


Introduction
Large Language Models (LLMs) have revolutionized natural language processing tasks, but they face critical challenges such as knowledge cut off, hallucinations, and limited contextual awareness. Enter RAG Architecture LLM Agent—a groundbreaking approach that combines the best of retrieval and generation to address these shortcomings. Retrieval-Augmented Generation (RAG) integrates external knowledge sources into LLMs, ensuring accurate, dynamic, and contextually relevant responses. This cutting-edge architecture is becoming essential for deploying effective AI agents across industries.
How RAG Architecture Overcomes LLM Limitations
Real-Time Knowledge Integration
LLMs are limited by their training data, which is fixed up to a certain cutoff date. This makes it challenging to handle emerging topics or provide up-to-date information. To learn more about how AI models can adapt in real-time, check out our article on Real-Time Learning in LLMs: Advancing Autonomous AGI.
RAG Solution: The RAG architecture integrates external databases and live sources, ensuring access to the latest information. When a query is submitted, RAG retrieves relevant data in real-time and uses it to generate informed and accurate responses. For example, a RAG-based system can provide insights about recent scientific discoveries or breaking news by querying current databases.
Mitigating Hallucinations
LLMs can sometimes produce factually incorrect or fabricated responses, a phenomenon known as hallucination. These inaccuracies can erode trust in AI systems.
RAG Solution: By grounding responses in retrieved, reliable data, RAG reduces the risk of hallucination. It ensures that the content generated is aligned with authoritative sources. Moreover, RAG can employ confidence scoring and traceability, allowing users to verify the origin of the information provided.
Extending Context Handling
LLMs face constraints with fixed context windows, which limit their ability to process large documents or maintain coherence in long conversations.
RAG Solution: The RAG architecture leverages retrieval systems to dynamically fetch relevant context, enabling effective handling of large documents or extended interactions. By breaking down queries and retrieving related segments as needed, RAG ensures continuity and relevance across lengthy exchanges.
What is RAG?
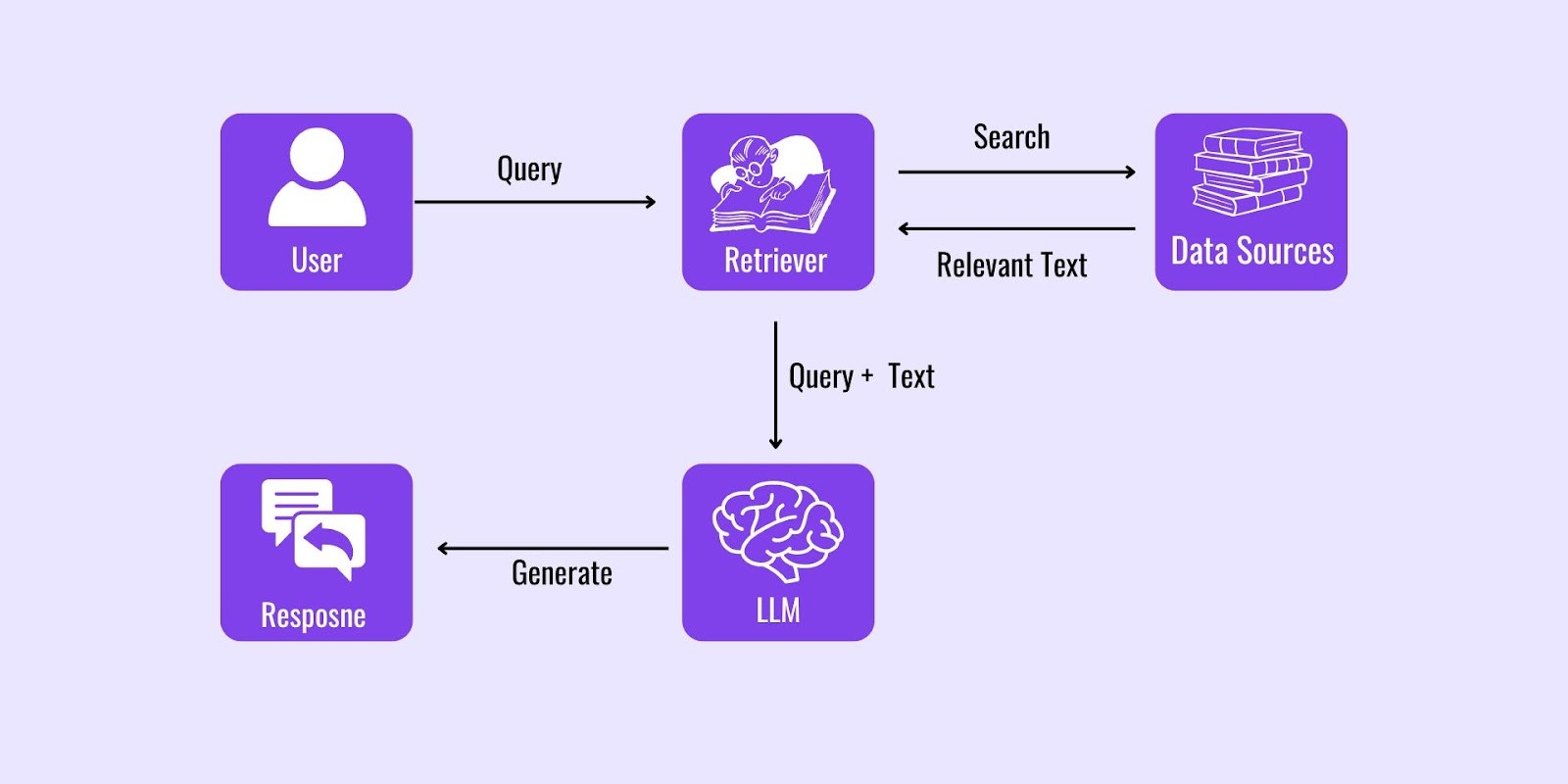
At its core, RAG Architecture blends a retriever and a generator to produce enriched, contextually aware outputs. Here’s how it works:
Retriever: Pulls relevant information from external structured or unstructured data sources, such as databases, APIs, or web content.
Generator: Utilizes a pre-trained LLM to craft coherent responses based on the retrieved data.
Think of RAG as a research assistant—one part gathers relevant information, and the other uses it to craft meaningful insights. This approach ensures that responses are both factually grounded and contextually accurate. The RAG Architecture LLM Agent demonstrates these principles seamlessly.
Components of RAG Architecture
Retriever
Implements techniques such as vector search or hybrid retrievers to fetch precise information.
Vector search represents data points as mathematical embeddings, enabling similarity-based retrieval. Hybrid retrievers combine methods like keyword-based search and semantic retrieval for broader coverage.
Accesses structured datasets (e.g., relational databases) and unstructured sources (e.g., documents).
Structured data includes well-organized formats like SQL databases, where information is stored in tables. Unstructured sources include raw text files, PDFs, or web pages that lack a predefined schema, making retrieval techniques critical for finding relevant information effectively. The retriever component in the RAG Architecture LLM Agent is pivotal for dynamic knowledge updates. Learn more about the role of synthetic datasets in improving retrieval for RAG.
Generator
Large language models, such as GPT, understand natural language, enabling them to generate coherent and contextually relevant responses. They adapt the retrieved content to produce user-friendly outputs.
Dynamically incorporates the fetched context into its output, ensuring fluency and factual accuracy.
By grounding the generation process in retrieved data, the generator can provide accurate and up-to-date answers, reducing the risk of "hallucinated" information that is not grounded in facts. The generator is integral to the RAG Architecture LLM Agent's success.
To support the claim that Retrieval-Augmented Generation (RAG) reduces hallucination in large language models (LLMs), you can reference academic papers, technical blogs, and authoritative articles that discuss the advantages of combining retrieval mechanisms with generative models. Below are examples and references that illustrate how RAG minimizes hallucination:
"Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" by Patrick Lewis et al. (2020)
This seminal paper introduces the concept of RAG and explains how incorporating retrieved, relevant documents from a knowledge base into the generation process helps reduce hallucination. By grounding responses in verifiable external data, RAG ensures that generated answers are factually supported.
Source: arXiv:2005.11401
OpenAI's Blog on Models like GPT with RAG
OpenAI explains how RAG improves factual accuracy by dynamically retrieving external data, mitigating the risk of the model generating ungrounded or fabricated information.
Source: OpenAI Blog
"REALM: Retrieval-Augmented Language Model Pre-Training" by Kelvin Guu et al. (2020)
This paper explores retrieval-augmented models similar to RAG and highlights how retrieval mechanisms enhance factual consistency by integrating retrieved evidence into generated outputs.
Source: arXiv:2002.08909
Google Research Blog on Retrieval-Based Architectures
Google has discussed how retrieval-based methods like RAG help maintain factual accuracy in NLP applications by sourcing information from reliable repositories instead of relying solely on the model's training corpus.
Source: Google AI Blog
Meta AI's Discussion on RAG
Meta AI has highlighted how the RAG architecture aligns generative outputs with retrieved knowledge, effectively addressing challenges like hallucination in LLMs.
Source: Meta AI
These references provide foundational and practical insights into how RAG architectures reduce hallucination, ensuring that the information provided by generative models remains grounded in verified sources.
Integration Layer
The integration layer acts as a bridge, filtering and ranking retrieved content before feeding it into the generator. It ensures that only the most relevant, high-quality information is passed on to the generator by employing advanced ranking techniques such as BM25, dense embeddings, and confidence scoring mechanisms.
BM25: A probabilistic algorithm that rates documents based on how often a term occurs and the importance of the term. It ranks documents that are close to a query higher.
Dense Embeddings: Vector representations of text that capture semantic meaning, enabling the retrieval of conceptually relevant content even when there isn’t a direct keyword match.
Confidence Scoring: Assigning confidence scores to retrieval results ensures that content with the highest likelihood of relevance is prioritized for generation.
These techniques work in tandem to enhance response quality by eliminating irrelevant or redundant data. By discarding noisy or repetitive information, the integration layer streamlines the flow of data, improving the precision and clarity of the generator's output for the end user.
This layer is an indispensable part of the Retrieval-Augmented Generation (RAG) Architecture LLM Agent, ensuring that the generated responses are accurate, contextually relevant, and valuable.
Benefits of RAG for LLM Agents
Dynamic Knowledge Updates:
RAG enables access to real-time and up-to-date information, lessening the cost and frequency of some generations that would normally require retraining. This guarantees that the reactions are up to date, even in the fast-evolving domains of technology, medicine or news. For example, an LLM can fetch the latest regulations from an official database or live sports scores to deliver accurate and relevant answers. The RAG Architecture LLM Agent excels in delivering such dynamic updates.
Domain Specialization:
RAG allows LLMs to utilize specific datasets, documents, or APIs from specialized domains. By querying knowledge bases or repositories tailored to niche industries like law, healthcare, or engineering, the model can produce responses that are both precise and contextually appropriate. This capability makes it an excellent tool for applications requiring in-depth subject matter expertise, such as medical diagnostics or legal research. The RAG Architecture LLM Agent proves invaluable for such domain-specific applications.
Improved Accuracy:
Hallucination, where LLMs generate incorrect or fabricated information, is a common challenge in generative AI. By grounding responses in factual data retrieved from trusted sources, RAG significantly reduces hallucination rates. For instance, rather than generating speculative content, the model can directly reference a company's product catalog or a scientific article, enhancing reliability and trustworthiness. This feature positions the RAG Architecture LLM Agent as a reliable and accurate tool.
Scalability:
RAG facilitates the integration of diverse and growing knowledge sources, such as large document repositories, APIs, or real-time databases. This allows organizations to scale their AI capabilities across various use cases, from customer support to academic research. The modular nature of RAG also enables easy expansion of knowledge bases without disrupting existing functionality, supporting continuous growth and adaptability. Scalability is a hallmark of the RAG Architecture LLM Agent.
Design Considerations for RAG Implementation
When building a RAG (Retrieval-Augmented Generation) Architecture LLM Agent, several factors come into play. A deeper understanding of these considerations can significantly enhance the performance and efficiency of the system:
Retriever Selection
Choose between dense retrievers (e.g., DPR, embedding-based retrieval) and sparse retrievers (e.g., BM25, keyword-based retrieval) based on the nature of your data and requirements.
Dense retrievers excel at understanding semantic relationships in large datasets but may require more computational resources. Sparse retrievers are better suited for exact keyword matches and may work well in scenarios with limited hardware.
Evaluate trade-offs between retrieval speed and accuracy, as these choices directly impact the agent’s ability to fetch relevant information efficiently. The RAG Architecture LLM Agent implements this balance effectively.
Data Preprocessing
Preprocessing is crucial for effective indexing. Ensure that the data is cleaned, tokenized, and formatted to suit the retriever model.
Implement techniques like text deduplication, stopword removal, and normalization to reduce noise in the data, which helps improve retrieval accuracy.
Consider breaking large documents into smaller, more manageable chunks with overlapping windows to ensure no critical information is missed during retrieval. These preprocessing techniques enhance the RAG Architecture LLM Agent’s effectiveness.
Latency Management
Aim to minimize response times by balancing retrieval depth (number of documents fetched) and generation fluency (complexity of the LLM’s output).
Use caching mechanisms and efficient hardware (like GPUs or TPUs) to accelerate both retrieval and generation processes.
Employ techniques such as approximate nearest neighbor (ANN) search for faster retrieval without significantly compromising accuracy. Latency management is crucial for the RAG Architecture LLM Agent’s performance.
Integration
Optimize the interaction between the retriever and generator by employing advanced techniques such as ranking algorithms to prioritize the most relevant retrieved documents.
Deduplicate retrieved results to avoid redundancy and improve coherence in the generated output.
Leverage feedback loops to iteratively refine the retriever and generator, improving their synergy over time through continuous learning. The RAG Architecture LLM Agent incorporates these strategies seamlessly.
Applications of RAG (Retrieval-Augmented Generation) Architecture
Customer Support:
RAG architecture can revolutionize customer service by offering real-time, context-aware assistance. It integrates FAQs, product documentation, and support tickets to deliver precise answers to customer queries. For instance, if a user asks about troubleshooting a product issue, the system can retrieve relevant documentation and combine it with natural language explanations to guide the user step-by-step. This improves resolution times and enhances customer satisfaction. The RAG Architecture LLM Agent is particularly impactful in customer support.
Content Creation:
RAG models can be a powerful tool for generating factually accurate and engaging content. By pulling verified data from trusted sources, marketers can create compelling blog posts, email campaigns, or social media content that is both informative and creative. Researchers can also rely on it to draft reports or summaries backed by the latest studies, ensuring content is up-to-date and reliable. This helps reduce the risk of misinformation while saving time in the content creation process. The RAG Architecture LLM Agent streamlines content creation workflows.
Education:
In education, RAG systems can deliver highly personalized tutoring experiences. For example, they can answer student queries by retrieving relevant textbook material, online resources, or past classroom notes. Additionally, the system can adapt to a learner's progress by identifying gaps in understanding and offering tailored resources in real-time. This creates an interactive, adaptive learning environment, enhancing engagement and academic performance. The RAG Architecture LLM Agent transforms educational experiences.
Healthcare:
RAG architecture can enable AI agents in healthcare to provide accurate diagnostic support by accessing the latest medical guidelines, research papers, and case studies. For example, a doctor querying about a rare condition can receive a summarized response that combines updated treatment protocols and research findings. This ensures that healthcare professionals are equipped with the most current and reliable information, ultimately improving patient outcomes. The RAG Architecture LLM Agent has transformative potential in healthcare.
Examples and Case Studies
Prominent implementations of RAG architecture include:
ChatGPT + Bing:
This is a hybrid model that combines the generative capabilities of ChatGPT with real-time retrieval from Bing. When users ask a question, the model first retrieves relevant information from the Bing search engine to ensure the response is grounded in up-to-date, accurate data. This approach is particularly useful for answering questions about current events or providing real-world information that a standalone generative model might not have in its training data. The RAG Architecture LLM Agent demonstrates similar capabilities.
Google Bard:
Google Bard leverages RAG principles to deliver precise and real-world answers. It integrates retrieval mechanisms to pull information from external databases and the internet, ensuring that the responses are both relevant and accurate. For instance, when asked about the latest scientific developments or ongoing trends, Bard uses its retrieval capabilities to fetch the latest data and provides detailed explanations by synthesizing the retrieved content with its generative model. The RAG Architecture LLM Agent operates on comparable principles.
Challenges and Mitigation Strategies
Computational Overhead
Challenge: Retrieval adds processing time and resource requirements, including querying, ranking, and handling large storage systems.
Mitigation: Optimize retrieval pipelines, implement caching strategies, and use hardware accelerators to improve efficiency and scalability.
Data Quality Dependency
Challenge: Poor-quality, outdated, or irrelevant data affects response accuracy.
Mitigation: Use curated, up-to-date datasets, implement robust data validation mechanisms, and prioritize trustworthy data sources.
Bias Management
Challenge: Biases in external data or the model can lead to unfair or unbalanced outputs.
Mitigation: Carefully select diverse, unbiased data sources and apply fine-tuning techniques to address bias while ensuring fairness and inclusivity.
Future of RAG in LLM Development
The evolution of Retrieval-Augmented Generation (RAG) architecture holds immense potential to revolutionize how large language models interact with data and provide insights.
Real-Time Data Integration
RAG systems could seamlessly connect to live data streams, such as IoT devices, financial markets, or breaking news feeds. By doing so, they can provide up-to-date and contextually relevant information, enabling applications like real-time analytics, dynamic reporting, and event-driven decision-making. For instance, a RAG-powered assistant for healthcare professionals could continuously integrate patient monitoring data to provide timely and accurate recommendations. The RAG Architecture LLM Agent embodies this forward-thinking vision.
Advanced Retrieval Algorithms
The integration of next-generation neural retrievers will enhance the precision of information fetching. These algorithms can better understand user intent, context, and domain-specific nuances, delivering highly relevant results. By leveraging advancements in embedding techniques and multi-modal retrieval, RAG architectures can process complex queries, such as combining text, images, or tables, ensuring higher-quality outputs for users. Advanced retrieval techniques further refine the RAG Architecture LLM Agent.
User-Controlled Processes
RAG systems of the future will prioritize user customization, allowing individuals to tailor retrieval and generation workflows to meet their unique needs. For example, users could define filters for specific datasets, prioritize certain sources, or adjust the tone and depth of generated content. This level of personalization could make RAG-based tools indispensable across industries like education, research, and customer service, ensuring a more engaging and adaptive experience. The RAG Architecture LLM Agent paves the way for such user-centric innovations.
Summary
The RAG Architecture LLM Agent represents a significant leap forward in addressing the limitations of traditional LLMs. By merging dynamic retrieval with advanced generation, it empowers AI agents to deliver real-time, accurate, and domain-specific insights across industries like education, healthcare, and customer service. Companies like FutureAGI are pioneering the deployment of RAG to build versatile, scalable, and impactful AI systems, setting a new benchmark in intelligent automation. The RAG Architecture LLM Agent is revolutionizing the future of AI.
Similar Blogs







