
Senior Applied Scientist
Share:

Introduction
Embedding models have revolutionised AI by enabling computers to understand complex data patterns. According to Gartner research, more than 30% of large companies will use massive language models (LLMs) for various purposes by 2026. This statistic highlights how crucial embeddings are becoming in AI applications.
Machine learning models as embeddings help one to work with complex data by translating it into reasonable numerical representations. This development influences search engines showing relevant results, recommendation systems providing tailored content, sentiment analysis determining what people are saying, and language translation simplifying cross-cultural communication. With embeddings, AI-driven solutions record the relevant core of data and thus operate faster and more precisely.
From fundamental co-occurrence matrices, embedding techniques have evolved into sophisticated high-dimensional and contextual models. Major innovations are distributed models, transformer-based architectures, and domain-specific pretraining techniques. These advances have made AI far more capable in understanding and producing human-like language. This helps one to make more sensible and convenient use of technology
Types of Embedding Models
Changes in how computers understand language resulting from embedding models have produced search engines, ranking systems, and tools translating languages. Discover the several types of embedding models as well as their historical developments.
Static Word Embeddings
Word2Vec: With vast amounts of data, the Google-made Word2Vec tool learns how words are connected using neural networks to create vector representations showing these semantic connections.
GloVe: GloVe creates word embeddings combining the best features of local context window techniques created at Stanford and global matrix factorisation.
FastText: Designed by Facebook's AI Research team, FastText improves Word2Vec by adding subword data, thus producing embeddings for rare or not-common words.
Limitations
Though they only serve to show how words connect semantically, these models give each word an exact vector representation independent of the context. Their low capacity makes the management of polysemy challenging.
For example, the word "bank" would have the same embedding whether it was used to refer to a bank or a financial company, so complicating language processing tasks.
Contextual Word Embeddings
ELMo: Using bidirectional LSTM networks, Language Models (ELMo) create word representations by considering the complete phrase context of a word.
BERT: Bidirectional Encoder Representations from Transformers (BERT) uses transformer designs to create context-dependent embeddings, which assist in better understanding word meaning by looking at the text around it.
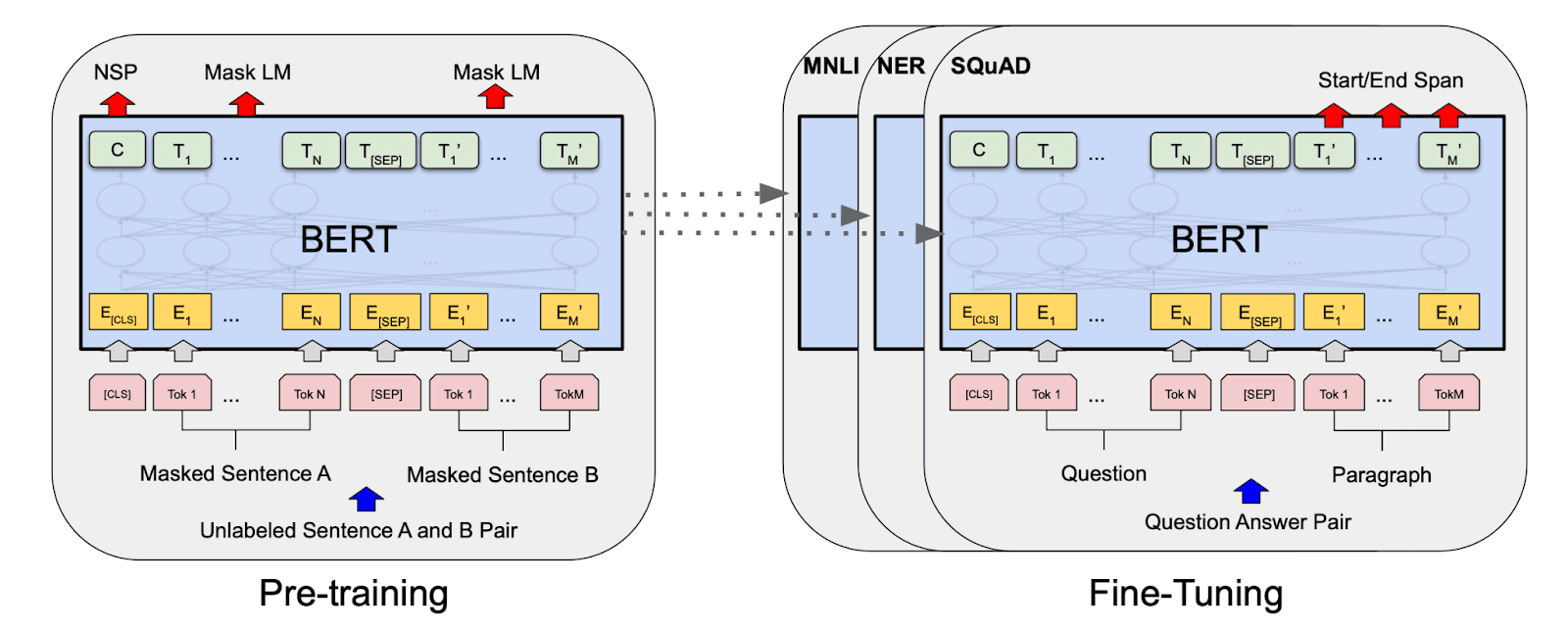
Figure 1: BERT architecture: Source
Mechanisms:
These models use self-attention techniques to ascertain the importance of a word in a particular sentence, so they include embeddings that could adapt in reaction to new information. This approach effectively manages polysemy and raises the model's capacity to identify complex linguistic patterns.
Sentence-Level and Document-Level Embeddings
Universal Sentence Encoder (USE): Google created the Universal Sentence Encoder (USE), which turns sentences into high-dimensional vectors that make jobs like finding related words and groups of text easier.
SBERT: Sentence-BERT changes the BERT design to create sentence embeddings that make sense from a semantic perspective. This update makes tasks like semantic textual similarity and clustering more accurate.
InferSent: It is a Facebook model that can be used for various downstream applications; it delivers phrase embeddings that have been trained on data from natural language inference.
Architectural Differences and Performance:
Additionally, USE uses transformer designs that are fast and accurate at encoding sentences, SBERT tweaks BERT to work better with sentence similarity tasks, and InferSent uses BiLSTM that was trained on labelled data. Evaluations have shown that SBERT's fine-tuning method provides improved performance on tasks like document clustering and paraphrase recognition.
Universal Text Embedding Models
E5: A set of models that learn from big datasets to provide general embeddings for different types of text and work well in various situations.
BGE: Models were made to create embeddings that work well in various jobs and areas, furthering progress in creating universal text representations.
NV-Embed: The NVIDIA NV-Embed model uses big language models to make high-quality embeddings that can be used in many situations.
Capabilities and Optimization:
Large-scale standards like the Massive Text Embedding Benchmark (MTEB) are used to teach these models to do many things at once, like retrieval, classification, and clustering. They offer strong and efficient text representations and are useful in many AI applications due to their adaptability.
Core Architecture and Techniques in Modern Embedding Models
Encoder-Decoder
Encoder-heavy models such as BERT obtain rich contextual representations using deep bidirectional encoders; lightweight decoders handle some tasks farther down the line. This approach makes sure that embeddings are correct by focusing on quickly making outputs and understanding the context in both ways.
Self-Attention Mechanism
Self-attention finds global connections by giving each input token a relevance score. This feature improves parallelisation and long-term context knowledge. It avoids vanishing gradients, unlike RNNs and LSTMs, by modelling distant word connections directly.
Pretraining Objectives
Embeddings can have more environmental detail with the help of primary objectives like Masked Language Modelling (MLM) and Next Sentence Prediction (NSP). For large-scale benchmarks, modern methods like cross-encoder pretraining and contrastive learning improve task-specific representations.
Architectural Impacts
Leading embedding models, such as E5, BGE, and NV-Embed, have unique architectural traits that affect how well they do in several different measures.
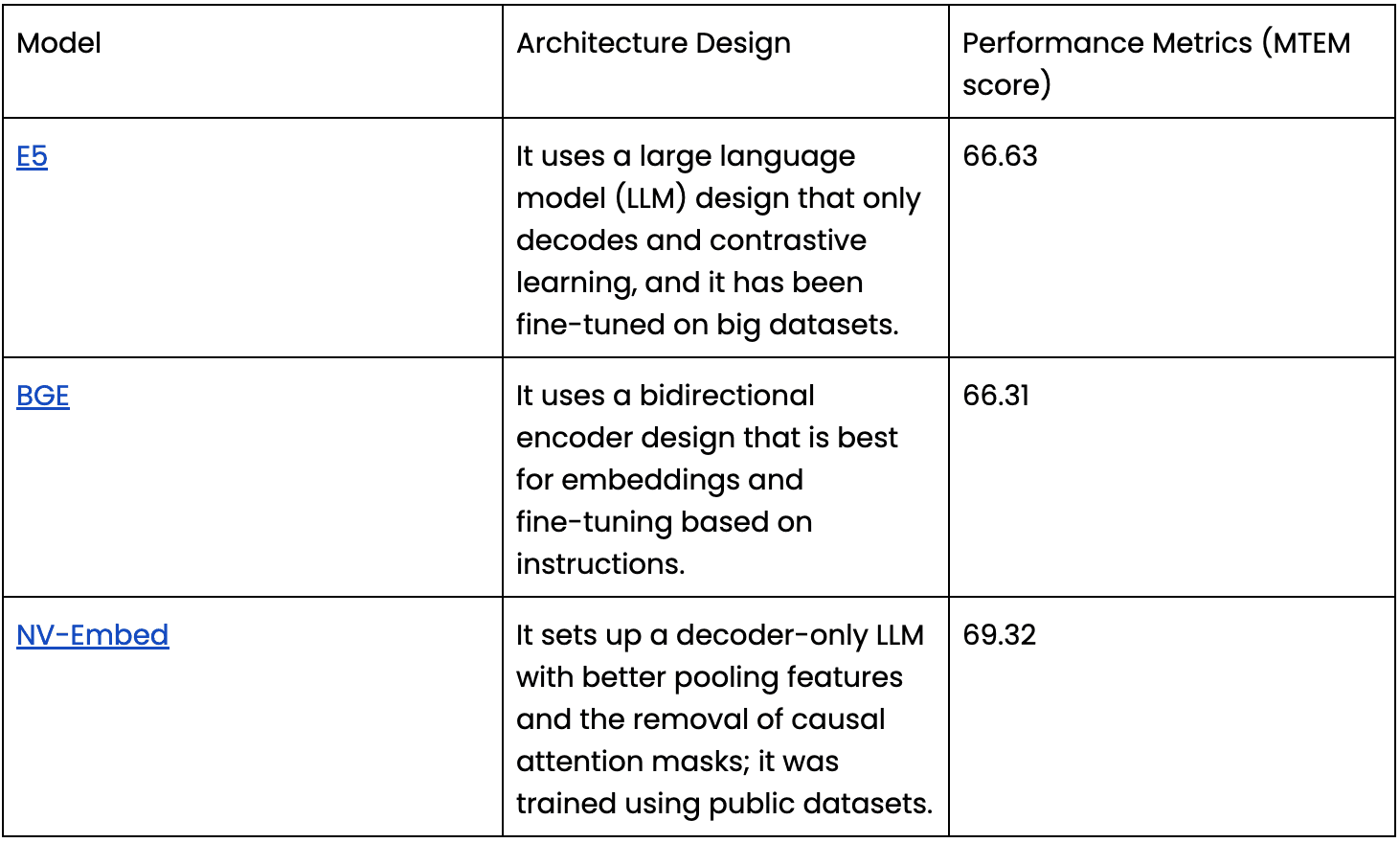
These design choices present trade-offs in terms of scaling, latency, and generalisation. For example, NV-Embed's design does better on the Massive Text Embedding Benchmark (MTEB) with a score of 69.32, which means it can do better at a wider range of jobs. But because its design is more complicated, it may have more delay than models like BGE that are simpler.
Model Efficiency and Optimization
A number of metrics, including model size, inference speed, and memory utilization, can be used to assess the efficiency of a model. These are improved using optimization methods such as knowledge distillation and pruning.
Knowledge Distillation: This method instructs a smaller model, known as the "teacher", to behave like a larger model. The approach cuts down on model size and reasoning time while keeping performance the same.
Pruning: This method removes factors or structures from a model that aren't relevant over time. Such removal makes the model simpler and less resource-intensive. When paired with information distillation, pruning can greatly reduce the size of a model and make it work better.
Integration with Large Language Models (LLMs)
Large Language Models (LLMs) such as GPT-4 and Llama 3 are now essential for making high-quality embeddings for many natural language processing jobs. These models take in text and turn it into dense vector representations that hold semantic information. Such an approach makes tasks like text classification, mood analysis, and information retrieval faster and better.
LLMs are distinguished by their proficiency in both zero-shot and few-shot learning paradigms. In zero-shot learning, models do tasks based only on descriptions, without any specific training beforehand. For example, GPT-4 can sort text by figuring out what an instruction prompt means without having to look at written samples.
Few-shot learning is when you give the model a small set of cases to help it figure out how to do a task. This method lets LLMs change to new jobs with little data, so they don't need to be fine-tuned as much. LLMs are useful tools in current AI applications because they can generate advanced embeddings and learn in various ways.
Conclusion
By 2025, embedding models will have come a long way, bringing with them optimization techniques and innovative designs that boost efficiency in all kinds of AI apps. Thoroughly assessing task-specific needs, scalability, and ethical issues is necessary for selecting the proper model. Examples of models that are well-suited to many applications are SFR-Embedding-Mistral and GriLM-7B, which show high generalization across multiple tasks. Since no model is perfect in every way, it is essential to determine if it fits your use case requirements. Responsible AI deployment also requires checking that the selected model obeys all applicable laws and ethical principles. By carefully thinking about these things, professionals can use embedding models to their fullest potential to drive innovation while staying responsible.
It's important to carefully test the performance of your AI applications to make sure they use the best embedding models. Future AGI gives you a strong evaluation system that lets you test models using different measures and datasets, which helps you make smart choices about your AI solutions. Visit Future AGI Evaluate and look at the evaluation tools.
More By
Rishav Hada




