
Senior Applied Scientist
Share:

Introduction
Data annotation is the process of assigning meaningful identifiers to raw data, such as images, text, or videos, to improve the understanding of models by machine learning algorithms. Supervised learning models rely on this procedure since it supplies the training data with the necessary ground truth. For example, in the field of computer vision, annotators can use bounding boxes to indicate the presence and location of objects in images. In the field of natural language processing (NLP), annotators can assign sentiment indicators to sentences or identify segments of speech.
Traditionally, these tasks have been completed by human annotators, who ensure the integrity of the labels through manual effort. At the same time, this manual method has become more resource-intensive and time-consuming as datasets have expanded in size and complexity. The concept of "LLM-as-a-judge" has been developed to confront these challenges. This method effectively automates portions of the annotation process by using Large Language Models (LLMs) to evaluate and generate annotations. LLMs have the ability to evaluate outputs in a manner that is similar to that of a human, providing judgments or designating scores to tasks that are typically challenging to evaluate automatically.
This piece reviews how humans and LLMs (large language models) do annotations. It looks at the advantages and disadvantages of each method and explores how combining them could improve AI development.
Fundamentals of Annotation
Data annotation is necessary for the development of AI models, as it offers labeled examples to simplify the training process. It is important to know both human and machine methods for labeling data to create effective AI systems.
Human Annotation
Human annotation is the process of humans carefully categorizing data in order to produce training sets for AI algorithms. This process ensures that models acquire knowledge from contextually important and precise information, which is essential for tasks that require complex judgment and thorough understanding.
Process
Crowdsourcing: Crowdsourcing is a method that gathers a big mix of people to help name data, usually via online platforms. Crowdsourcing uses the knowledge and ideas of many people to improve the quality and accuracy of data. Tasks are broken down into smaller parts and shared with many people, speeding up data tagging without losing quality.
Expert Labeling: In fields that need special knowledge, like medical images or legal document analysis, trained experts give accurate labels. Their expertise helps them label complicated data correctly, which is important for the model to work well in specific uses.
Quality Control Mechanisms: Inter-annotator agreement is one way used to keep annotation standards high. This means that several people are marking the same information and comparing how well their labels match. Annotations with high levels of agreement are likely to be accurate, but differences may reveal confusion or the need for more precise standards.
Strengths
Setup Efficiency: Human annotators can start labelling tasks quickly with little preparation, making them ideal for projects that need fast results. On the other hand, Large Language Models (LLMs) usually require complex setup and adjustments before they can begin labeling data.
Subjectivity in Annotations: Human annotations can be subjective, reflecting individual perspectives and cultural backgrounds. This subjectivity has the potential to include variability in the data, which may be advantageous for capturing a variety of perspectives. Although LLMs are consistent, they may not possess this complex understanding, resulting in more uniform annotations.
Cost and Speed Considerations: LLMs provide a cost-effective solution for extensive projects by promptly processing and annotating large datasets. However, there may be a significant need for computational resources and early setup. Although human annotators are slow on a per-instance basis, they do not require such infrastructure and are more flexible in meeting the specific requirements of a project.
Limitations
Scalability Bottlenecks: Human annotation takes a lot of time and effort, making it hard to manage big datasets. As the need for big data increases, this challenge becomes more noticeable.
Cost: Paying annotators, particularly those with expert knowledge, can be costly and may raise project costs. This cost limitation can make it hard to carry out large marking projects.
Subjectivity: Personal opinions can cause different people to label things inconsistently, which can lower the quality of the data. Even with clear rules, people may understand things differently, which can lead to differences in the data.
Large Language Model (LLM) Annotation
Data annotation has been revolutionized by Large Language Models (LLMs), which automate the tagging process. Models such as GPT-4, Claude 3, and Gemini Ultra are capable of producing human-like text by generating annotations at scale and using huge amounts of data.
Evolution
Rule-Based Systems: Annotation tools in the past were quite rigid and dependent on a set of predetermined rules and patterns. The complexity and diversity of natural language presented challenges for these systems.
Generative AI: Large language models (LLMs) generate precise annotations by understanding the context. They generate these annotations effectively using complex structures and extensive training data. In contrast to rule-based systems, LLMs are highly adaptable and efficient, as they can manage a variety of annotation tasks with minimal or no human intervention. The "LLM-as-Judge" approach includes the use of LLMs to assess and rank text outputs according to predetermined criteria, such as tone, clarity, or relevance. This method decreases the dependence on human evaluators by allowing LLMs to evaluate responses in accordance with predetermined standards.
Technical Backbone
Architectures Based on Transformers:LLMs uses transformer architectures, which employ self-attention mechanisms to evaluate the relationships between words in a text. This method allows the model to understand the significance and context of each word, resulting in accurate annotations. Transformer-based models ensure that annotations are both dependable and understandable by efficiently managing text data.
Training and Fine-Tuning: The alignment of LLMs with human judgments requires the training of these models on a variety of high-quality data that is representative of human decision-making. Models are able to understand human preferences by being exposed to a diverse array of scenarios and responses. The model is further improved for certain annotation tasks by fine-tuning, ensuring that it can execute specialized activities with accuracy equal to that of a person.
Few-Shot Learning: In the past, models were required to be fine-tuned to accommodate specific annotation tasks. Modern LLMs are very good at zero-shot and few-shot learning, which means they can do labeling tasks with little or no extra training. The annotation process has been simplified by this capability, resulting in increased efficiency without sacrificing quality.
Prompt engineering: LLMs are able to produce precise annotations by creating prompts that are both detailed and specific. Users can direct the model to generate appropriate and relevant outputs by meticulously designing inputs. This clarity guarantees consistency across a variety of tasks and maintains the intended standards in annotations. The process of guiding LLMs toward human-like assessments requires the creation of stimuli that are both clear and precise. Prompts that are well-designed establish explicit expectations and provide context, which allows the model to generate responses that are consistent with human reasoning. For example, the specification "Evaluate the clarity and relevance of this response according to the provided guidelines" instructs the model to concentrate on the desired aspects, resulting in outputs that closely resemble human evaluations.
By including these methods, LLMs can efficiently oversee annotation tasks, guaranteeing that the outputs are consistent, accurate, and by human standards.
Use Cases
Classification of Text: LLMs can automatically classify text into predetermined categories, doing things like recognizing spam emails or categorizing news items according to their subject matter.
Sentiment Analysis: Analyzing the tone of a piece of text allows LLMs to do sentiment analysis and determine if it is good, negative, or neutral. The analysis of the market, the evaluation of client feedback, and the monitoring of social media all benefit from this resource.
Code Annotation: LLMs can help with software documentation by creating comments or explanations for code snippets. This improves code quality, cooperation, and developers' ability to comprehend and manage codebases.
So, we have seen "LLM-as-Judge" approach has improved data annotation for Large Language Models (LLMs). However, both LLMs and human annotators have different strengths and limitations. LLMs have the advantages of consistency and scalability, but they may also be biased and lack complex understanding. Human annotators provide deep contextual insights but may face challenges in scaling and accuracy.
Technical Comparison: Human vs. LLM Annotation
1. Accuracy and Consistency
It is important to evaluate the consistency and accuracy of data annotation techniques in order to construct reliable AI systems. This evaluation ensures that the annotations are reliable and follow the necessary guidelines. The primary metrics employed for this objective are as follows:
Metrics for Evaluation
F1 Score: A single metric that integrates precision and recall, providing an in-depth evaluation of a model's accuracy. It is especially beneficial for datasets with an irregular distribution of data.
Cohen's Kappa: Evaluates the degree of agreement between annotators while considering the influence of chance. It provides a more dependable evaluation than a straightforward percentage agreement.
Frameworks for Adversarial Testing: Bring in misleading or difficult data pieces to see how well annotation approaches hold up. One such example is Anti-CARLA, which assesses the effectiveness of annotators or models in managing complex scenarios.
Comparing LLMs and Human Annotators
Human annotators and Large Language Models (LLMs) possess distinct advantages and disadvantages when it comes to data annotation.
Large Language Models (LLMs)
High Consistency: LLMs ensure uniformity in annotations by employing identical labeling criteria across extensive datasets. This stability is important for keeping quality high in large projects.
Vulnerability to Hallucinations: LLMs can generate reasonable but inaccurate details when presented with ambiguous information or limited data. These "hallucinations" have the potential to undermine the content of the annotations.
Human Annotators
Nuanced Understanding: Humans are exceptional at tasks that require profound comprehension, such as the identification of sarcasm in text or the interpretation of medical images. In complex scenarios, their capacity to understand context and subtleties results in more precise annotations.
Variability Among Annotators: Personal biases, fatigue, or varying interpretations of guidelines can result in variations in human annotations. This variability can lead to inconsistencies, which can compromise the data's overall reliability.
In short, LLMs are very reliable. Human annotators offer deeper insights, but their work may lead to differences in results. Using the right measurement methods is important to evaluate and improve the performance of both marking methods.
2. Scalability and Cost Efficiency
It's important to evaluate the scale and cost-effectiveness when comparing human annotation to methods that use Large Language Models (LLMs).
LLMs:
Scalability: LLMs can handle large amounts of data at the same time, making them very scalable. For example, in sentiment analysis tasks, LLMs can quickly label large amounts of text with positive, negative, or neutral sentiments. This ensures annotations are consistent and accurate across the dataset.
Cost Efficiency: Substantial computational resources are required for the initial development and training of LLMs; however, once deployed, they can execute annotation tasks at a reduced marginal cost per unit of data. This speed is especially helpful for big projects.
Humans
Scalability Challenges: Human annotation frequently encounters major scalability challenges, particularly when dealing with enormous datasets. Annotating sensor data for self-driving cars means marking a lot of information, which takes a lot of time and effort.
Cost Considerations: The financial consequences of human annotation are substantial. Tasks like picture bounding box annotation cost approximately less, while more complicated tasks like semantic segmentation can cost more. These costs add up fast with big datasets.
In short, LLMs are better at handling big annotation jobs because they can grow easily and are cheaper. Human annotation is more accurate in some cases, but it is harder to scale and more expensive.
Now we will be discussing hybrid solutions (LLMs + Humans)
3. Balancing LLMs and Human Efforts
It is possible to achieve more efficient data annotation processes by integrating the capabilities of human annotators and LLMs. Although Large Language Models (LLMs) are capable of efficiently managing huge amounts of data, understanding their decision-making processes can be a difficult task. These models are frequently referred to as "black boxes" by researchers due to the difficulty in determining the process by which they arrive at specific conclusions. This opacity complicates the process of predicting the timing and cause of their potential errors.
On the other hand, human annotators produce evaluations that are considerably more transparent. They have the ability to express their explanations, which enables others to understand the reasoning behind their decisions. The importance of this clarity cannot be overstated, particularly in domains where it is critical to understand the reasoning behind a choice. Monitoring and enhancing the performance of both human annotators and LLMs is possible through the use of evaluation metrics such as Cohen's Kappa and F1 Score. This ensures that your AI systems receive high-quality annotations.
Incorporating Feedback Loops
A crucial component of any continuous improvement strategy should be the implementation of feedback loops that allow human input to refine LLM outcomes. Humans can assist the LLM in adjusting its responses to more closely align with human judgments by conducting regular reviews of the model's performance and providing corrective feedback. This iterative process includes the assessment of the model's outputs, the identification of discrepancies between the model's judgments and human expectations, and the necessary updates to the model. Regular updates that are based on performance evaluations guarantee that the LLM remains consistent with human judgments over time, adapting to new information and evolving standards.
It is important that we include human feedback in order to refine Large Language Models (LLMs). The alignment of LLM outputs with human expectations is made easier by regular evaluations and corrective inputs. This procedure includes the evaluation of model performance, the identification of discrepancies, and the subsequent updating of the model.
Future AGI provides tools that enable the seamless integration of human feedback into LLM evaluations and annotations. Their platform facilitates continuous development by allowing users to establish custom metrics and automate error detection. Organizations can maintain their LLMs accurate and in line with human evaluations over time by using these characteristics.
When to Choose LLMs Over Humans for Annotations
In data annotation, the decision to use Large Language Models (LLMs) or human annotators is dependent upon a variety of factors. LLMs provide cost-effective solutions, ensure consistent labeling, and handle large volumes of data. Even so, the task's nature and the availability of resources are also critical factors in this decision-making process.
Here is a detailed comparison between human annotators and Large Language Models (LLMs) for data labeling tasks:
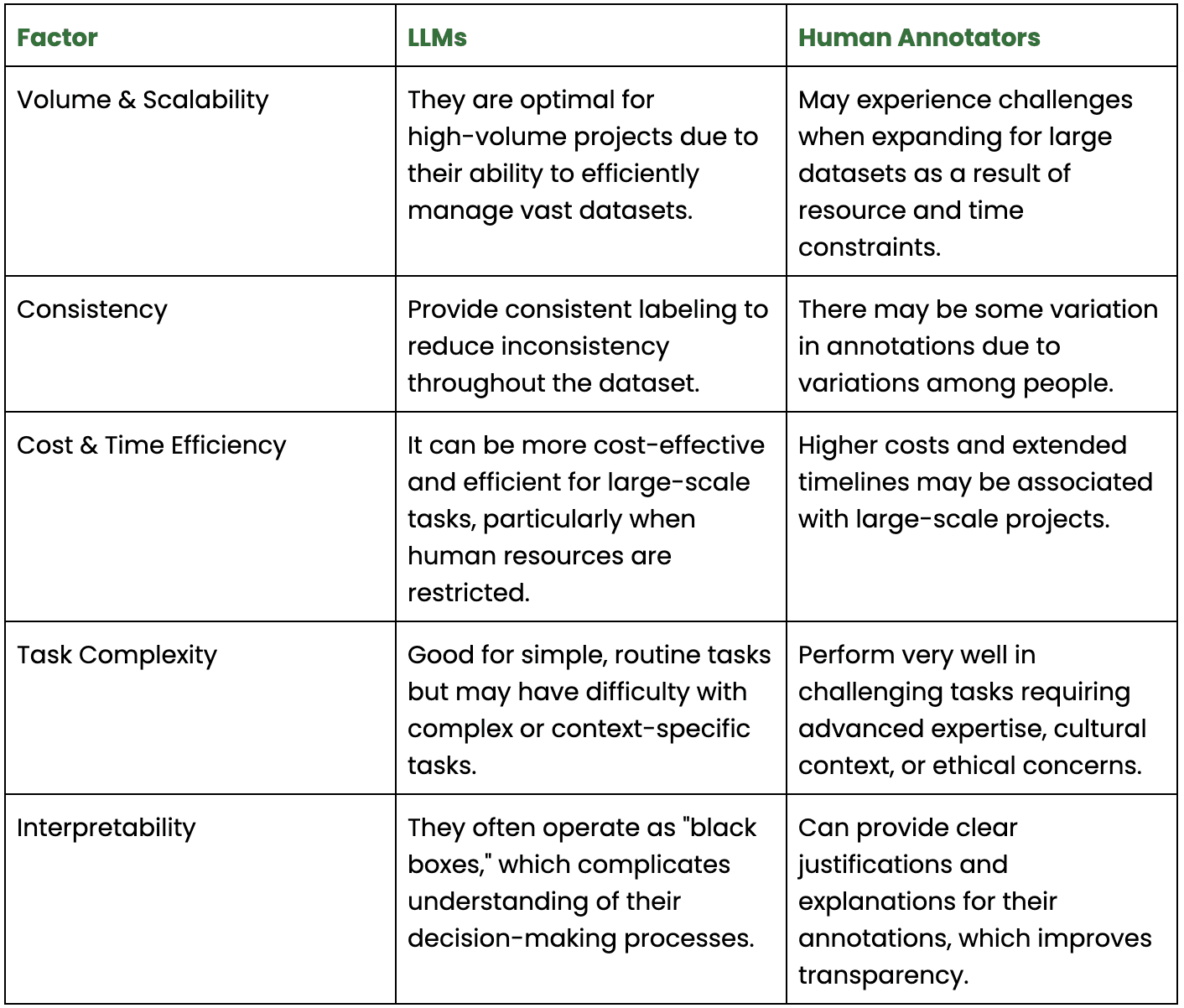
By looking at these factors, you can decide when to use LLMs for annotation tasks, improving both the speed and quality of your projects.
Conclusion
Large Language Models (LLMs) and human annotators each provide unique benefits in the context of data annotation. LLMs are well-suited for high-volume duties due to their ability to rapidly process large datasets and ensure consistent labeling. Even so, they can run into challenges when faced with complex contexts or specialized knowledge, which require human insight. Human annotators are great at understanding obscure meanings and cultural references, which helps them be accurate in complicated situations.
Using LLMs to evaluate and assess text outputs, the "LLM-as-a-Judge" approach aims to replicate human decision-making processes. This approach can improve the consistency and scalability of evaluations.
More By
Rishav Hada




