Practical Guide to Setting Up LLM Guardrails in 2026: How Engineering Leaders Can Deploy AI Safely and at Scale
Learn how to set up effective LLM guardrails in 2026. Covers what guardrails are, why they matter, a five-step implementation process, tools like OpenAI.

Table of Contents
Why LLM Guardrails Are No Longer Optional for Safe and Compliant AI Deployments
Large-language models (LLMs) are quickly weaving themselves into day-to-day workflows, yet their power comes with pitfalls. LLM guardrails are therefore no longer optional. After all, a single hallucinated statistic, a biased recommendation, or a cleverly crafted prompt-injection attack can snowball into compliance headaches, brand-damage headlines, and-worst of all-lost user trust. Consequently, engineering and product teams have placed LLM guardrails at the very top of their to-do lists. Well-designed LLM guardrails rein in errant behaviour, reinforce ethical boundaries, and give organisations a solid, scalable foundation for responsible AI.
This guide tackles three practical questions:
- Exactly what are LLM guardrails?
- Why do they matter so much right now?
- How can you set them up without throttling innovation?
Let’s dig in.
What Are LLM Guardrails: How Input Filtering, Prompt Injection Shields, and Access Control Protect AI Systems
For large-language models, think of LLM guardrails as the seat belt and the speed limiter. In essence, by combining technical defences with policy regulations, they keep outputs safe, dependable, and brand-consistent.
Typical guardrail layers include:
- First, input- and output-filtering that captures text that is harmful, off-topic, or violates policy.
- Second, prompt-injection shields that prevent attempts to hijack system instructions.
- Third, fairness and factual limitations hard-coded to enforce ethical standards.
- Fourth, role-based access control so that only authorised users reach sensitive features.
- Finally, explainability hooks and logging that track every complex question and response.
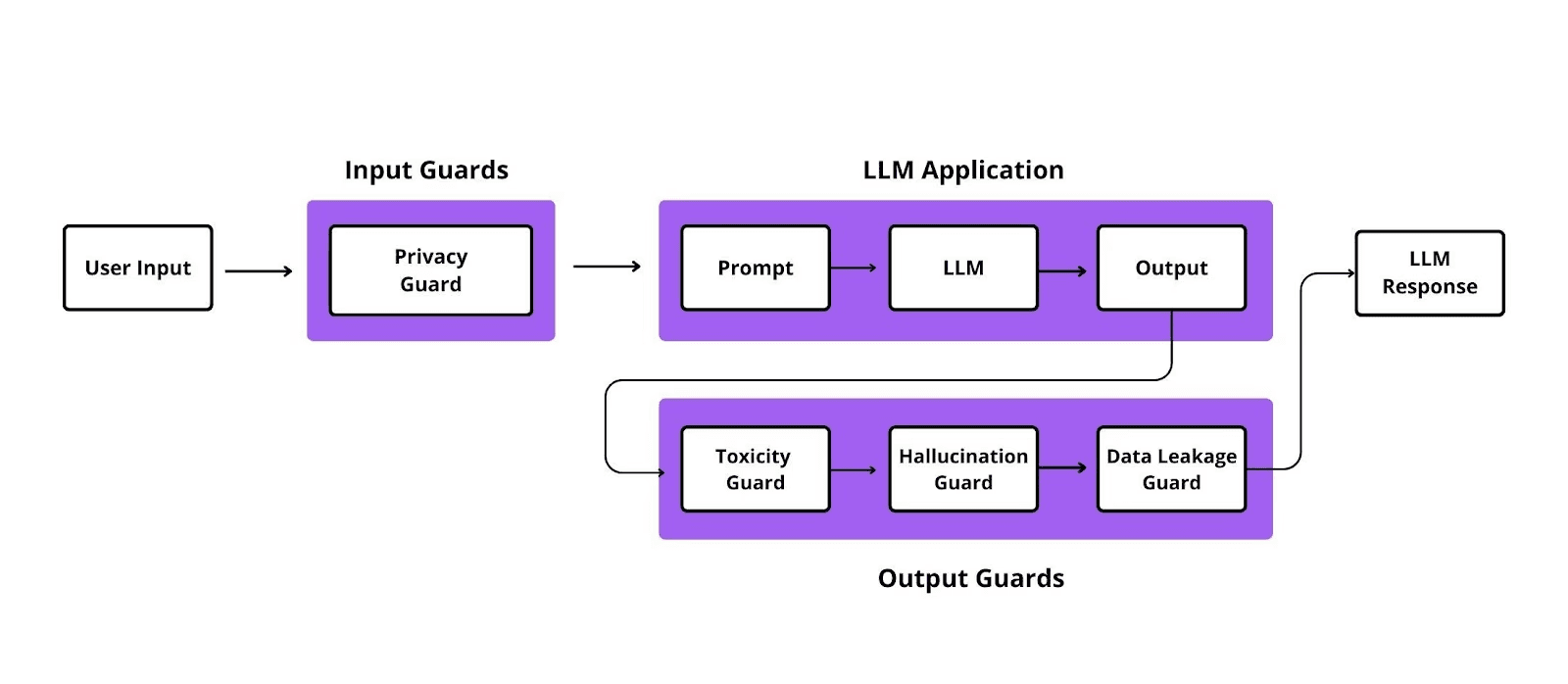
Image 1: Working of LLM Guardrails
Without these LLM guardrails, a model may blunder badly-particularly when confronted with malicious prompts or edge-case queries.
Why LLM Guardrails Are Essential for Deployment: Risk, Compliance, Brand, Security, and Scalability
Risk Mitigation: How Guardrails Filter Hate Speech, Misinformation, and Harmful Advice Before Reaching Users
Moreover, LLM guardrails act as a continuous quality filter in high-stakes fields like healthcare, finance, and legal research, screening hate speech, misinformation, and clinically harmful advice before it reaches the user.
Regulatory Compliance: How Guardrails Help Organizations Stay Aligned with EU AI Act, GDPR, and HIPAA
Likewise, they help ensure your AI systems stay aligned with laws such as the EU AI Act, GDPR, and HIPAA, thereby lowering audit and liability risks.
Brand Alignment: How Guardrails Ensure AI Responses Reflect Company Tone, Policy, and Values
Furthermore, by making sure AI responses reflect your company’s tone, policies, and values, LLM guardrails prevent PR disasters and disappointing user experiences.
Cybersecurity Reinforcement: How Guardrails Block Prompt Injection Exploits and Unauthorized Data Access
In addition, guardrails limit the attack surface, block prompt-injection exploits, and stop unauthorised data access, cementing their place in any AI security stack.
Scalability with Trust: How Guardrails Maintain Consistent Governance Across Multiple AI Products at Scale
As a result, when you scale LLMs across multiple products, LLM guardrails help maintain consistent governance, response quality, and performance.
How to Design and Implement Effective LLM Guardrails: A Five-Step Process for Engineering Leaders
Engineering leaders can follow a logical five-step process:
Step 1: How to Assess Current AI Systems and Identify Vulnerable Points in Existing Pipelines
Initially, audit existing AI pipelines. Look for:
- Points of failure in earlier AI outputs
- Access-control weaknesses
- Regions that violate data laws
This baseline, therefore, pinpoints vulnerable areas and shows where LLM guardrails must be strengthened.
Step 2: How to Define Domain-Specific Guardrails for Your Sector with Legal and Governance Teams
Next, create regulations tailored to your sector:
- Clean input and output text
- Use fairness-auditing tools
- Apply ethical frameworks to curb bias and misinformation
- Restrict access through roles or permissions
Importantly, involve legal, product, and data-governance teams in drafting these rules.
Step 3: How to Embed Guardrails Directly into AI Inference Layers Without Disrupting Operations
Then, integrate LLM guardrails directly into deployment workflows without interrupting operations:
- Insert filters in inference layers
- Apply real-time validators before user output
- Enforce rate caps and API throttling
When done correctly, safety rises while speed remains intact.
Step 4: How to Test and Benchmark Guardrails Using Adversarial Prompts and Human-Approved Content
Afterward, stress-test with adversarial prompts, scenario-based validations, and comparisons against human-approved content. Consequently, you confirm that your guardrails hold under real-world pressure.
Step 5: How to Monitor and Optimise LLM Guardrails Continuously as Models and Regulations Evolve
Finally, because AI evolves, your guardrails must too. Use:
- Real-time monitoring dashboards
- Alerting systems for anomalies
- Regular policy updates as models or regulations change
By following these steps, you ensure LLM guardrails stay current with emerging standards.
What Tools and Platforms Help Implement LLM Guardrails: OpenAI, IBM Watson, LangChain, and Cloud Options
Effective enforcement often involves dependable platforms such as:
- OpenAI Moderation API: Automatically detects hateful, violent, or sexual content-ideal for real-time interactions.
- IBM Watson OpenScaleshines in regulated sectors because it offers explainable artificial intelligence, bias tracking, and compliance monitoring.
- Popular with developers for prompt-injection defence, output validation, and structure enforcement, LangChain + Guardrails AI
- Google Vertex AI and AWS AI provide scalable infrastructure including security for hosting models, access restrictions, and built-in governance.
How to Explain LLM Guardrails to Business Teams: Executives, Legal and Compliance, and Product Teams
For Executives: How to Frame LLM Guardrails as Risk-Mitigation Pillars That Enable Safe AI Scaling
- To begin with, frame LLM guardrails as risk-mitigation pillars.
- Cite metrics such as “Guardrails cut policy violations by 70 % in two months.”
- Thus, position them as the safest path to scale AI.
For Legal and Compliance Teams: How to Demonstrate GDPR and HIPAA Alignment Through Audit Logs and Data Controls
- Similarly, emphasise adherence to GDPR, HIPAA, and related laws.
- Share data logs and auditing tools for AI decisions.
- Together, define policy-aligned actions.
For Product Teams: How to Translate Technical AI Risks into User Experience Risks and Build Early Trust
- Equally important, translate technical risks into user-experience risks.
- Put proactive restrictions in place so that trust is built early.
- Encourage shared responsibility across roles.
Real-World Case Studies That Prove LLM Guardrails Work: Shopify and Microsoft Copilot
Shopify: How Real-Time Filters and Anomaly Detection Reduced Moderation Time by 80 Percent at Scale
- Problem: Shopify generated product descriptions at scale; without barriers, offensive or erroneous content risked slipping through.
- Solutions: Real-time filters, anomaly detection, policy rollback.
- Impact: 80 % reduction in moderation time, 99.5 % policy adherence, 70 % less manual review workload.
Microsoft Copilot: How Input Sanitization and Role-Sensitive Filters Blocked Over One Million Breach Attempts Monthly
- Problem: Early tests revealed vulnerabilities to prompt-injection attacks.
- Solutions: Input sanitisation, role-sensitive filters, API-level limits.
- Impact: Over one million breach attempts blocked monthly, 35 % rise in user confidence, 50 % drop in IT support load.
Clearly, these stories prove that robust LLM guardrails boost safety and ROI.
How Well-Designed LLM Guardrails Clear the Path for Safe, Transparent, and Scalable AI Operations
Instead of obstacles, LLM guardrails are launching pads. They enable safe, transparent, large-scale AI operations. Accordingly, establishing boundaries means taking responsibility for performance, user welfare, and trust. Installed properly, guardrails will not slow you down; rather, they clear the path ahead.
How Future AGI Protect Helps Engineering Teams Deploy and Monitor LLM Guardrails at Scale
Discover Future AGI, the platform built for responsible LLM deployment. Our resources help you:
- Set up proactive LLM guardrails in minutes
- Stay ahead of compliance risks
- Monitor and improve AI behaviour continuously
Deploy AI confidently. Deploy with Future AGI.
Frequently Asked Questions About LLM Guardrails for Engineering Leaders
What are the key challenges in LLM deployment that guardrails are designed to address?
Addressing bias in AI-generated responses, hallucinations (false or misleading outputs), security risks (prompt injection attack), compliance (e.g., GDPR, HIPAA) are some challenges of LLM deployment. When there aren’t guardrails, LLM deployment could lead to unreliable, unethical or worse, harmful AI-generated content. So, safeguards are necessary.
How do guardrails improve LLM deployment reliability, ethics, and compliance for organizations?
By using guardrails when being deployed you ensure that large language models (LLMs) are not giving harmful, biased, or misleading outputs. They help the organizations to follow the laws and regulations of data privacy, enforce ethical safeguards, and guarantee the transparency of AI. If companies benefit from guardrails, LLM deployment may be more reliable, trustworthy, and compliant.
How can organizations ensure regulatory compliance in LLM deployment using guardrails and monitoring tools?
To ensure compliance in LLM deployment, organizations must ensure they are following the laws and regulations such as GDPR, HIIPA, AI Act etc. Firms have to put in place safeguards to block unauthorized data access, maintain logging, and implement ethical AI policies. Solutions like IBM Watson OpenScale can assist firms in tracking AI decisions to maintain transparency of LLM deployment.
What role does continuous monitoring play in maintaining LLM deployment security and stability?
Monitoring is important for LLM deployment security as it allows detection of anomalies throughout the LLM life cycle either due to some security threats or some other reason. It ensures that the models do not operate outside the boundaries which have been created for their functioning. Using real time monitoring, automated alerts and audit logs will help track AI interactions, identify risks quickly, and dynamically adjust the AI behaviour for stability and safety.
Frequently asked questions
Q1: What are the key challenges in LLM deployment?
Q2: How do guardrails improve LLM deployment?
Q3: How can organizations ensure compliance in LLM deployment?
Q4: What role does monitoring play in LLM deployment security?

Learn how to build a generative AI chatbot in 2026. Covers LLM selection, RAG pipelines, evaluation metrics, real-time monitoring & safety guardrails.


Learn how to secure enterprise LLMs in 2026. Covers GDPR, EU AI Act, NIST framework, bias detection, explainability & federated learning for AI teams.


Learn how to detect and mitigate bias in LLM outputs in 2026. Covers demographic bias, cultural bias, algorithmic bias, detection techniques, Fifty Shades.
