Transformer Architecture Evaluation in 2026: Attention Quality, MMLU, GLUE, SQuAD, HellaSwag, and Inference Benchmarks
Evaluate transformer architectures in 2026: attention quality, perplexity, MMLU, GLUE, SQuAD, HellaSwag, training stability, inference throughput, checks.

Table of Contents
TL;DR: Five layers of transformer evaluation in 2026
| Layer | What it answers | Core metrics |
|---|---|---|
| Pretraining quality | Did the model learn the distribution cleanly | Perplexity, training stability, gradient norms, MFU |
| Task quality (academic) | What can it do on standardized tasks | MMLU, GLUE/SuperGLUE, SQuAD, HellaSwag, MMLU-Pro |
| Long-context + agentic | Does it hold across long inputs and tool use | Ruler, LongBench v2, BFCL, SWE-bench Pro |
| Inference profile | What does it cost to run | Tokens per second, p50/p99 latency, peak GPU memory |
| Production task quality | Does it do your real job | Faithfulness, instruction adherence, toxicity (Future AGI evals) |
A transformer architecture is only “evaluated” when all five layers have numbers. Skipping any of them is how a model wins on paper and breaks in production.
Why transformer evaluation looks different in 2026
The transformer hasn’t changed in its essentials since 2017’s “Attention is All You Need” (Vaswani et al., arXiv:1706.03762). What changed is everything around it: models are 1000x larger, context windows are 10000x longer, the benchmark world has rotated, and “good performance on a benchmark” no longer predicts production behavior.
Three macro shifts you should evaluate against:
- Benchmark saturation. MMLU was the gold standard for knowledge in 2023. By mid-2025, frontier models scored above 90% and the discriminative range shrunk. MMLU-Pro and Humanity’s Last Exam took over the capability-ceiling role.
- Benchmark contamination. In April 2026, UC Berkeley’s RDI lab showed several major agent benchmarks could be exploited to near-perfect scores without solving the task. SWE-bench Pro (Scale AI’s contamination-resistant variant) became a stronger anchor for production coding decisions. The state of LLM benchmarking covers what the leaderboards do and do not tell you.
- Long-context evaluation grew up. Needle in a Haystack still gets cited, but the harder synthetic tests (Ruler, LongBench v2) and real-world long-document reasoning are where frontier models actually fail.
This post walks each of the five evaluation layers. Future AGI’s role lives in the production task quality layer through fi.evals (the ai-evaluation library, Apache 2.0) and traceAI (Apache 2.0). The other layers are where you pick a model; Future AGI is the eval companion once you start serving real traffic.
Layer 1: Pretraining quality
Perplexity
Perplexity is the exponentiated cross-entropy loss on held-out tokens. Lower is better. It tells you how well the model predicts the next token in distribution.
Use perplexity for:
- Comparing checkpoints from the same training run.
- Comparing models trained on the same data and tokenizer.
Do not use perplexity for:
- Cross-tokenizer comparison. A BPE model and a SentencePiece model score on different unit lengths and perplexity is not directly comparable.
- Picking a production model. Low perplexity does not mean better task performance once you reach the modern frontier.
Bits-per-byte (BPB) is the cross-tokenizer-comparable variant. Some 2026 model cards report BPB alongside perplexity when cross-tokenizer comparison matters.
Training stability
The single largest cost in pretraining a frontier transformer is divergence. A loss spike at step 800K on a 100B run is a multi-week setback. Track:
- Smoothed loss curve. Trending downward, no sudden jumps.
- Gradient norm. Stays in a stable band (typically 0.1-10 depending on the optimizer).
- Activation norms. Spike-free.
- Loss/grad spike correlation with batch composition. A bad data shard explains many spikes.
- Restart count. Number of times a manual restart from an earlier checkpoint was needed.
Stability is reported in qualitative terms in most papers but a robust training run will publish gradient-norm and loss-curve plots in the model card. The DeepSeek V3 (report) is a good public reference for what a stable trillion-parameter MoE training curve looks like.
Model FLOPs Utilization (MFU)
MFU is the ratio of achieved FLOPs to peak hardware FLOPs. For a well-tuned 100B-parameter transformer training on H100-class hardware, 40-55% MFU is competitive based on the PaLM (Chowdhery et al., arXiv:2204.02311) report and the broader GPU-engineering literature. Lower MFU means budget left on the table.
Throughput at training scale
Tokens per second per accelerator at your full configuration (model parallel + pipeline + data parallel). This is the most production-meaningful pretraining metric because it directly converts to dollars of compute.
Layer 2: Task quality (academic benchmarks)
MMLU and MMLU-Pro
MMLU (Massive Multitask Language Understanding, Hendrycks et al.) is 57-subject multiple-choice across STEM, humanities, social science, and applied tasks. 5-shot accuracy is the canonical reporting format.
- 2023: GPT-4 at roughly 86%. Discriminative for frontier models.
- 2026: Frontier models above 90%. Saturated. Use as a sanity check.
MMLU-Pro is the harder follow-up: 12,000 questions across 14 domains with stronger distractors and more reasoning. Headroom remains at the frontier.
GLUE and SuperGLUE
GLUE (Wang et al., arXiv:1804.07461) is the canonical English natural-language-understanding benchmark suite: sentence similarity, entailment, sentiment, question answering. SuperGLUE adds harder tasks.
- Saturated at the frontier for English.
- Useful for comparing smaller models, fine-tuned variants, and historical baselines.
SQuAD v1.1 and v2.0
SQuAD (Rajpurkar et al., arXiv:1606.05250) is extractive QA over Wikipedia. v2.0 adds unanswerable questions, forcing the model to know when to refuse. Still useful for evaluating reader-extractor models and RAG span-extraction.
HellaSwag
HellaSwag (Zellers et al., arXiv:1905.07830) is commonsense sentence completion. Adversarial filtering keeps it challenging across model generations. Used as a commonsense reasoning anchor.
Humanity’s Last Exam (HLE)
A frontier-only benchmark published by the Center for AI Safety and Scale AI. Designed to discriminate between top frontier models when MMLU and similar tests are saturated. Use HLE for capability-ceiling work; do not use HLE for routine model selection.
Coding benchmarks: HumanEval, MBPP, LiveCodeBench, SWE-bench Pro
- HumanEval and MBPP are old code-completion benchmarks. Still cited but saturated.
- LiveCodeBench is a continuously updated coding benchmark; less contamination risk.
- SWE-bench Verified was the production coding benchmark in 2024-2025. By 2026, Berkeley showed contamination exploits made it untrustworthy as a sole signal.
- SWE-bench Pro (Scale AI) is the contamination-resistant version. 1,865 tasks across 41 actively maintained repos under copyleft licenses. A stronger production-oriented coding benchmark for 2026.
Reasoning benchmarks: GPQA Diamond, MATH, GSM8K, AIME
- GPQA Diamond is “graduate-level Google-proof” physics, biology, chemistry. Strong signal.
- GSM8K is grade-school math word problems. Saturated.
- MATH is competition math. Still discriminative at the frontier.
- AIME is the American Invitational Mathematics Examination. The hardest commonly cited math benchmark.
The right reasoning benchmark depends on the model: small models still benefit from GSM8K signal, frontier models need MATH or AIME to discriminate.
Layer 3: Long-context and agentic evaluation
Needle in a Haystack and Ruler
Needle in a Haystack puts a known sentence inside a long irrelevant context and asks the model to retrieve it. Useful as a floor: a model that fails Needle does not have working long-context.
Ruler (Hsieh et al., arXiv:2404.06654) is harder. It evaluates multi-needle retrieval, aggregation, multi-hop reasoning over long contexts. The most cited long-context benchmark in 2026 model cards.
LongBench v2
LongBench v2 is a real-world long-context QA benchmark with documents ranging from thousands to hundreds of thousands of tokens. Where Ruler is synthetic, LongBench v2 is closer to production use cases.
BFCL (Berkeley Function Calling Leaderboard)
Function calling is structurally different from text completion. BFCL (gorilla.cs.berkeley.edu/leaderboard.html) tests whether models pick the right function and pass valid arguments across 1,700+ test cases. Required reading for any agent-bound transformer.
Terminal-Bench 2.0 and OSWorld
For agentic OS-level work, Terminal-Bench 2.0 (tbench.ai/leaderboard/terminal-bench/2.0) and OSWorld measure end-to-end task completion in shell and desktop environments. These are the agent-era follow-ups to SWE-bench.
Layer 4: Inference profile
You evaluate inference under the conditions you actually serve in. Three groups of metrics:
Throughput and latency
- Tokens per second at batch size 1. Single-request latency. The metric users feel.
- Tokens per second at peak batch. Throughput. The metric that controls cost per million tokens.
- p50 and p99 first-token latency. The first token is on the critical path of perceived responsiveness.
- p50 and p99 streaming token latency. After the first token, do tokens arrive smoothly.
Memory profile
- Peak GPU memory at your max context length. A transformer that fits at 32K may OOM at 1M.
- Cache size per token. KV cache memory is the main reason large context windows cost real money.
- Memory under your batch + context combination. Public numbers rarely match yours.
Architecture-driven costs
- Prefill versus decode time. Long prompts spend time in prefill; long generations spend time in decode. They scale differently with model architecture and serving framework.
- Attention mechanism cost. Standard attention is O(n^2) in context length. FlashAttention, paged attention, and MoE attention each have different scaling. Pick the model whose serving cost matches your traffic shape.
Most production teams find that vendor-published throughput numbers do not match their own. Always benchmark under your tokenizer, your serving framework (vLLM, TGI, SGLang, TensorRT-LLM), and your traffic shape before committing.
Layer 5: Production task quality with Future AGI
Public benchmarks tell you the model can do a class of tasks. Production evaluation tells you whether it does your task. The gap is where most production failures live.
The Future AGI SDK runs evaluators on real production traffic:
from fi.evals import evaluate
result = evaluate(
eval_templates="faithfulness",
inputs={
"input": "Summarize the user's last invoice and total spend this year.",
"output": "Last invoice: $1,247 dated April 28, 2026. Total year to date: $11,809.",
"context": "Invoice records: [INV-2104 $1,247 2026-04-28; YTD sum: $11,809.42].",
},
model_name="turing_small",
)
print(result.eval_results[0].metrics[0].value, result.eval_results[0].reason)Common production evaluators for a transformer-backed product:
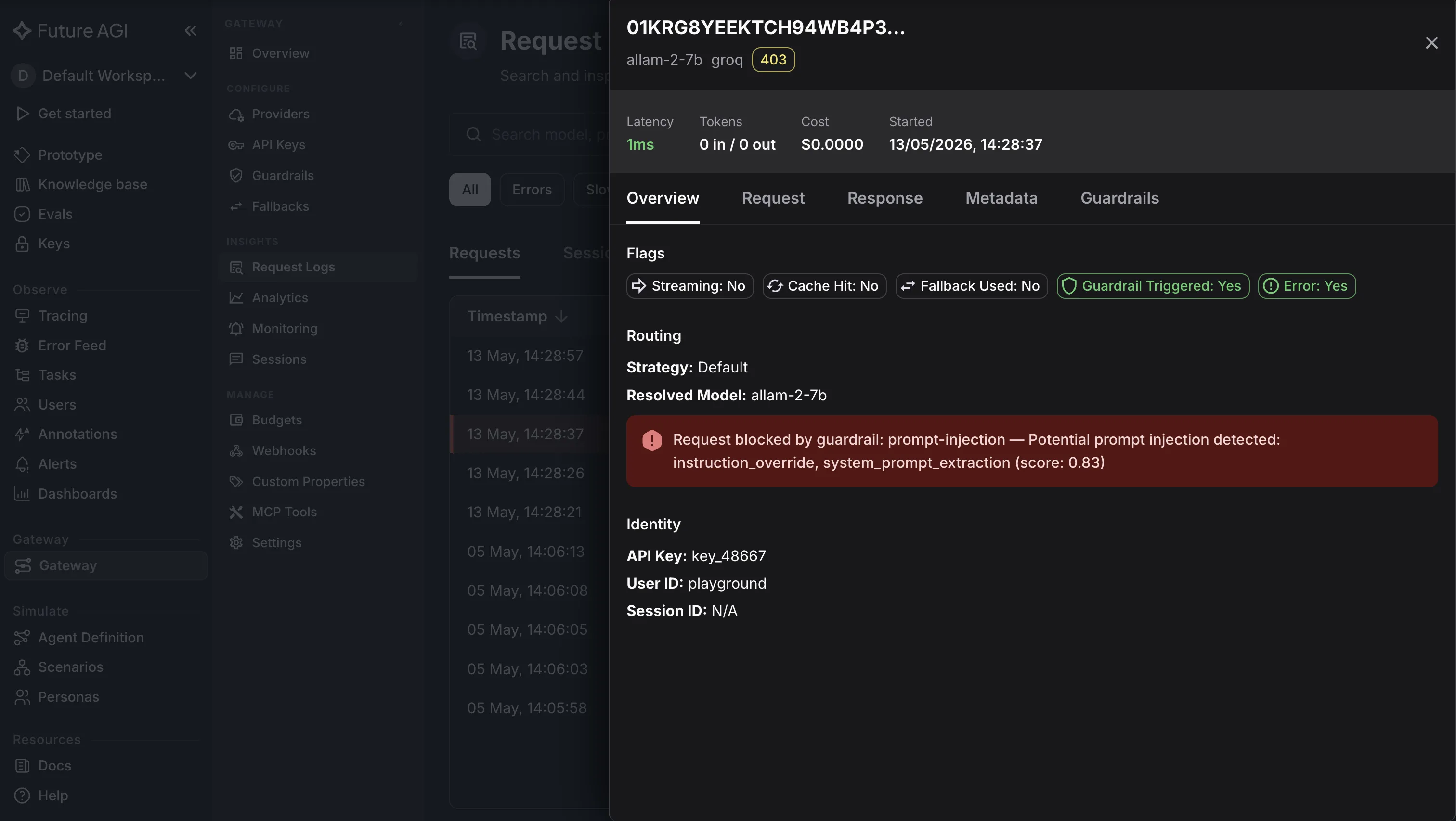
faithfulnessfor any RAG-style or tool-using flow.instruction_adherencefor prompted behavior.toxicityfor any user-facing surface.tonewhen persona matters (customer support, sales).prompt_injectionfor any agent loop.- Custom evaluators via
fi.evals.metrics.CustomLLMJudgefor domain-specific rules.
Cloud judge models: turing_flash (~1-2s) for low-latency inline gating, turing_small (~2-3s) for richer judgments, turing_large (~3-5s) for the highest-stakes reviews. Pick per evaluator, not globally.
Instrument the model server with traceAI
from fi_instrumentation import register
tracer_provider = register(
project_name="customer-support-llm",
project_version_name="claude-opus-4-7-v3",
project_type="llm",
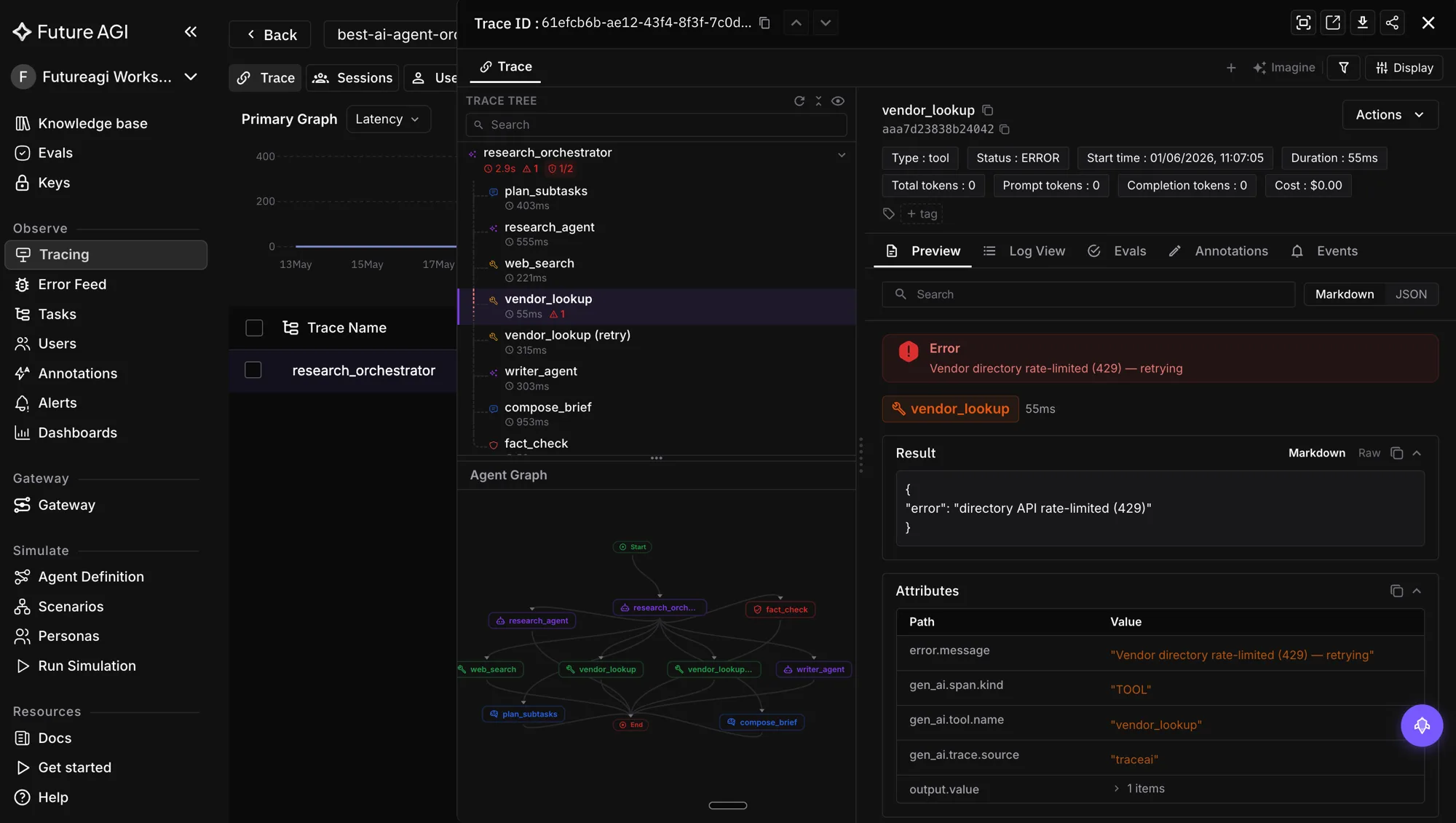
)Once spans are flowing, the Agent Command Center at /platform/monitor/command-center surfaces failing traces with the inputs and outputs inline, so a degraded model release shows up in minutes, not days. The two env vars you need are FI_API_KEY and FI_SECRET_KEY.
Reading a 2026 model card
A modern transformer model card should give you:
- Pretraining data summary (size, mix, decontamination steps).
- Tokenizer and vocabulary size.
- Architecture details (layers, hidden size, attention pattern, activation, normalization).
- Training infra (accelerator count, parallelism, MFU).
- Loss curves and gradient norm plots, with restart count if any.
- A benchmark table that includes at least one contamination-resistant variant per task category.
- Inference profile: tokens per second at batch 1 and at peak batch, p50/p99 latency, max context window, memory profile.
- License and usage terms.
- Known limitations and failure modes.
A model card that hands you only MMLU and HumanEval in 2026 is below the bar. Push for SWE-bench Pro, Ruler, LongBench v2, and a production-shape inference number.
Common mistakes when evaluating a transformer in 2026
- Stopping at MMLU. A 90% score tells you the model is competent and tells you nothing else.
- Ignoring contamination. Take the Verified-vs-Pro gap seriously; large gaps indicate the model overfits the benchmark distribution.
- Trusting vendor throughput numbers. Re-measure under your serving stack.
- Confusing pretraining quality with production quality. A model with low perplexity can still hallucinate, miss instructions, or fail your tone check.
- No production layer. A model is “evaluated” the day it ships to real users; everything before is signal.
Frequently asked questions
How do you evaluate a transformer architecture in 2026?
What is the most important benchmark for a 2026 transformer?
How is attention quality measured?
What is training stability and why does it matter?
How should I benchmark inference performance for a transformer?
What changed in transformer evaluation since 2025?
How do you evaluate transformer models in production with Future AGI?
Are MMLU and GLUE still relevant in 2026?

OpenAI AgentKit (Oct 2025) + Future AGI in 2026: visual builder, traceAI auto-instrumentation, fi.evals scoring, BYOK gateway. Real code, real APIs.


Cut LLM costs 30% in 90 days. 2026 playbook on model routing, caching, BYOK gateways, cost tracking. Includes best LLM cost-tracking tools.


Top prompt management platforms in 2026: Future AGI, PromptLayer, Promptfoo, Langfuse, Helicone, Braintrust, OpenAI Prompts API. Compared.