complex visual information.
This architectural design helps NVLM 1.0 to efficiently combine textual and visual information, which enhances its multimodal reasoning capacity.
Training Methodology
The training procedure of NVLM 1.0 is divided into two primary phases, each of which is designed to enhance multimodal integration while maintaining language proficiency:
Pre-training Phase:
- Component Freezing: Train only the modality-specific layers (e.g., MLP projectors) while freezing both the language model and vision encoder. This approach helps to steady learning and stop disturbance of pre-existing linguistic and visual skills.
- Data Curation: Emphasize data that is both diverse and of high quality, such as visual question answering (VQA), OCR, and arithmetic reasoning in visual contexts. The model acquires a diverse array of skills without solely relying on large-scale data by prioritizing task diversity and data quality.
Supervised Fine-Tuning (SFT):
- Selective Unfreezing: The language model is unfrozen while the vision encoder remains frozen, enabling the model to adjust its language capabilities in response to multimodal inputs without affecting visual processing.,
- Integrated Datasets: Combine multimodal datasets with high-quality text-only fine-tuning data. This combination makes sure the model’s multimodal skills are fine-tuned while still keeping or improving its text-only performance.
This structured training approach allows NVLM 1.0 to develop a strong multimodal comprehension without sacrificing its language proficiency.
Evaluation and Benchmarks
The competitive performance of NVLM 1.0 has been exhaustively assessed across several types of benchmarks:
Vision-Language Tasks:
- OCRBench: Shown its prowess in OCR-related activities with an impressive accuracy rate of 92%.
- VQAv2: Reflecting its capacity in visual question answering, attained an 80% accuracy.
Multimodal Reasoning:
- MMMU: Scored 78%, meaning multimodal understanding is rather strong.
- MathVista: Got an 85% on MathVista, which shows that you are good at visual mathematical thinking.
Text-Only Improvements:
- Math and Coding Benchmarks: After multimodal training, NVLM 1.0 showed an average 4.3-point improvement in accuracy over its language model backbone, showing better reasoning and coding skills.
According to these results, NVLM 1.0 is a strong open-access model that can compete with closed systems like GPT-4o and do better than other open-source models like LLaVA and InternVL 2.
Mistral AI Pixtral Large: How a 124 Billion Parameter Multimodal Model Handles Text and Vision at Scale
Mistral AI is a French AI company that specializes in the development of large language models (LLMs) that are open-weight. Pixtral Large, a multimodal model combining visual and textual processing capability, is one of their most well-known modal. This model shows how Mistral AI is dedicated to pushing the limits of AI innovation while staying open and easy to use.
Architectural Design of Pixtral Large
Pixtral Large is engineered to seamlessly incorporate visual and textual data processing by means of several critical architectural components:
Model Composition:
- Total Parameters: A 123-billion-parameter text decoder and a 1-billion-parameter vision encoder, which is equivalent to approximately 124 billion parameters.
- Pixtral-ViT, the vision encoder, processes visual data and subsequently inputs the resulting embeddings into the transformer decoder, improving unified multimodal understanding.
Key Architectural Innovations:
- Unified Multimodal Decoder: Enables the model to manage complex inputs that include both modalities by integrating lengthy text contexts with visual data.
- Dynamic Multi-Resolution Vision Processing: Improves the model’s capacity to process high-resolution images efficiently by using techniques such as block-diagonal attention masks and Rotary Position Embedding (ROPE-2D) encoding to manage variable image sizes.
- Scalability: Enables the processing of extensive visual-text inputs without compromising performance by supporting large context windows, such as 128,000 tokens.
Pixtral Large can effectively combine and handle multimodal information thanks to these architectural decisions. This makes it useful for a wide range of uses.
Training and Fine-Tuning Strategies
Pixtral Large uses meticulous training and fine-tuning strategies to ensure the robustness of its multimodal capabilities:
Data Curation and Pretraining:
- Diverse Datasets: Uses a diverse array of datasets, such as image captioning, visual reasoning (e.g., MathVista, DocVQA), and Optical Character Recognition (OCR) tasks, to capture a broad spectrum of visual-textual relationships.
- Emphasis on Quality: Ensures that the model learns meaningful associations between visual and textual information by focusing on high-quality, task-oriented pretraining data to achieve robust multimodal alignment.
Supervised Fine-Tuning (SFT):
- Dataset Blending: Consists of the integration of visual information while maintaining the model’s language understanding capabilities. This is achieved by combining multimodal SFT datasets with text-only datasets to preserve and improve text performance.
- Optimization Techniques: Uses methods similar to those in NVIDIA’s NVLM to keep the model’s skill level high across a variety of input types while preventing performance loss in text-only tasks.
These techniques ensure Pixtral Large’s outstanding performance in both multimodal and text-only environments.
Benchmarking and Performance
Pixtral Large has shown outstanding performance on several benchmarks:
Multimodal Evaluation:
- MathVista: Got an 85%, showing great visual mathematical reasoning ability.
- ChartQA: Achieved a score of 88%, which suggests that the individual was proficient in the interpretation and response of queries based on chart data.
- DocVQA: Got an accuracy score of 90%, which shows a good understanding of document-based visual question-answering tasks.
- MM-MT-Bench: Achieved a benchmark score of 82%, indicating the presence of entire multimodal multitasking capabilities.
Text-Only Capabilities:
- MMLU (Massive Multitask Language Understanding): Maintained an accuracy rate of 78%, suggesting a robust comprehension of language across a variety of subjects.
- GSM8K: Achieved a score of 80%, which shows excellent problem-solving abilities in grade school mathematics.
- MATH: Got a 75%, which speaks to strong mathematical sense.
- MATH: Achieved a score of 75%, which is a sign of strong mathematical reasoning skills.
- HumanEval: Achieved a score of 85%, indicating a high level of proficiency in understanding and code generation assignments.
Pixtral Large’s outstanding performance in both multimodal and text-only assessments is demonstrated by these results, showing its adaptability and efficacy in several domains.
BLIP-2: How the Querying Transformer Bridges Frozen Image Encoders and Large Language Models
BLIP-2 (Bootstrapping Language-Image Pre-training) is an advanced framework that incorporates the processing of visual and textual data. It uses a lightweight “Querying Transformer” (Q-Former) module together with a frozen image encoder to close the visual input to large language model (LLM) gap. This design enables BLIP-2 to efficiently process and generate language based on visual content without the need for extensive retraining of the image encoder or the LLM. BLIP-2 is capable of achieving high efficacy and performance in tasks such as visual question answering and image captioning by using pre-existing, pre-trained components.
Core Architecture
The architecture of BLIP-2 consists of on many important elements:
Frozen Image Encoder: Extracts high-dimensional visual features from images by utilizing pre-trained models, such as ViT-L/14. Maintaining the image encoder at a fixed state provides stability and minimizes computational demands during the training process.
Querying Transformer (Q-Former):
- Structure: A 12-layer Transformer encoder that interacts with the suspended image encoder to extract pertinent visual features.
- Function: Effectively summarizes visual information for the LLM by converting high-dimensional image features into a set of learnable query tokens.
Integration with Large Language Model (LLM):
- Multi-Modal Attention: The frozen LLM receives the query tokens generated by the Q-Former so the model can generate text depending on visual content. This integration enables BLIP-2 to efficiently execute tasks such as visual question responding and image captioning.
The modular design of BLIP-2 enables it to capitalize on the capabilities of pre-trained vision and language models while maintaining a lightweight and efficient architecture..
Training and Fine-Tuning
Training for BLIP-2 consists in two primary phases:
Vision-Language Representation Learning:
- Objective: Ensure that visual features are in in line with textual information.
- Approach: The Q-Former acquires the ability to derive image features that are important to the accompanying text through interaction with the frozen image encoder. This step creates a common representation for textual and visual modes.
Vision-to-Language Generative Learning:
- Objective: Enable the model to produce text generated from visual inputs.
- Approach: The Q-Former establishes a connection with a suspended LLM, thereby enabling the combined system to interpret visual representations and generate corresponding textual outputs.
In both stages, the image encoder and LLM are frozen, and only the Q-Former and essential fusion layers are trained. This approach reduces the amount of trainable parameters, which improves training efficiency and maintaining pre-trained model integrity.
Metrics
Strong performance of BLIP-2 shows across several vision-language tasks:
- Visual Question Answering (VQAv2): Achieved an accuracy of 68.2% in zero-shot evaluations, surpassing models such as Flamingo80B by 8.7% while employing significantly fewer trainable parameters.
- Image Captioning (COCO Dataset): Achieved a CIDEr score of 136.7, which suggests the production of pertinent and high-quality image descriptions.
These tests show how well BLIP-2 understands and generates language depending on visual inputs, which makes it an appropriate approach for vision-language pre-training.
OpenFlamingo: How Cross-Attention Layers and Modality-Agnostic Tokenization Power Open-Source Multimodal AI
OpenFlamingo is an open-source framework that was created to extend and replicate DeepMind’s Flamingo model, which allows advanced processing and reasoning over both text and images. OpenFlamingo makes a lot of different uses possible by combining language and vision skills. Some examples are answering visual questions and adding captions to images. Its open-source status supports community participation, with the goal of making advanced multimodal models more accessible to everyone. The first version, OpenFlamingo-9B, is based on the Llama design and was trained on large datasets such as Multimodal C4 and LAION-2B.
Architectural Breakdown
OpenFlamingo’s architecture integrates visual and textual data processing through multiple critical components:
Visual Features Extraction: This method uses a vision encoder that has already been trained, like OpenAI’s CLIP ViT-L/14, to retrieve visual features from pictures.
Frozen Language Model (LLM): Uses a pre-trained language model, such as MPT or Llama, that is frozen during training to preserve its language understanding capabilities.
Adapter Network
- Layers of Cross-Attention: Combine visual and textual data by enabling the LLM to focus on visual characteristics retrieved by the vision encoder.
Modality-Agnostic Tokenization:
- Image Token Insertion: Allows the seamless integration of text and image data by converting visual features into tokens that are compatible with the LLM’s input.
Dynamic Fusion Strategies:
- Flexible Input Ordering: This feature lets you put words and images together in different orders, which makes the model more flexible for a range of multimodal tasks.
This flexible design makes sure that OpenFlamingo can handle and combine different types of data well, making the most of the best features of both language and visual models.
Training Paradigm and Efficiency
Specific training strategies are implemented by OpenFlamingo to enhance performance:
Training Methods
- Fine-Tuning using Multimodal Datasets: The adapter network is trained using datasets that contain interleaved image-text sequences, which allows the model to train complex associations between modalities.
Managing Long Context Windows
- Efficient Attention Mechanisms: Implements optimized attention mechanisms to manage lengthy sequences of interleaved data without sacrificing performance.
Ensuring Low Latency
- Frozen Component Strategy: The computational overhead during training and inference is reduced by freezing the vision encoder and LLM, resulting in quicker processing times.
These strategies enhance OpenFlamingo’s ability to manage intricate multimodal tasks while maintaining responsiveness.
Performance Evaluation
OpenFlamingo’s performance has been evaluated using a range of metrics:
Accuracy
- Visual Question Answering (VQAv2): Showed strong visual reasoning capabilities, achieving approximately 80% of the performance of DeepMind’s Flamingo model.
Fluency
- Image Captioning (COCO): Generated captions that were contextually appropriate and coherent, showing the effective integration of visual and textual information.
Inference Speed
- Latency Metrics: Maintained competitive inference speeds, which were ascribed to effective processing techniques and frozen architectural components.
These evaluations show OpenFlamingo’s efficiency in complicated multimodal tasks, making it useful for combined vision and language understanding applications.
The following is a comparison of the primary performance metrics of several prominent multimodal AI models:
| Model | Visual Question Answering (VQAv2) Accuracy | Image Captioning (COCO) CIDEr Score | OCR Tasks Accuracy | Multimodal Reasoning Accuracy | Text-Only Performance (MMLU) | |
| LLaVA | 68.2% | 136.7 | NA | NA | NA | |
| NVLM 1.0 | 80% | NA | 92% | 78% (MMMU) | +4.3 points over baseline | |
| Pixtral Large | 85% (MathVista) | NA | 90% (DocVQA) | 82% (MM-MT-Bench) | 78% | |
| BLIP-2 | 68.2% | 136.7 | NA | NA | NA | |
| OpenFlamingo | ~80% | NA | NA | NA | NA |
How Open-Source Multimodal LLMs Are Accelerating Collaboration and AI Innovation Worldwide
Open-source multimodal AI models have advanced data integration using several techniques. LlaVA integrates a language model with a vision encoder and uses a linear projection layer to align visual embeddings with the language model’s token space to enable cross-modal attention between image and text characteristics. NVLM 1.0 uses InternViT-6B vision encoder and Qwen2-72B language backbone. It allows dynamic high-resolution inputs using modality-alignment modules like MLP projectors and tile-tagging. Mistral AI’s Pixtral Large encodes lengthy text and visual data using a single multimodal encoder. It handles pictures of varying sizes utilizing dynamic multi-resolution vision processing. A “Q-former” module in BLIP-2 quickly converts high-dimensional image characteristics into language model-compatible query tokens for cross-modal attention. OpenFlamingo, based on DeepMind’s Flamingo, has a vision encoder, frozen language model, and adapter network. Image tokens are smoothly integrated into the text stream using modality-agnostic tokenization.
These models often use linear projection layers or adapter networks to integrate pre-trained visual encoders with language models. This approach efficiently aligns visual and textual data without considerable retraining. OpenFlamingo’s dynamic fusion techniques and BLIP-2’s “Q-former” for translating picture characteristics into question tokens allow multimodal inputs in any sequence.
The open-source nature of these models makes sophisticated AI technologies more accessible. Advanced multimodal models are available to researchers and developers worldwide. This improves collaboration and accelerates field innovation. This openness promotes honesty and allows for unique solutions for individual needs, which improves AI technology.

Learn how to build a generative AI chatbot in 2026. Covers LLM selection, RAG pipelines, evaluation metrics, real-time monitoring & safety guardrails.


Compare Future AGI and Weights and Biases in 2026. Covers capabilities, features, pricing, user experience, performance, integrations, use cases, pros.

Compare top 5 LLM evaluation tools in 2026. Covers Future AGI, Galileo, Arize, MLflow, and Patronus AI across capabilities, scalability, and use cases.
