Context Engineering 2026: Definition, RAG, Memory, MCP, and How to Evaluate It
Context engineering is the production discipline around prompts in 2026. RAG, memory, MCP, tool use, evaluation, plus how Future AGI scores it.

Table of Contents
Context Engineering 2026: Why It Replaced Prompt Engineering
Context engineering is the discipline of designing the systems that automatically supply LLMs with the right structured background at inference time, including retrieved documents, memory state, tool outputs, and MCP-mediated context. By 2026, many production teams treat context engineering as a more important lever than standalone prompt wording.
TL;DR
| Layer | What it controls | Primary 2026 tools | How to evaluate |
|---|---|---|---|
| Retrieval | Which docs / data the model sees | Vector DBs, hybrid BM25 + dense, rerankers | precision@K, nDCG, context relevance |
| Memory | What the model remembers | Short-term buffer, long-term vector store, episodic memory | recall@K, conversational coherence |
| Tools | What the model can call | MCP servers, function calling, agent frameworks | tool-call accuracy, escalation rate |
| Context window | How much fits in | Chunking, summarization, prioritization | token utilization, response groundedness |
| Generation | What the model produces | LLM + decoding params | faithfulness, answer correctness |
| Observability | What you can see | OpenTelemetry traces, traceAI, structured logs | trace completeness, debuggability |
| Evaluation | What you measure | Future AGI fi.evals + fi.simulate | context-relevance, faithfulness, regression suites |
Why Context Engineering Is the Solution to Hallucinations and Inconsistent LLM Output
Context engineering is the art of feeding an AI system the right background for each task. Have you ever wondered how a production assistant keeps a multi-turn conversation coherent without losing track? It is rarely the model alone. The system around the model fetches relevant history, injects user preferences, attaches retrieved documents, and exposes tools, all before the model generates a token.
By 2026, context engineering has overtaken raw prompt-writing as the primary lever because hallucinations almost always reduce to a context problem. If the model has the right facts in the window with clear structure and proper grounding, it tends to answer correctly. When it does not, it confabulates. Treating context as a system, instead of a one-shot prompt, makes the difference between an unreliable demo and a production-grade agent.
This post walks through the definition, the architectural components, the 2026 stack, the evaluation methodology, and how Future AGI fits in as the evaluation layer for context-engineered systems.
What Is Context Engineering: Definition, How It Works, and How It Differs from Prompt Engineering
Context engineering is the practice of designing and operating systems that supply large language models with structured background information at inference time. It covers retrieval, ranking, sorting, compression, memory management, and tool integration. The big shift from prompt engineering is that context engineering is system-level: it manages constant streams of incoming data, keeps state across turns, and adapts as the situation changes.
Context Engineering vs Prompt Engineering: System Design vs Individual Queries
Prompt engineering focuses on the exact wording of a single query. Context engineering covers the end-to-end system that fetches, structures, and supplies contextual data such as document history, external API responses, and memory modules before the model sees the request. Prompt engineering shapes the question. Context engineering builds the structure around the model so that information stays current over time. Prompt engineering operates in the moment. Context engineering keeps things consistent by managing memory and data flows that run continuously. In practical 2026 work, prompt phrasing matters far less than which 3 chunks the retriever surfaced and which 2 tool calls the agent made.
Core Objectives of Context Engineering: Accuracy, Hallucination Reduction, Real-Time Adaptation, RAG, and MCP
- The model accesses the right information (company documents, user history, tool outputs) so it can give accurate, personalized answers.
- LLM outputs are grounded in verifiable data sources, not guessed, which reduces hallucinations.
- Feedback loops adapt context selection based on user signals and model performance.
- Retrieval-augmented generation (RAG) pulls documents or API results on demand and merges new information into responses.
- MCP standardizes how agents connect to tools and data so the integration layer is portable.
- Memory modules and tool calls combine so the system can recall past interactions and invoke specialized functions like databases or calculators.
Why Context Engineering Matters in 2026: Industry Adoption, Market Growth, and Real-World Applications
It is more important than ever to deliver the correct context in 2026 as enterprise AI systems take on complex tasks. Modern AI now reads internal documents, queries real-time data, and pulls from multiple SaaS systems in one turn. Without a solid context layer, it risks misreading signals or giving wrong responses. Anthropic and Meta are rolling out memory and retrieval upgrades to keep assistants current, and Google Cloud has documented how generative AI integrates with Vertex AI continuous delivery pipelines.
Highlights from industry leaders:
- Google Cloud wove Gemini models into Vertex AI to drive context-aware code reviews and release notes.
- Anthropic’s multi-agent setup saves summaries of each research step in external memory.
- Anthropic released the Model Context Protocol as an open standard for context and tool integration.
- Meta launched its AI app and Superintelligence Labs to make chat more aware of context.
- Gartner forecasts that global generative AI spend will reach $644 billion in 2025, signaling the scale of dependence on context systems.
Technical Foundations of Context Engineering: RAG, Memory, Token Management, and MCP
Retrieval-Augmented Generation: How RAG Indexes Documents and Adds Relevant Context Before Inference
- How it works: RAG systems index collections of external documents, run a semantic search to find the top-K relevant texts, and append those snippets to the prompt.
- Tradeoffs: They have to balance speed and relevance. Slower, more thorough searches improve accuracy but cost latency. Embedding dimensions need tuning to avoid bloated indexes or low similarity scores.
Memory and State Management: How Short-Term and Long-Term Memory Modules Keep LLMs Contextually Aware
In their paper “From Human Memory to AI Memory: A Survey on Memory Mechanisms in the Era of LLMs” Liu et al describe short-term and long-term memory:
- Short-term memory: The model’s context buffer keeps a sliding window of recent user interactions so it can remember what was just said.
- Long-term memory: Vector embeddings live in a database for episodic recall, which lets the AI surface old conversations or user profiles even when they fall outside the active context window.
Context Window and Token Management: How Chunking, Summarization, and Prioritization Fit Critical Data Within Token Limits
- Token limits: To stay within a model’s maximum tokens, pipelines use chunking, automatic summarization, or dynamic truncation, shrinking older or less relevant text so key details fit.
- Prioritization: Systems rank context pieces by relevance via simple heuristics (timestamp or keyword matches) or learned models so the most critical chunks stay in the window when space is tight.
Model Context Protocol: How MCP Standardizes Connections Between AI Assistants, Data Sources, and Tools
- Overview: MCP is an open JSON-RPC 2.0 standard from Anthropic that defines how AI assistants connect to data sources and tools.
- Advantages: It builds on familiar message flows (similar to Language Server Protocol), supports streaming and tool calls, and embeds structured metadata so you can swap data systems without rewiring your AI code.

Figure 1: AI System Components
Key Components and Architectural Patterns for Context Engineering Systems
A context engineering system uses a set of design patterns to provide AI models with the fresh, useful, well-ordered data they need. These patterns pull structured information through knowledge base integrations, then refine outputs via user feedback loops to make AI replies correct and timely.
Knowledge Base Integration: APIs, CDC Pipelines, and Cache Layers Feed Structured Data to LLMs
- Integrate relational or graph databases through APIs so the AI can retrieve structured information like product specs or user profiles on demand.
- Set up change-data-capture (CDC) pipelines that move inserts, updates, and deletes from source systems to the knowledge base in near real-time.
- Add cache layers, like in-memory stores, to speed up common queries and cut down API call cost.
Once the KB feeds are set up, the system gets quick, well-organized searches that open the door to advanced retrieval layers.
Semantic Retrieval Systems: How Vector Search and Hybrid BM25 Matching Improve Context Relevance
- Use vector search engines like Pinecone, Milvus, Qdrant, or pgvector to match user query embeddings with document embeddings.
- Combine BM25 keyword matching with embedding-based scoring (hybrid search) to improve accuracy on specialized or domain-specific queries.
- Add rerankers (Cohere Rerank, Voyage Rerank, or open models like BGE-Reranker) to lift precision on the top-K returned by the dense retriever.
Now that semantic retrieval has handled general relevance, the next step is picking the most important excerpts.
Context Prioritization and Filtering: Dynamic Scoring and Quality Filtering Remove Stale or Low-Value Context
- Dynamic scoring: Prioritize context segments based on a combination of similarity scores and business criteria (recency or significance signals) so the model evaluates only the most relevant candidates.
- Remove old or low-quality parts, like outdated policy documents or flagged content, so the AI does not condition on bad data.
By keeping only the most important snippets, the system raises the odds of correct, useful answers.
Real-Time Memory and Feedback Loops: How User Feedback and A/B Testing Continuously Improve Context Quality
- Update short-term and long-term memory stores based on user feedback (corrections, thumbs up/down, ratings). This signals which contexts matter most.
- Add A/B testing frameworks to context pipelines so you can compare retrieval and scoring strategies and measure the impact on response quality.
These loops close the gap between fixed configuration and real user needs, so the AI keeps improving as it interacts with the world.
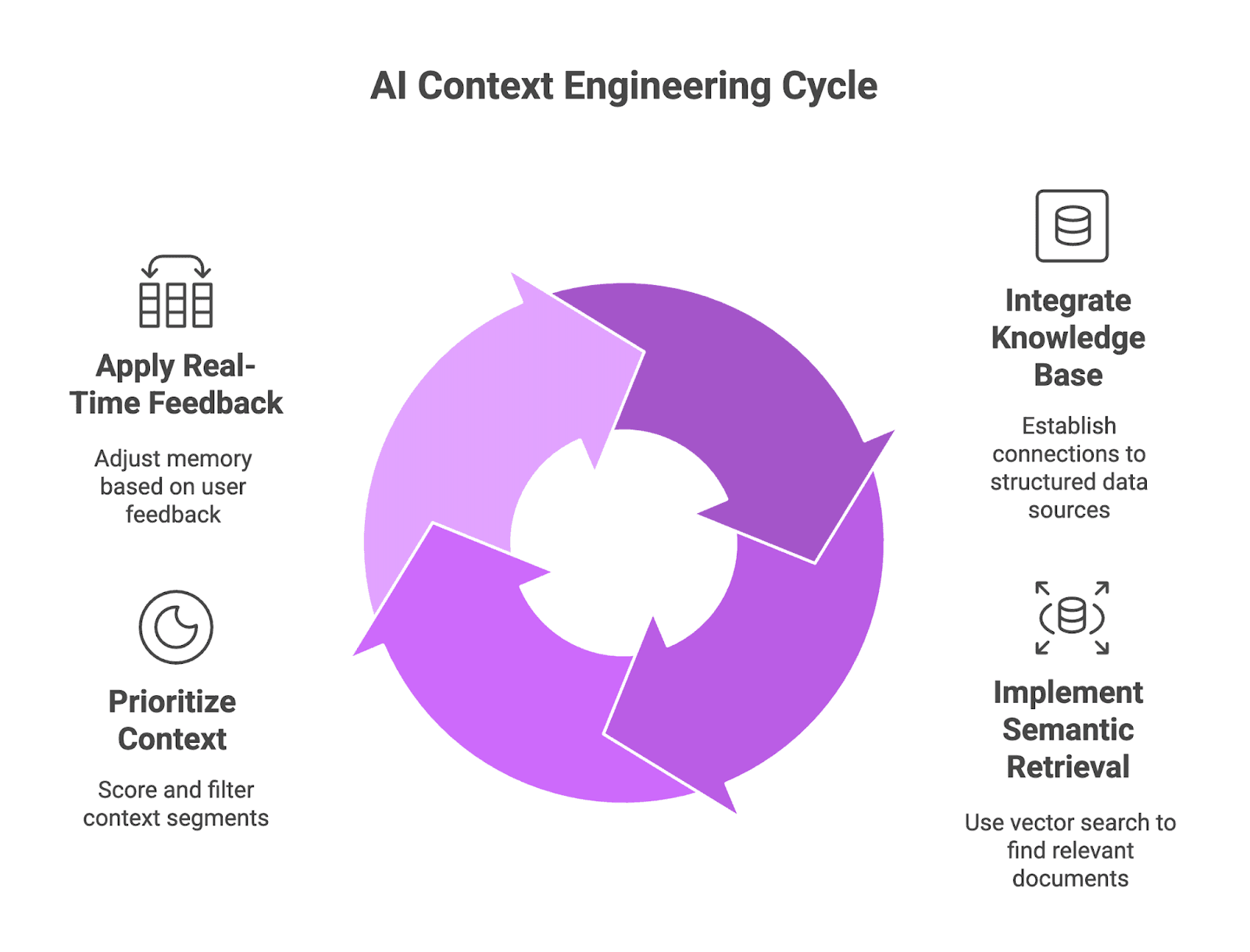
Figure 2: AI Context Engineering Cycle
How to Measure Context Engineering Performance: Relevance Scoring, Latency, and Token Optimization
Context Relevance Scoring: nDCG, MAP, and Human-in-the-Loop Reviews Measure Retrieval Quality
- nDCG and MAP on holdout data: Use Normalized Discounted Cumulative Gain (nDCG) or Mean Average Precision (MAP) on a set of labeled queries to measure retrieval improvement.
- Human-in-the-loop review: Use expert reviews to spot how hallucinations and accuracy vary across scenarios. Real-world error patterns guide the next round of retrieval tuning.
- Use a managed evaluator: Future AGI’s
evaluate("context_relevance", output=response, context=retrieved_chunks)returns a calibrated score backed by the Turing scoring models, so you can run this metric in CI on every retrieval change.
Latency and Throughput: How to Achieve Sub-100ms Context Assembly for Real-Time AI Applications
- End-to-end timing: Time how long it takes from query arrival to fully assembled prompt. Sub-100ms is the goal for chatbots and assistants to feel responsive.
- Parallelization and caching: Run independent retrieval calls in parallel and cache popular vectors or API responses so you do not repeat expensive lookups.
Token Budget Optimization: Trimming, Compression, and Reinforcement Learning Allocate Token Space Efficiently
- Utilization analysis: Track how many tokens each context segment consumes, then apply trimming (sentence-level pruning) or compression (summarization) to verbose sources.
- Adaptive allocation with RL: Use reinforcement-learning methods (like SelfBudgeter) to learn how to split your token budget dynamically, giving more space to critical segments and cutting less useful text.
Common Challenges Without Context Engineering: Hallucinations, Misalignment, and Manual Prompt Hacking
- Hallucinations: Without structured context, LLMs often make up details to fill gaps, which surfaces false or misleading facts.
- Poor generalization: Models that do not see domain-specific context tend to make broad statements that miss key details and get specialized information wrong.
- Misalignment with organizational knowledge: If the AI cannot access company policies, historical reports, or style guides, its suggestions may drift from internal norms.
- Manual prompt hacking: Without automated context feeds, developers fall back on ad-hoc prompt tweaks. These workarounds are brittle and do not scale.
How Future AGI Evaluates Context-Engineered Systems
Future AGI is the evaluation layer for context-engineered systems. It does not replace your vector DB, retriever, or orchestration framework. Instead, it scores how well your context pipeline grounds the model and exposes the trace data needed to debug failures.
fi.evals: Context Relevance, Faithfulness, and Groundedness Out of the Box
The Evaluation SDK ships with context-aware evaluators. Use them in CI or in production to score every request.
from fi.evals import evaluate
retrieved_chunks = [
"Refunds are processed within 30 calendar days of return receipt.",
"Customers can initiate a return by emailing support@example.com.",
]
response = "We refund customers within 30 days of receiving the return."
context_relevance = evaluate(
"context_relevance",
output=response,
context=retrieved_chunks,
)
faithfulness = evaluate(
"faithfulness",
output=response,
context=retrieved_chunks,
)
print(context_relevance, faithfulness)Both evaluators run on Future AGI’s Turing models in the cloud. Typical cloud latency: turing_flash about 1 to 2 seconds, turing_small about 2 to 3 seconds, turing_large about 3 to 5 seconds. See docs.futureagi.com/docs/sdk/evals/cloud-evals.
traceAI: OpenTelemetry Instrumentation for the Retrieval and Generation Pipeline
traceAI is Future AGI’s open-source instrumentation library (Apache 2.0). It captures structured spans for every retrieval, rerank, tool call, and LLM call so you can replay any production trace and see exactly which chunks were retrieved.
# Pseudocode: minimal traceAI instrumentation around a retrieval call.
# Replace `vector_store` and `user_query` with your real handles.
from fi_instrumentation import register, FITracer
register(project_name="rag-prod")
tracer = FITracer.get_tracer(__name__)
user_query = "Where can I find the refund policy?"
vector_store = my_vector_store # injected by your application code
with tracer.start_as_current_span("retrieval") as span:
span.set_attribute("query", user_query)
chunks = vector_store.search(user_query, top_k=5)
span.set_attribute("retrieved_chunks", [c.text for c in chunks])Spans propagate through the rest of your pipeline (LLM call, tool calls, response post-processing) so the full trace shows up in the Future AGI Observe dashboard alongside the fi.evals scores.
fi.simulate: Multi-Turn Regression Suites for Context Engineering Changes
Changes to retrievers, rerankers, or context-window strategies usually break some edge case. fi.simulate replays multi-turn conversations against persona profiles, which is the fastest way to regression-test before shipping.
# Pseudocode: replace `my_pipeline` with the function or class that runs
# your retrieval-augmented agent end to end.
from fi.simulate import TestRunner, AgentInput, AgentResponse
my_pipeline = ... # your RAG / agent pipeline
def my_agent(inp: AgentInput) -> AgentResponse:
answer = my_pipeline.run(inp.message)
return AgentResponse(message=answer)
runner = TestRunner(agent=my_agent)
results = runner.run(
scenarios=["billing_question", "refund_request", "policy_lookup"],
)Agent Command Center: BYOK Gateway for Context-Engineered Agents in Production
For production agents that span multiple providers and tools, the Agent Command Center BYOK gateway enforces guardrails, applies inline evaluators, and consolidates billing across OpenAI, Anthropic, Google, and self-hosted models. It is the policy and routing layer that sits between your agent and the providers, so context-engineering decisions can be measured and enforced without rewriting application code.
Context Engineering Is the Foundation of Reliable, Scalable, and Fact-Based AI Systems
Context engineering is the most important part of making AI systems that are reliable, scalable, and grounded in facts. Done right, it cuts mistakes, keeps models aligned with real data, and increases user trust. Treating context as a dynamic, modular system with retrieval layers, memory stores, MCP integrations, and built-in evaluators is what separates a fragile demo from a production agent.
Want to see it in action? Run the fi.evals quickstart on your own RAG pipeline, instrument it with traceAI, and replay multi-turn flows in fi.simulate. Book a demo or start a free account at app.futureagi.com.
Frequently asked questions
What is context engineering in 2026?
How is context engineering different from prompt engineering?
Can context engineering reduce LLM hallucinations?
What is the Model Context Protocol (MCP) and why does it matter for context engineering?
How do I evaluate a context-engineered LLM system?
What tools and SDKs support context engineering in 2026?
What is a context window in 2026?
How does Future AGI help with context engineering?

OpenAI AgentKit (Oct 2025) + Future AGI in 2026: visual builder, traceAI auto-instrumentation, fi.evals scoring, BYOK gateway. Real code, real APIs, no hype.


Cut LLM costs 30% in 90 days. 2026 playbook on model routing, caching, BYOK gateways, cost tracking. Includes best LLM cost-tracking tools.


Top prompt management platforms in 2026: Future AGI, PromptLayer, Promptfoo, Langfuse, Helicone, Braintrust, and the OpenAI Prompts API. Versioning + eval + deploy.