Building LLMs for Production in 2026: Key Considerations, Challenges, and a Step-by-Step Deployment Guide
Learn how to build LLMs for production in 2026. Covers data collection, model selection, deployment, scalability, healthcare & finance use cases & 2026 trends.

Table of Contents
Why Building LLMs for Production Is the Next Frontier in Enterprise AI
Building LLMs for Production is the next big thing in the field of AI. Imagine having systems that are not merely capable of understanding vast amounts of data but are also able to articulate and interact with it the kind of experts you can call any hour of the day. Also, building LLMs for production will change the way we work, we will be able to get more personalized experiences and better decision-making functions. Therefore, this blog will walk you through what it takes to create such models, their benefits, and the steps involved in deploying them efficiently.
Why Building LLMs for Production Matters: Real-Time Interaction, Scalability, and Accuracy at Scale
Specifically, creating and building LLMs for production isn’t just about training a model; it’s about solving real-world problems. Traditional models of AI are often inconsistent, not scalable, and not real-time. However, production-grade LLMs bridge this gap by offering:
- Real-Time Interaction: For example, whether it be predictive analytics or customer support, these models offer immediate and meaningful feedback.
- Scalability: Scaling LLMs helps businesses (from startups to scale-ups) meet growing demand smoothly and effectively.
- Accuracy and Context: Also, these models learn to encode intricate inputs and decode outputs that are highly relevant, thus minimizing errors.
As a result, whether you’re integrating AI in production or scaling LLMs for specific applications, this technology is paving the way for smarter automation.
Key Challenges in Building LLMs for Production: Data, Resources, and Deployment Complexity
In essence, building LLMs for production like GPT or similar advanced AI systems is a complex process. To make this easier to understand, let’s break down the key challenges and what they mean:
Data Overload
Specifically, Large Language Models need massive amounts of data to perform well. The data must not only be extensive but also clean, accurate, and diverse. Here’s why this is challenging:
- Data Collection: It takes time and costs money to find suitable datasets that cover most of the tasks or topics.
- Data Quality: On some occasions, raw data contains errors, or duplicates. Thus, it takes too much effort to make this data useful by removing junk or balancing.
- Ethical Concerns: Finally, ensuring that the data originated ethically, is not from a personal or sensitive context and is unbiased.
Resource Intensity
Moreover, building LLMs for production is computationally demanding. Let’s break down why:
- High-Performance Hardware: At first, Large Language Models need either GPUs (Graphics Processing Units) or TPUs (Tensor Processing Units) that do trillions of calculations. These are costly and consume vast amounts of energy.
- Training Time: Next, training an LLM can take weeks or months, even with the best hardware. During this time, any interruption or error can delay the entire process.
- Energy Costs: At last, you need to understand LLMs also require significant electricity, which makes both costs and the environment a concern.
Model Deployment Complexities
Importantly, training an LLM is just the beginning. Deploying it in the real world introduces its own set of challenges:
- Fine-Tuning: For instance, the model needs to be adapted for specific tasks or industries. In particular, an LLM used for healthcare will need specialized training on medical data.
- Monitoring and Maintenance: Also, once deployed, we need to continually monitor the model to identify issues like bias, inaccuracies, or drift (when the model becomes less effective due to changing data).
- Latency and Scalability: Additionally, even while handling a million requests, the model should be fast enough to respond to a user input. Thus, ensuring this requires robust infrastructure and optimization.
- Security and Privacy: At last, we need to think of ways to protect our models from harmful inputs and preserve the data of consumers.
How to Build LLMs for Production: A Six-Step Guide from Problem Definition to Continuous Scaling
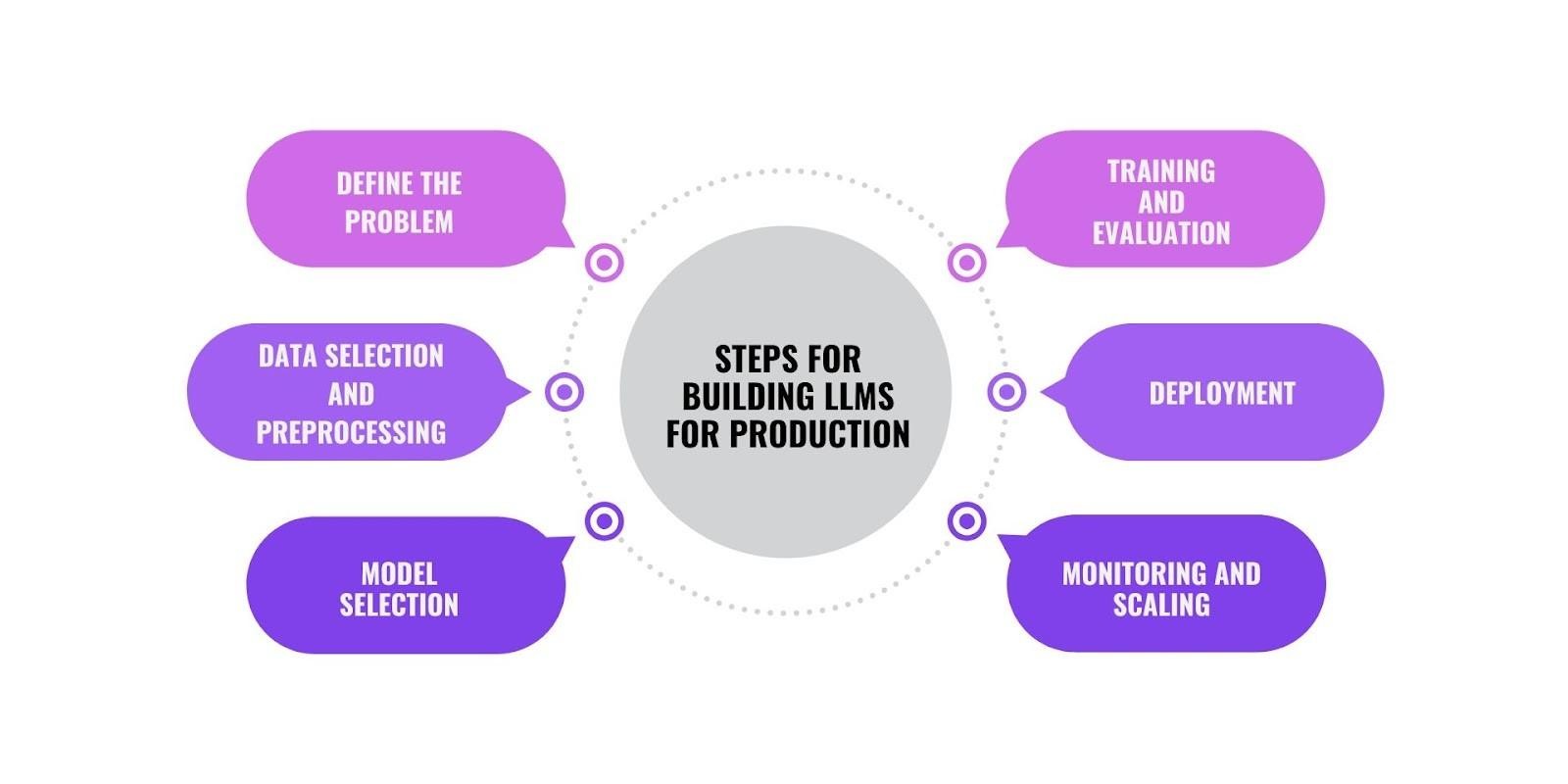
Step 1: Define the Problem and Set Clear Objectives Before Building Your LLM
Firstly, before you start, you need to define what problem the LLM will solve. This provides direction for the entire project.
Why it Matters: A well-defined problem focuses your time and money on a solution that is valuable. If you are not clear, you will produce a model for something else.
How to Approach: For instance, questions such as, “What business problem am I solving?” and “What output do I expect from the LLM?” help.
Step 2: How to Collect, Clean, and Pre-Process Data for High-Quality LLM Training
Next, data is the foundation of building LLMs for production. The quality and diversity of your data directly impact the model’s performance.
- Data Sources: Specifically, identify reliable and diverse datasets that reflect your use cases. For instance, customer support transcripts, articles, or industry-specific documents.
- Pre-processing: Subsequently, prepare the data by cleaning it. This means removing irrelevant, duplicate, or incorrect information and formatting it consistently.
Why it’s Important: As a result, poor-quality data leads to poor-quality predictions. Preprocessing ensures your LLM learns from accurate and relevant information.
Step 3: How to Select the Right Base Model: GPT, BERT, and Open-Source Alternatives Compared
Moreover, choosing the right base model is critical for success.
- Popular Choices: Pre-trained models, especially ones like GPT, BERT, and some open-source ones, are good options. These already have a good baseline that can be fine-tuned for your needs.
- Customization: Also, fine-tuning adapts the model to a certain task or industry. Customizing GPT for specialized areas, such as legal and customer support.
Why it Matters: Consequently, selecting the right model ensures you don’t reinvent the wheel, saving time and resources.
Step 4: How to Train and Evaluate LLMs Using Accuracy, Precision, and Recall Metrics
Furthermore, this step optimizes the model’s performance and ensures it meets your requirements.
- Training: Initially, feed the pre-processed data to the model and adjust parameters to improve its predictions.
- Evaluation: Next, measure the model’s performance using metrics like:
- Accuracy: For instance, how often does the model get it right?
- Precision: Moreover, does the model avoid false positives?
- Recall: Additionally, does it identify all relevant results?
Why it’s Crucial: Ultimately, regular evaluation ensures the model is learning effectively and meeting the desired standards.
Step 5: How to Deploy LLMs for Production Using AWS, Azure, and Google Cloud Infrastructure
Next, when the model works well, you can deploy it where users can use it in the live environment.
- Scalable Infrastructure: For example, utilize cloud platforms such as AWS, Azure or Google Cloud to manage heavy traffic volumes.
- Optimization: Make sure that the model is optimized for low latency to allow users to get responses quickly.
Why it Matters: In effect, deployment allows users to benefit from the model while making sure that it works optimally in practice.
Step 6: How to Monitor and Scale LLMs in Production: Response Time, Accuracy, and Usage Trends
Finally, after deployment, continuous monitoring is essential to maintain performance. For instance, check out real-time LLM performance optimization techniques to ensure your model remains efficient and scalable.
- Monitoring Metrics: Specifically, track key indicators like:
- Response Time: First, how quickly does the model reply?
- Accuracy: Second, are predictions still reliable?
- Usage Trends: Third, are there patterns in how users interact with the model?
- Scaling: Also, accommodate and scale the infrastructure and services based on user demand with almost no degradation in performance.
Why it’s Necessary: Consequently, monitoring ensures the model stays relevant and reliable over time. Scaling supports business growth.
Real-World Applications of Production-Grade LLMs Across Industries
Customer Support
For instance, the chatbot can understand your question and produce an immediate solution, quickly and precisely. For instance, how smart AI agents are supercharging automation for enhanced service and decision-making. In fact, production-grade LLMs excel at this by leveraging advanced natural language processing. Here’s how:
- Instant Query Resolution: In particular, LLMs can process different languages and different questions, such as the product or technical questions for customers.
- 24/7 Availability: Also, LLM-powered chatbots work non-stop, so the customers can avail assistance at any time.
- Continuous Learning: Moreover, they learn from history through interactions that take place with time and over the period.
Example: For instance, a telecom company using an LLM-based chatbot can guide customers through setting up a new device or resolving connectivity issues without waiting for a human representative.
Healthcare
Additionally, LLMs are revolutionizing healthcare by acting as virtual assistants for doctors and patients. Here’s how they make a difference:
- Assisting Diagnoses: For instance, LLMs can predict diagnoses based on the patient’s health record and symptoms. More specifically, test results and symptoms may indicate any sign of diabetes.
- Treatment Recommendations: Furthermore, these models can use large medical databases to recommend treatment plans customized for the patient based on evidence.
- Streamlining Documentation: Also, doctors save time as LLMs summarize patient visits and organize notes and help write reports.
Example: Specifically, a hospital could use an LLM to quickly identify treatment options for a rare condition by analyzing similar past cases and medical literature.
Finance
In the fast-paced world of finance, LLMs bring speed, precision, and automation. Here’s how they contribute:
- Fraud Detection: By checking transaction data maps, LLMs flag outliers that can signal fraudulent activity. An alert might get triggered for particular unusual spending patterns on a card.
- Financial Forecasting: Based on market data, company reports and news, LLMs predict trends. This aid businesses and investors make decisions.
- Customer Communication: Similarly, banks rely on LLMs for instant responses to inquiries about account balances, loan eligibility and repayment options.
Example: For example, an LLM could detect potential insider trading by analyzing conversations, emails, and trading activity simultaneously, ensuring compliance with regulations.
Marketing
Moreover, LLMs enable marketers to provide customized experiences that resonate with their customers. Here’s how:
- Personalized Campaigns: LLMs analyze user behaviors, preferences, and demographics to craft personalized messages for each customer. Based on what you’ve looked at, we may recommend products.
- Content Creation: With the help of LLMs, marketers can write captivating copy for ads, social media and email in seconds.
- Trend Analysis: Moreover, LLMs conduct market research for the brands that share valuable insights about their customer preferences and suggestions.
As an example, an e-commerce platform utilizes an LLM to send personalized discount communication, recommending a hiking gear to an outdoor enthusiast for a seasonal sale.
Key Trends in Scaling LLMs for Production: Edge Computing, Zero-Shot Learning, and Sustainability
As AI continues to evolve, scaling LLMs and ensuring their effective deployment is becoming more accessible. For instance, trends include:
Edge Computing
In essence, instead of processing data on centralized servers, edge computing involves deploying LLMs closer to the user, often on local devices or edge servers.
- Reduced Latency: LLMs can return responses quickly by processing data on-site. This is important for numerous applications such as voice assistants, AR/VR and self-driving cars.
- Privacy and Security: Moreover, data doesn’t need to move to central servers so it reduces the chance of breaches and protects the user’s privacy.
For example, think of a voice assistant where command processing happens on your smartphone rather than on cloud servers. This gives you quicker responses while addressing data privacy.
Zero-Shot Learning
Moreover, zero-shot learning allows LLMs to perform tasks they haven’t been explicitly trained for by leveraging their generalized understanding of language.
- LLMs use contextual reasoning and vast knowledge acquired during training to solve new problems without additional task-specific data.
- For instance, an LLM trained on something as high-level as just the Internet can answer questions about obscure things or translate a language it hasn’t trained on.
- Flexibility: This minimizes the need for specific datasets and retraining for each task, enabling faster, cheaper deployments.
- Broad Applications: With minimal set up, LLMs also helps tackle a range of tasks including customer support and creative writing.
Example: For instance, a customer support chatbot using zero-shot learning could assist users with troubleshooting a new product it hasn’t been trained on by understanding related topics.
Sustainability
Furthermore, sustainability in scaling LLMs focuses on reducing the environmental and computational costs associated with training and deploying these models.
Why it matters: In particular, training LLMs requires massive energy and computational resources, often leading to a high carbon footprint. Efforts are being made to make these processes more efficient.
- Efficient Architectures: Creating smaller but powerful models like fine-tuned or distilled versions of LLMs (like DistilGPT or TinyBERT) that work well while using fewer resources.
- Energy-Efficient Hardware: Additionally, leveraging GPUs, TPUs, and custom accelerators designed to reduce power consumption.
- Green AI Practices: Moreover, using renewable energy sources and optimizing data centres for energy efficiency.
Example: Specifically, companies like OpenAI and Google are investing in energy-efficient training infrastructure to lower the environmental impact of their LLM projects.
How Production-Grade LLMs Are Reshaping Industries and Driving Smarter Automation
To sum up, building LLMs for Production is not just a technical feat; it’s a game changer for industries worldwide. By leveraging these advanced models in their works, companies can discover new capabilities and remain ahead of the competition.
Ready to revolutionize your operations? For example, you can begin making and scaling LLMs for yourself and experience the impact of AI in production. Future-ready companies must leverage production-grade large language models (LLMs) focusing on either customer engagement or operational excellence, or both.
Be among AI pioneers who are building Artificial General Intelligence that is reshaping the planet. Stay ahead with industry-leading insights and visionary concepts at FutureAGI.
Frequently Asked Questions About Building LLMs for Production
What are the key steps to building LLMs for production?
The steps include problem definition, data collection and pre-processing, model selection, training and evaluation, deployment and continuous monitoring of the model. The purpose of every stage is that the model is fine-tuned and ready for real-world applications, allowing users to automate and take decisions efficiently. Careful planning and execution in those steps are important to obtain reliable and high-performing LLMs in production.
Why is scalability important when building LLMs for production deployments?
To manage increasingly large datasets and more users, scalability is key. LLMs for production-grade use must handle thousands of requests simultaneously without any latency. LLMs can maintain low latency and high responsiveness even during peak scaling due to smooth scaling. This capability is important for applications such as predictive analytics, intelligence automation and AI-driven operations at scale in the enterprise.
What challenges are faced when deploying LLMs in production environments?
Implementing LLMs requires dealing with massively scaled data, efficiently using computation, finetuning for specific tasks, and facing latency issues. The addition of monitoring for bias or drift and issues related to security, and data privacy make things more complex. To be reliable and safe, live or real-time artificial intelligence ( AI ) models need a strong infrastructure, monitoring and management of big data.
How do production-grade LLMs enhance customer support operations?
LLMs help customer support by sending fast responses that understand context and sending multilingual queries. Automated queries, 24/7 assistance, and reducing wait time have increased customers’ satisfaction. LLMs become progressively better with usage which makes them ideal for live chat, troubleshooting, and personalized service experiences in consumer-facing industries.
Frequently asked questions
Q1: What are the key steps to building LLMs for production?
Q2: Why is scalability important in building LLMs for production?
Q3: What challenges are faced when deploying LLMs in production?
Q4: How do LLMs enhance customer support?

Build production-grade voice AI evaluation in 2026. Covers STT, LLM & TTS metrics, five evaluation layers, synthetic testing frameworks, and key pitfalls to avoid.


Compare top LLMs in 2026 including GPT-5, Grok-4, Claude 4, and Gemini 2.5 Pro. Covers reasoning, coding, context window, speed, cost benchmarks, and use-case.


Compare top 5 AI guardrailing tools in 2026: Future AGI Protect, Galileo, Arize, Robust Intelligence, and Bedrock. Covers coverage, latency, and fit.
