


Introduction
Retrieval-Augmented Generation (RAG) has emerged as a groundbreaking innovation in natural language processing (NLP), enabling systems to combine retrieval-based and generative techniques for more effective and accurate results. This hybrid approach addresses complex queries by leveraging vast external data sources during generation. However, building efficient RAG systems hinges on the availability of high-quality datasets—a persistent challenge due to the cost, availability, and domain-specific requirements of real-world data. Synthetic datasets are proving to be a transformative solution, addressing data scarcity and amplifying model performance in unprecedented ways.
What is Retrieval-Augmented Generation (RAG)?
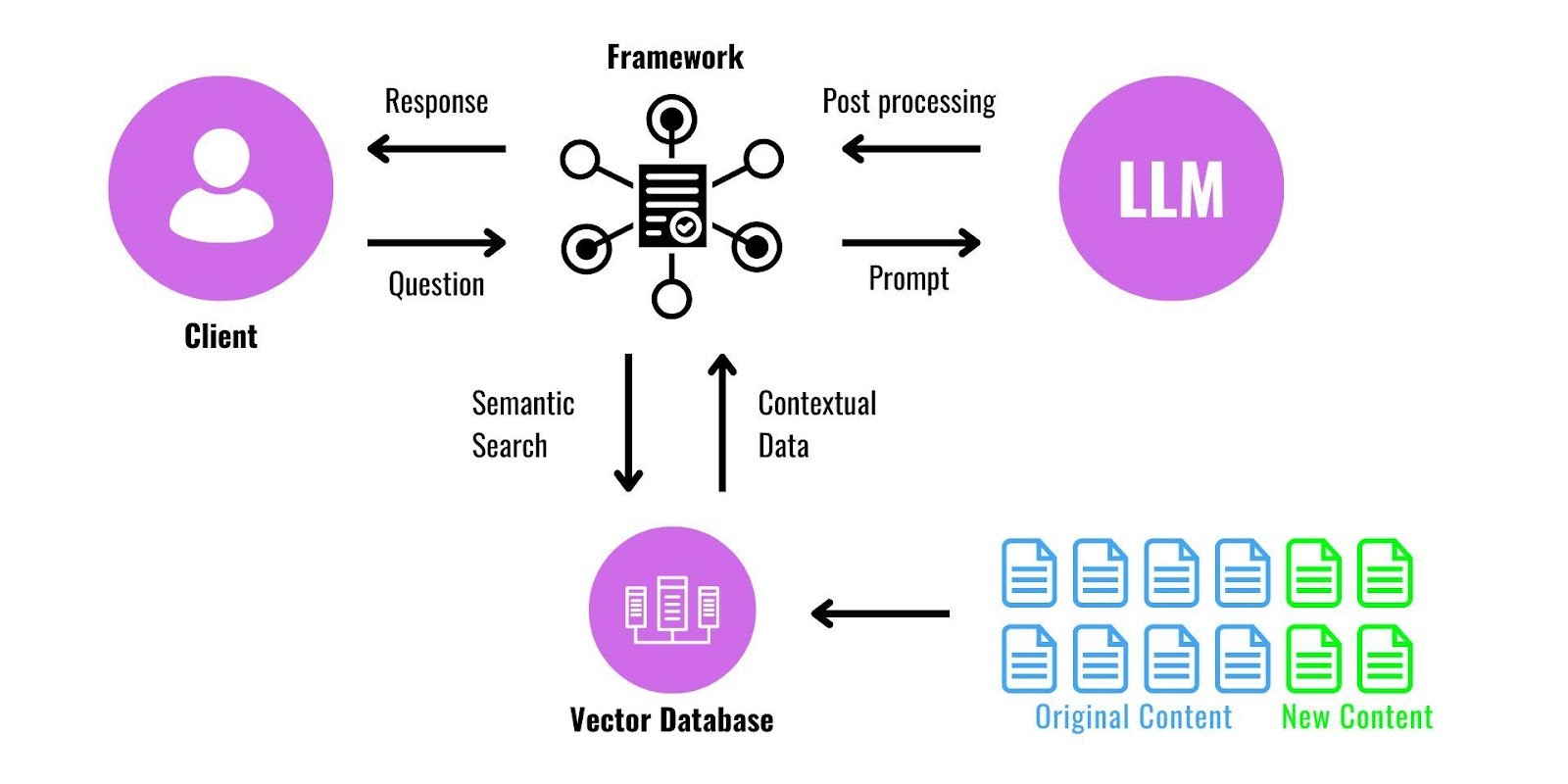
RAG Architecture Overview
Retrieval-Augmented Generation integrates two powerful components:
Retrieval Mechanism: Extracts relevant documents or data from external sources based on user input.
Generative Model: Produces responses by synthesizing retrieved information with contextual understanding.
This architecture excels in scenarios demanding contextually rich and precise answers, such as multi-turn conversations, technical question answering, and real-time knowledge updates.
Applications of Retrieval-Augmented Generation (RAG)
Customer Support
RAG systems empower customer service by delivering accurate, context-aware responses. By tapping into domain-specific knowledge bases, these systems can resolve complex inquiries that require nuanced understanding. For example, a telecom provider's RAG-powered chatbot can troubleshoot technical issues by retrieving and generating step-by-step solutions, offering faster and more reliable assistance to users.
Document Summarization
With information overload being a significant challenge, RAG excels in condensing lengthy documents into concise, meaningful summaries. Whether summarizing legal contracts, research papers, or business reports, RAG systems ensure critical insights are preserved. For instance, a researcher can input a dense journal article, and the RAG model extracts key findings and methodologies for easy comprehension.
Educational Tools
RAG enhances learning experiences by providing precise, query-specific answers tailored to students’ needs. A learner studying astrophysics, for example, could ask the system to explain "gravitational waves" and receive a well-rounded, easy-to-understand explanation, complete with references to academic resources. This adaptability makes RAG a dynamic tool for personalized education.
Why Synthetic Datasets Matter for RAG
Limitations of Real-World Datasets
Scarcity: Limited Availability for Niche Domains
Real-world datasets are often hard to find for specialized fields like legal, medical, or technical domains. For example, training a Retrieval-Augmented Generation (RAG) system for analyzing pharmaceutical research might require datasets that simply don’t exist or are locked behind proprietary systems.
High Costs: Time and Resources Needed for Labeling and Curation
Preparing real-world data involves manual annotation, cleaning, and verification, which are both expensive and time-intensive. Creating a dataset for even a moderately complex domain could take months, requiring expert oversight and significant financial investment.
Biases: Domain-Specific Challenges That Hinder Generalization
Real-world datasets often reflect inherent biases, such as regional, cultural, or demographic imbalances. These biases can negatively impact a RAG model’s ability to generalize across diverse user queries, resulting in inconsistent or inaccurate outputs.
Advantages of Synthetic Datasets
Customizability: Tailored to Specific Tasks or Industries
Synthetic datasets offer unparalleled flexibility. Need data for customer support in the fintech sector? You can generate it to match the exact terminology, scenarios, and edge cases of that industry. This ensures the RAG system is laser-focused on solving domain-specific challenges.
Scalability: Enabling the Training of Large-Scale Models Without Constraints
Unlike real-world datasets that may require months of collection and labeling, synthetic datasets can be generated in hours at scale. This allows researchers to train and fine-tune massive RAG models without being limited by data shortages.
Reduced Labeling Dependency: Generating Meaningful Content Without Extensive Manual Intervention
With synthetic datasets, manual labeling becomes less critical. Pretrained generative models can automatically produce high-quality data, such as retrieval-generation pairs, ensuring that RAG systems are trained on diverse and meaningful content without requiring exhaustive human input.
Methods for Generating Synthetic Datasets
1. Data Augmentation
Data augmentation involves applying transformations to existing datasets to create more diverse and enriched training data.
Techniques: Methods like paraphrasing, synonym replacement, and back-translation generate new variations of the original data while preserving its meaning. For instance, a sentence can be rephrased or translated into another language and back, offering fresh perspectives.
Workflow: Start with a well-curated real-world dataset. Apply augmentation techniques iteratively, ensuring the transformed data aligns with the intended context. Finally, validate the augmented data through automated checks or manual reviews to maintain relevance and accuracy.
Data augmentation helps models generalize better by introducing variability into training examples.
2. Generative Models
Generative models leverage the power of advanced AI tools to create entirely new datasets from scratch.
Pretrained Models: Pretrained models like GPT and T5 are instrumental in generating synthetic datasets. These models produce high-quality retrieval-generation pairs that mimic real-world scenarios, ideal for RAG training.
Prompt Engineering: Crafting effective prompts ensures that the generated data meets contextual and diversity requirements. For example, specifying a domain or query type can result in tailored synthetic entries that align closely with the task at hand.
Generative models are particularly effective for creating large-scale, realistic datasets in domains where real data is scarce.
3. Rule-Based Methods
Rule-based methods use predefined rules and templates to generate synthetic datasets, offering structure and precision.
Domain-Specific Rules: In specialized fields like legal or medical AI, templates and predefined structures allow for the generation of domain-specific datasets. For instance, templates for medical records can simulate patient data without breaching privacy.
Pros and Cons: These datasets are precise and controlled, making them ideal for certain use cases. However, they may lack the adaptability and diversity provided by generative models, limiting their ability to generalize across broader scenarios.
Rule-based methods work best when exact patterns or structures are needed in the training data.
4. Combining Real and Synthetic Data
Blending real-world and synthetic data creates a balanced and comprehensive dataset for robust model training.
Transfer Learning: Start with real data to pre-train the model, capturing foundational knowledge. Then, fine-tune the model with synthetic data to enhance performance in specific domains or tasks.
Balanced Mixing: Carefully combine real and synthetic datasets, ensuring they complement each other. Over-reliance on synthetic data can introduce biases, so maintaining balance is key to achieving optimal results.
This approach leverages the strengths of both dataset types, improving the model’s accuracy and robustness.
Challenges and Best Practices
1. Quality Assurance
Noise Mitigation: Synthetic datasets can often include irrelevant or biased information that reduces their effectiveness. Employ advanced filtering techniques such as outlier detection and automatic content validation to identify and remove such data. Leveraging AI tools for preprocessing can significantly enhance dataset quality.
Human Validation: While automation plays a crucial role, incorporating domain experts in the validation loop ensures the data is not just clean but contextually accurate. Experts can provide nuanced insights into the relevance and correctness of the content, especially for specialized fields like healthcare or law.
2. Maintaining Domain Relevance
Domain Adaptation: Synthetic datasets must align with the intended application. Fine-tuning pre-trained models with domain-specific data ensures the generated content is relevant and actionable. For example, fine-tuning a medical language model with synthetic clinical records improves its diagnostic utility.
Contextual Consistency: The generated data must meet the expectations of the end-user in terms of language, style, and context. Employ post-generation validation processes to verify the alignment of the synthetic data with real-world scenarios. This step is especially critical for applications like legal document generation or customer support automation.
3. Evaluating Dataset Effectiveness
Key Metrics: Metrics such as precision, recall, and F1 scores are essential to assess the dataset's ability to improve model performance. These metrics provide a balanced view of how well the synthetic data supports both accuracy and coverage in training tasks.
Model Comparisons: Conduct experiments to compare the performance of models trained on synthetic, real, and blended datasets. For example, evaluate a RAG system's ability to answer domain-specific queries before and after training with synthetic data. This iterative process helps fine-tune dataset characteristics for maximum impact.
Case Studies and Examples
Real-World Applications
Customer Service Bots: Enhanced Response Accuracy through Tailored Synthetic Data
Synthetic datasets allow customer service bots to train on domain-specific conversations, enabling them to generate more accurate and context-aware responses. For instance, bots in e-commerce can simulate various customer queries, such as product returns or troubleshooting, improving their ability to resolve issues efficiently. This approach reduces reliance on vast real-world data while ensuring bots remain adaptable to evolving customer needs.
Medical NLP Models: Improved Diagnostic Explanations Using Synthetic Datasets Mimicking Clinical Interactions
Synthetic datasets crafted to emulate clinical conversations help medical NLP models deliver more nuanced and precise diagnostic explanations. By simulating patient-doctor dialogues or annotating synthetic case studies, these datasets ensure models are better equipped to provide actionable insights, aiding healthcare professionals in making informed decisions.
Tools and Resources
Popular Tools
Hugging Face Transformers: For Dataset Augmentation and Synthetic Data Generation
Hugging Face’s suite of transformers provides a robust framework for augmenting existing datasets or creating new synthetic data. By fine-tuning models like BERT or GPT, users can produce contextually relevant data tailored to their specific applications, ensuring high-quality inputs for Retrieval-Augmented Generation (RAG) systems.
OpenAI API: Flexible Generative Capabilities for Synthetic Content Creation
The OpenAI API offers an accessible platform to generate synthetic datasets with precision. By designing prompts that guide the generative process, developers can create diverse and scalable data suitable for applications like question answering, document summarization, and more.
Data Sources
WikiData and Common Crawl: Rich Repositories to Support Synthetic Dataset Generation: WikiData provides a structured, open-source knowledge base ideal for generating retrieval-oriented synthetic datasets. Meanwhile, Common Crawl offers an extensive archive of web data, enabling the extraction of diverse text samples to simulate real-world use cases. These resources form a strong foundation for building datasets tailored to various NLP challenges.
How FutureAGI Revolutionizes Synthetic Data Generation for RAG
Future AGI offers a cutting-edge platform for generating high-quality synthetic datasets, empowering organizations to build robust Retrieval-Augmented Generation (RAG) systems with unparalleled efficiency and precision. With its intuitive and customizable approach, Future AGI bridges the gap between data scarcity and the demand for domain-specific datasets. Users can simply define their data requirements or provide us with a few examples and we scale it to thousands.
Key benefits include:
Customizability: Generate datasets precisely aligned with user-defined parameters, reducing manual dataset preparation time by up to 80%.
Iterative Refinement: Automatically evaluate and improve data quality through semantic diversity and distribution checks, increasing dataset accuracy by 30-40% on average.
Scalability: Produce large-scale datasets quickly, reducing operational costs by 70% compared to manual labeling.
We empower organizations to overcome data scarcity and build robust RAG systems with diverse, high-quality synthetic data.
Similar Blogs


